Related Research Articles
Scalability is the property of a system to handle a growing amount of work. One definition for software systems specifies that this may be done by adding resources to the system.
A logical partition (LPAR) is a subset of a computer's hardware resources, virtualized as a separate computer. In effect, a physical machine can be partitioned into multiple logical partitions, each hosting a separate instance of an operating system.
Software multitenancy is a software architecture in which a single instance of software runs on a server and serves multiple tenants. Systems designed in such manner are "shared". A tenant is a group of users who share a common access with specific privileges to the software instance. With a multitenant architecture, a software application is designed to provide every tenant a dedicated share of the instance - including its data, configuration, user management, tenant individual functionality and non-functional properties. Multitenancy contrasts with multi-instance architectures, where separate software instances operate on behalf of different tenants.
GPFS is high-performance clustered file system software developed by IBM. It can be deployed in shared-disk or shared-nothing distributed parallel modes, or a combination of these. It is used by many of the world's largest commercial companies, as well as some of the supercomputers on the Top 500 List. For example, it is the filesystem of the Summit at Oak Ridge National Laboratory which was the #1 fastest supercomputer in the world in the November 2019 Top 500 List. Summit is a 200 Petaflops system composed of more than 9,000 POWER9 processors and 27,000 NVIDIA Volta GPUs. The storage filesystem called Alpine has 250 PB of storage using Spectrum Scale on IBM ESS storage hardware, capable of approximately 2.5 TB/s of sequential I/O and 2.2 TB/s of random I/O.
The IBM SAN Volume Controller (SVC) is a block storage virtualization appliance that belongs to the IBM System Storage product family. SVC implements an indirection, or "virtualization", layer in a Fibre Channel storage area network (SAN).
A grid file system is a computer file system whose goal is improved reliability and availability by taking advantage of many smaller file storage areas.
Desktop virtualization is a software technology that separates the desktop environment and associated application software from the physical client device that is used to access it.
SAP IQ is a column-based, petabyte scale, relational database software system used for business intelligence, data warehousing, and data marts. Produced by Sybase Inc., now an SAP company, its primary function is to analyze large amounts of data in a low-cost, highly available environment. SAP IQ is often credited with pioneering the commercialization of column-store technology.
oVirt is a free, open-source virtualization management platform. It was founded by Red Hat as a community project on which Red Hat Virtualization is based. It allows centralized management of virtual machines, compute, storage and networking resources, from an easy-to-use web-based front-end with platform independent access. KVM on x86-64, PowerPC64 and s390x architecture are the only hypervisors supported, but there is an ongoing effort to support ARM architecture in a future releases.
In computing, virtualization or virtualisation in British English is the act of creating a virtual version of something at the same abstraction level, including virtual computer hardware platforms, storage devices, and computer network resources.
A database shard, or simply a shard, is a horizontal partition of data in a database or search engine. Each shard is held on a separate database server instance, to spread load.
Cloud computing is the on-demand availability of computer system resources, especially data storage and computing power, without direct active management by the user. Large clouds often have functions distributed over multiple locations, each of which is a data center. Cloud computing relies on sharing of resources to achieve coherence and typically uses a pay-as-you-go model, which can help in reducing capital expenses but may also lead to unexpected operating expenses for users.
In computer science, memory virtualization decouples volatile random access memory (RAM) resources from individual systems in the data centre, and then aggregates those resources into a virtualized memory pool available to any computer in the cluster. The memory pool is accessed by the operating system or applications running on top of the operating system. The distributed memory pool can then be utilized as a high-speed cache, a messaging layer, or a large, shared memory resource for a CPU or a GPU application.
OpenNebula is an open source cloud computing platform for managing heterogeneous data center, public cloud and edge computing infrastructure resources. OpenNebula manages on-premises and remote virtual infrastructure to build private, public, or hybrid implementations of Infrastructure as a Service and multi-tenant Kubernetes deployments. The two primary uses of the OpenNebula platform are data center virtualization and cloud deployments based on the KVM hypervisor, LXD/LXC system containers, and AWS Firecracker microVMs. The platform is also capable of offering the cloud infrastructure necessary to operate a cloud on top of existing VMware infrastructure. In early June 2020, OpenNebula announced the release of a new Enterprise Edition for corporate users, along with a Community Edition. OpenNebula CE is free and open-source software, released under the Apache License version 2. OpenNebula CE comes with free access to patch releases containing critical bug fixes but with no access to the regular EE maintenance releases. Upgrades to the latest minor/major version is only available for CE users with non-commercial deployments or with significant open source contributions to the OpenNebula Community. OpenNebula EE is distributed under a closed-source license and requires a commercial Subscription.
Data-intensive computing is a class of parallel computing applications which use a data parallel approach to process large volumes of data typically terabytes or petabytes in size and typically referred to as big data. Computing applications that devote most of their execution time to computational requirements are deemed compute-intensive, whereas applications are deemed data-intensive require large volumes of data and devote most of their processing time to I/O and manipulation of data.

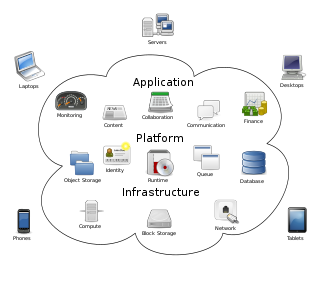
Cloud computing architecture refers to the components and subcomponents required for cloud computing. These components typically consist of a front end platform, back end platforms, a cloud based delivery, and a network. Combined, these components make up cloud computing architecture.
Software-defined storage (SDS) is a marketing term for computer data storage software for policy-based provisioning and management of data storage independent of the underlying hardware. Software-defined storage typically includes a form of storage virtualization to separate the storage hardware from the software that manages it. The software enabling a software-defined storage environment may also provide policy management for features such as data deduplication, replication, thin provisioning, snapshots and backup.
In computer networking, a bare-metal server is a physical computer server that is used by one consumer, or tenant, only. Each server offered for rental is a distinct physical piece of hardware that is a functional server on its own. They are not virtual servers running in multiple pieces of shared hardware.
ONTAP or Data ONTAP or Clustered Data ONTAP (cDOT) or Data ONTAP 7-Mode is NetApp's proprietary operating system used in storage disk arrays such as NetApp FAS and AFF, ONTAP Select, and Cloud Volumes ONTAP. With the release of version 9.0, NetApp decided to simplify the Data ONTAP name and removed the word "Data" from it, removed the 7-Mode image, therefore, ONTAP 9 is the successor of Clustered Data ONTAP 8.
5G network slicing is a network architecture that enables the multiplexing of virtualized and independent logical networks on the same physical network infrastructure. Each network slice is an isolated end-to-end network tailored to fulfill diverse requirements requested by a particular application.
References
| Main | |
|---|---|
| Languages | |
| Security | |
| Design |
|
| Programming | |
| Management | |
| Lists of | |
| See also | |