
In computing, a database is an organized collection of data or a type of data store based on the use of a database management system (DBMS), the software that interacts with end users, applications, and the database itself to capture and analyze the data. The DBMS additionally encompasses the core facilities provided to administer the database. The sum total of the database, the DBMS and the associated applications can be referred to as a database system. Often the term "database" is also used loosely to refer to any of the DBMS, the database system or an application associated with the database.
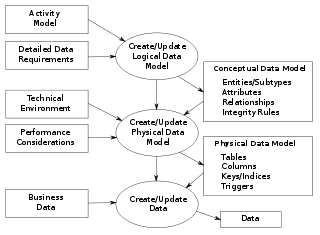
A conceptual schema or conceptual data model is a high-level description of informational needs underlying the design of a database. It typically includes only the core concepts and the main relationships among them. This is a high-level model with insufficient detail to build a complete, functional database. It describes the structure of the whole database for a group of users. The conceptual model is also known as the data model that can be used to describe the conceptual schema when a database system is implemented. It hides the internal details of physical storage and targets the description of entities, datatypes, relationships and constraints.
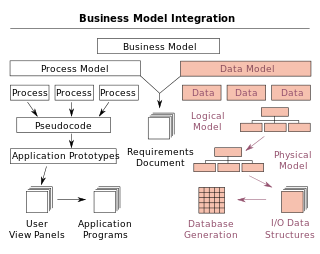
A data model is an abstract model that organizes elements of data and standardizes how they relate to one another and to the properties of real-world entities. For instance, a data model may specify that the data element representing a car be composed of a number of other elements which, in turn, represent the color and size of the car and define its owner.

The database schema is the structure of a database described in a formal language supported typically by a relational database management system (RDBMS). The term "schema" refers to the organization of data as a blueprint of how the database is constructed. The formal definition of a database schema is a set of formulas (sentences) called integrity constraints imposed on a database. These integrity constraints ensure compatibility between parts of the schema. All constraints are expressible in the same language. A database can be considered a structure in realization of the database language. The states of a created conceptual schema are transformed into an explicit mapping, the database schema. This describes how real-world entities are modeled in the database.

An entity–relationship model describes interrelated things of interest in a specific domain of knowledge. A basic ER model is composed of entity types and specifies relationships that can exist between entities.
Data modeling in software engineering is the process of creating a data model for an information system by applying certain formal techniques. It may be applied as part of broader Model-driven engineering (MDE) concept.

Object–role modeling (ORM) is used to model the semantics of a universe of discourse. ORM is often used for data modeling and software engineering.
A logical data model or logical schema is a data model of a specific problem domain expressed independently of a particular database management product or storage technology but in terms of data structures such as relational tables and columns, object-oriented classes, or XML tags. This is as opposed to a conceptual data model, which describes the semantics of an organization without reference to technology.
A physical data model is a representation of a data design as implemented, or intended to be implemented, in a database management system. In the lifecycle of a project it typically derives from a logical data model, though it may be reverse-engineered from a given database implementation. A complete physical data model will include all the database artifacts required to create relationships between tables or to achieve performance goals, such as indexes, constraint definitions, linking tables, partitioned tables or clusters. Analysts can usually use a physical data model to calculate storage estimates; it may include specific storage allocation details for a given database system.
Object–relational impedance mismatch is a set of difficulties going between data in relational data stores and data in domain-driven object models. Relational Database Management Systems (RDBMS) is the standard method for storing data in a dedicated database, while object-oriented (OO) programming is the default method for business-centric design in programming languages. The problem lies in neither relational databases nor OO programming, but in the conceptual difficulty mapping between the two logic models. Both logical models are differently implementable using database servers, programming languages, design patterns, or other technologies. Issues range from application to enterprise scale, whenever stored relational data is used in domain-driven object models, and vice versa. Object-oriented data stores can trade this problem for other implementation difficulties.

Integration DEFinition for information modeling (IDEF1X) is a data modeling language for the development of semantic data models. IDEF1X is used to produce a graphical information model which represents the structure and semantics of information within an environment or system.
An entity–attribute–value model (EAV) is a data model optimized for the space-efficient storage of sparse—or ad-hoc—property or data values, intended for situations where runtime usage patterns are arbitrary, subject to user variation, or otherwise unforeseeable using a fixed design. The use-case targets applications which offer a large or rich system of defined property types, which are in turn appropriate to a wide set of entities, but where typically only a small, specific selection of these are instantiated for a given entity. Therefore, this type of data model relates to the mathematical notion of a sparse matrix. EAV is also known as object–attribute–value model, vertical database model, and open schema.
Dimensional modeling (DM) is part of the Business Dimensional Lifecycle methodology developed by Ralph Kimball which includes a set of methods, techniques and concepts for use in data warehouse design. The approach focuses on identifying the key business processes within a business and modelling and implementing these first before adding additional business processes, as a bottom-up approach. An alternative approach from Inmon advocates a top down design of the model of all the enterprise data using tools such as entity-relationship modeling (ER).
ER/Studio is data architecture and database design software developed by IDERA, Inc. ER/Studio is compatible with multiple database platforms and is used to create and manage database designs, as well as to document and reuse data assets. In 2015, Embarcadero Technologies was acquired by database and infrastructure management software company IDERA, Inc. Since the acquisition by IDERA, Inc., ER/Studio has been renamed to ER/Studio Data Architect with updated features.
A database model is a type of data model that determines the logical structure of a database. It fundamentally determines in which manner data can be stored, organized and manipulated. The most popular example of a database model is the relational model, which uses a table-based format.
Entity Framework (EF) is an open source object–relational mapping (ORM) framework for ADO.NET. It was originally shipped as an integral part of .NET Framework, however starting with Entity Framework version 6.0 it has been delivered separately from the .NET Framework.
A document-oriented database, or document store, is a computer program and data storage system designed for storing, retrieving and managing document-oriented information, also known as semi-structured data.

Core architecture data model (CADM) in enterprise architecture is a logical data model of information used to describe and build architectures.
A graph database (GDB) is a database that uses graph structures for semantic queries with nodes, edges, and properties to represent and store data. A key concept of the system is the graph. The graph relates the data items in the store to a collection of nodes and edges, the edges representing the relationships between the nodes. The relationships allow data in the store to be linked together directly and, in many cases, retrieved with one operation. Graph databases hold the relationships between data as a priority. Querying relationships is fast because they are perpetually stored in the database. Relationships can be intuitively visualized using graph databases, making them useful for heavily inter-connected data.
The following is provided as an overview of and topical guide to databases:
