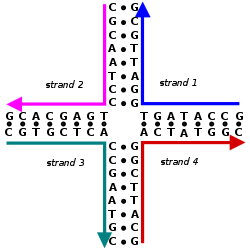
Nucleic acid design can be used to create nucleic acid complexes with complicated secondary structures such as this four-arm junction. These four strands associate into this structure because it maximizes the number of correct base pairs, with A's matched to T's and C's matched to G's. Image from Mao, 2004.
Nucleic acid design is the process of generating a set of nucleic acid base sequences that will associate into a desired conformation. Nucleic acid design is central to the fields of DNA nanotechnology and DNA computing.[2] It is necessary because there are many possible sequences of nucleic acid strands that will fold into a given secondary structure, but many of these sequences will have undesired additional interactions which must be avoided. In addition, there are many tertiary structure considerations which affect the choice of a secondary structure for a given design.[3][4]
Nucleic acid design has similar goals to protein design: in both, the sequence of monomers is rationally designed to favor the desired folded or associated structure and to disfavor alternate structures. However, nucleic acid design has the advantage of being a much computationally simpler problem, since the simplicity of Watson-Crick base pairing rules leads to simple heuristic methods which yield experimentally robust designs. Computational models for protein folding require tertiary structure information whereas nucleic acid design can operate largely on the level of secondary structure. However, nucleic acid structures are less versatile than proteins in their functionality.[2][5]
Nucleic acid design can be considered the inverse of nucleic acid structure prediction. In structure prediction, the structure is determined from a known sequence, while in nucleic acid design, a sequence is generated which will form a desired structure.[2]
Fundamental concepts
Chemical structure of DNA. Nucleic acid double helices will only form between two strands of complementary sequences, where the bases are matched into only A-T or G-C pairs.
The structure of nucleic acids consists of a sequence of nucleotides. There are four types of nucleotides distinguished by which of the four nucleobases they contain: in DNA these are adenine (A), cytosine (C), guanine (G), and thymine (T). Nucleic acids have the property that two molecules will bind to each other to form a double helix only if the two sequences are complementary, that is, they can form matching sequences of base pairs. Thus, in nucleic acids the sequence determines the pattern of binding and thus the overall structure.[5]
Nucleic acid design is the process by which, given a desired target structure or functionality, sequences are generated for nucleic acid strands which will self-assemble into that target structure. Nucleic acid design encompasses all levels of nucleic acid structure:
Secondary structure—the set of interactions between bases, i.e., which parts of which strands are bound to each other; and
Tertiary structure—the locations of the atoms in three-dimensional space, taking into consideration geometrical and steric constraints.
One of the greatest concerns in nucleic acid design is ensuring that the target structure has the lowest free energy (i.e. is the most thermodynamically favorable) whereas misformed structures have higher values of free energy and are thus unfavored.[2] These goals can be achieved through the use of a number of approaches, including heuristic, thermodynamic, and geometrical ones. Almost all nucleic acid design tasks are aided by computers, and a number of software packages are available for many of these tasks.
Two considerations in nucleic acid design are that desired hybridizations should have melting temperatures in a narrow range, and any spurious interactions should have very low melting temperatures (i.e. they should be very weak).[5] There is also a contrast between affinity-optimizing "positive design", seeks to minimize the energy of the desired structure in an absolute sense, and specificity-optimizing "negative design", which considers the energy of the target structure relative to those of undesired structures. Algorithms which implement both kinds of design tend to perform better than those that consider only one type.[2]
Approaches
Heuristic methods
Heuristic methods use simple criteria which can be quickly evaluated to judge the suitability of different sequences for a given secondary structure. They have the advantage of being much less computationally expensive than the energy minimization algorithms needed for thermodynamic or geometrical modeling, and being easier to implement, but at the cost of being less rigorous than these models.
Sequence symmetry minimization is the oldest approach to nucleic acid design and was first used to design immobile versions of branched DNA structures. Sequence symmetry minimization divides the nucleic acid sequence into overlapping subsequences of a fixed length, called the criterion length. Each of the 4N possible subsequences of length N is allowed to appear only once in the sequence. This ensures that no undesired hybridizations can occur which have a length greater than or equal to the criterion length.[2][3]
A related heuristic approach is to consider the "mismatch distance", meaning the number of positions in a certain frame where the bases are not complementary. A greater mismatch distance lessens the chance that a strong spurious interaction can happen.[5] This is related to the concept of Hamming distance in information theory. Another related but more involved approach is to use methods from coding theory to construct nucleic acid sequences with desired properties.
Information about the secondary structure of a nucleic acid complex along with its sequence can be used to predict the thermodynamic properties of the complex.
When thermodynamic models are used in nucleic acid design, there are usually two considerations: desired hybridizations should have melting temperatures in a narrow range, and any spurious interactions should have very low melting temperatures (i.e. they should be very weak). The Gibbs free energy of a perfectly matched nucleic acid duplex can be predicted using a nearest neighbor model. This model considers only the interactions between a nucleotide and its nearest neighbors on the nucleic acid strand, by summing the free energy of each of the overlapping two-nucleotide subwords of the duplex. This is then corrected for self-complementary monomers and for GC-content. Once the free energy is known, the melting temperature of the duplex can be determined. GC-content alone can also be used to estimate the free energy and melting temperature of a nucleic acid duplex. This is less accurate but also much less computationally costly.[5]
A related approach, inverse secondary structure prediction, uses stochastic local search which improves a nucleic acid sequence by running a structure prediction algorithm and the modifying the sequence to eliminate unwanted features.[5]
Geometrical models
A geometrical model of a DNA tetrahedron described in Goodman, 2005. Models of this type are useful for ensuring that tertiary structure constraints do not cause excessive strain to the molecule.
Geometrical models of nucleic acids are used to predict tertiary structure. This is important because designed nucleic acid complexes usually contain multiple junction points, which introduces geometric constraints to the system. These constraints stem from the basic structure of nucleic acids, mainly that the double helix formed by nucleic acid duplexes has a fixed helicity of about 10.4 base pairs per turn, and is relatively stiff. Because of these constraints, the nucleic acid complexes are sensitive to the relative orientation of the major and minor grooves at junction points. Geometrical modeling can detect strain stemming from misalignments in the structure, which can then be corrected by the designer.[4][11]
Geometric models of nucleic acids for DNA nanotechnology generally use reduced representations of the nucleic acid, because simulating every atom would be very computationally expensive for such large systems. Models with three pseudo-atoms per base pair, representing the two backbone sugars and the helix axis, have been reported to have a sufficient level of detail to predict experimental results.[11] However, models with five pseudo-atoms per base pair, explicitly including the backbone phosphates, are also used.[12]
Software for geometrical modeling of nucleic acids includes GIDEON,[11]Tiamat,[13]Nanoengineer-1, and UNIQUIMER 3D.[14] Geometrical concerns are especially of interest in the design of DNA origami, because the sequence is predetermined by the choice of scaffold strand. Software specifically for DNA origami design has been made, including caDNAno[15] and SARSE.[16]
Applications
Nucleic acid design is used in DNA nanotechnology to design strands which will self-assemble into a desired target structure. These include examples such as DNA machines, periodic two- and three-dimensional lattices, polyhedra, and DNA origami.[2] It can also be used to create sets of nucleic acid strands which are "orthogonal", or non-interacting with each other, so as to minimize or eliminate spurious interactions. This is useful in DNA computing, as well as for molecular barcoding applications in chemical biology and biotechnology.[5]
Seeman, N (1982). "Nucleic acid junctions and lattices". Journal of Theoretical Biology. 99 (2): 237–47. Bibcode:1982JThBi..99..237S. doi:10.1016/0022-5193(82)90002-9. PMID6188926.—One of the earliest papers on nucleic acid design, describing the use of sequence symmetry minimization to construct immoble branched junctions.
Andersen, Ebbe Sloth (2010). "Prediction and design of DNA and RNA structures". New Biotechnology. 27 (3): 184–193. doi:10.1016/j.nbt.2010.02.012. PMID20193785.—A review comparing the capabilities of available nucleic acid design software.
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.