
Nucleic acid structure refers to the structure of nucleic acids such as DNA and RNA. Chemically speaking, DNA and RNA are very similar. Nucleic acid structure is often divided into four different levels: primary, secondary, tertiary, and quaternary.
Nucleic acid structure refers to the structure of nucleic acids such as DNA and RNA. Chemically speaking, DNA and RNA are very similar. Nucleic acid structure is often divided into four different levels: primary, secondary, tertiary, and quaternary.

Primary structure consists of a linear sequence of nucleotides that are linked together by phosphodiester bonds. It is this linear sequence of nucleotides that make up the primary structure of DNA or RNA. Nucleotides consist of 3 components:
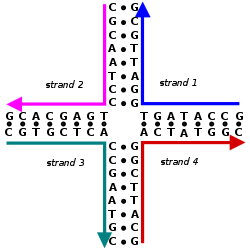
The nitrogen bases adenine and guanine are purine in structure and form a glycosidic bond between their 9 nitrogen and the 1' -OH group of the deoxyribose. Cytosine, thymine, and uracil are pyrimidines, hence the glycosidic bonds form between their 1 nitrogen and the 1' -OH of the deoxyribose. For both the purine and pyrimidine bases, the phosphate group forms a bond with the deoxyribose sugar through an ester bond between one of its negatively charged oxygen groups and the 5' -OH of the sugar. [2] The polarity in DNA and RNA is derived from the oxygen and nitrogen atoms in the backbone. Nucleic acids are formed when nucleotides come together through phosphodiester linkages between the 5' and 3' carbon atoms. [3] A nucleic acid sequence is the order of nucleotides within a DNA (GACT) or RNA (GACU) molecule that is determined by a series of letters. Sequences are presented from the 5' to 3' end and determine the covalent structure of the entire molecule. Sequences can be complementary to another sequence in that the base on each position is complementary as well as in the reverse order. An example of a complementary sequence to AGCT is TCGA. DNA is double-stranded containing both a sense strand and an antisense strand. Therefore, the complementary sequence will be to the sense strand. [4]
There are three potential metal binding groups on nucleic acids: phosphate, sugar, and base moieties. Solid-state structure of complexes with alkali metal ions have been reviewed. [6]
Secondary structure is the set of interactions between bases, i.e., which parts of strands are bound to each other. In DNA double helix, the two strands of DNA are held together by hydrogen bonds. The nucleotides on one strand base pairs with the nucleotide on the other strand. The secondary structure is responsible for the shape that the nucleic acid assumes. The bases in the DNA are classified as purines and pyrimidines. The purines are adenine and guanine. Purines consist of a double ring structure, a six-membered and a five-membered ring containing nitrogen. The pyrimidines are cytosine and thymine. It has a single ring structure, a six-membered ring containing nitrogen. A purine base always pairs with a pyrimidine base (guanine (G) pairs with cytosine (C) and adenine (A) pairs with thymine (T) or uracil (U)). DNA's secondary structure is predominantly determined by base-pairing of the two polynucleotide strands wrapped around each other to form a double helix. Although the two strands are aligned by hydrogen bonds in base pairs, the stronger forces holding the two strands together are stacking interactions between the bases. These stacking interactions are stabilized by Van der Waals forces and hydrophobic interactions, and show a large amount of local structural variability. [7] There are also two grooves in the double helix, which are called major groove and minor groove based on their relative size.

The secondary structure of RNA consists of a single polynucleotide. Base pairing in RNA occurs when RNA folds between complementarity regions. Both single- and double-stranded regions are often found in RNA molecules.
The four basic elements in the secondary structure of RNA are:
The antiparallel strands form a helical shape. [3] Bulges and internal loops are formed by separation of the double helical tract on either one strand (bulge) or on both strands (internal loops) by unpaired nucleotides.
Stem-loop or hairpin loop is the most common element of RNA secondary structure. [8] Stem-loop is formed when the RNA chains fold back on themselves to form a double helical tract called the 'stem', the unpaired nucleotides forms single stranded region called the 'loop'. A tetraloop is a four-base pairs hairpin RNA structure. There are three common families of tetraloop in ribosomal RNA: UNCG, GNRA, and CUUG (N is one of the four nucleotides and R is a purine). UNCG is the most stable tetraloop. [9]
Pseudoknot is an RNA secondary structure first identified in turnip yellow mosaic virus. [10] It is minimally composed of two helical segments connected by single-stranded regions or loops. H-type fold pseudoknots are best characterized. In H-type fold, nucleotides in the hairpin-loop pair with the bases outside the hairpin stem forming second stem and loop. This causes formation of pseudoknots with two stems and two loops. [11] Pseudoknots are functional elements in RNA structure having diverse function and found in most classes of RNA.
Secondary structure of RNA can be predicted by experimental data on the secondary structure elements, helices, loops, and bulges. DotKnot-PW method is used for comparative pseudoknots prediction. The main points in the DotKnot-PW method is scoring the similarities found in stems, secondary elements and H-type pseudoknots. [12]


Tertiary structure refers to the locations of the atoms in three-dimensional space, taking into consideration geometrical and steric constraints. It is a higher order than the secondary structure, in which large-scale folding in a linear polymer occurs and the entire chain is folded into a specific 3-dimensional shape. There are 4 areas in which the structural forms of DNA can differ.
The tertiary arrangement of DNA's double helix in space includes B-DNA, A-DNA, and Z-DNA. Triple-stranded DNA structures have been demonstrated in repetitive polypurine:polypyrimidine Microsatellite sequences and Satellite DNA.
B-DNA is the most common form of DNA in vivo and is a more narrow, elongated helix than A-DNA. Its wide major groove makes it more accessible to proteins. On the other hand, it has a narrow minor groove. B-DNA's favored conformations occur at high water concentrations; the hydration of the minor groove appears to favor B-DNA. B-DNA base pairs are nearly perpendicular to the helix axis. The sugar pucker which determines the shape of the a-helix, whether the helix will exist in the A-form or in the B-form, occurs at the C2'-endo. [13]
A-DNA, is a form of the DNA duplex observed under dehydrating conditions. It is shorter and wider than B-DNA. RNA adopts this double helical form, and RNA-DNA duplexes are mostly A-form, but B-form RNA-DNA duplexes have been observed. [14] In localized single strand dinucleotide contexts, RNA can also adopt the B-form without pairing to DNA. [15] A-DNA has a deep, narrow major groove which does not make it easily accessible to proteins. On the other hand, its wide, shallow minor groove makes it accessible to proteins but with lower information content than the major groove. Its favored conformation is at low water concentrations. A-DNAs base pairs are tilted relative to the helix axis, and are displaced from the axis. The sugar pucker occurs at the C3'-endo and in RNA 2'-OH inhibits C2'-endo conformation. [13] Long considered little more than a laboratory artifice, A-DNA is now known to have several biological functions.
Z-DNA is a relatively rare left-handed double-helix. Given the proper sequence and superhelical tension, it can be formed in vivo but its function is unclear. It has a more narrow, more elongated helix than A or B. Z-DNA's major groove is not really a groove, and it has a narrow minor groove. The most favored conformation occurs when there are high salt concentrations. There are some base substitutions but they require an alternating purine-pyrimidine sequence. The N2-amino of G H-bonds to 5' PO, which explains the slow exchange of protons and the need for the G purine. Z-DNA base pairs are nearly perpendicular to the helix axis. Z-DNA does not contain single base-pairs but rather a GpC repeat with P-P distances varying for GpC and CpG. On the GpC stack there is good base overlap, whereas on the CpG stack there is less overlap. Z-DNA's zigzag backbone is due to the C sugar conformation compensating for G glycosidic bond conformation. The conformation of G is syn, C2'-endo; for C it is anti, C3'-endo. [13]
A linear DNA molecule having free ends can rotate, to adjust to changes of various dynamic processes in the cell, by changing how many times the two chains of its double helix twist around each other. Some DNA molecules are circular and are topologically constrained. More recently circular RNA was described as well to be a natural pervasive class of nucleic acids, expressed in many organisms (see CircRNA).
A covalently closed, circular DNA (also known as cccDNA) is topologically constrained as the number of times the chains coiled around one other cannot change. This cccDNA can be supercoiled, which is the tertiary structure of DNA. Supercoiling is characterized by the linking number, twist and writhe. The linking number (Lk) for circular DNA is defined as the number of times one strand would have to pass through the other strand to completely separate the two strands. The linking number for circular DNA can only be changed by breaking of a covalent bond in one of the two strands. Always an integer, the linking number of a cccDNA is the sum of two components: twists (Tw) and writhes (Wr). [16]
Twists are the number of times the two strands of DNA are twisted around each other. Writhes are number of times the DNA helix crosses over itself. DNA in cells is negatively supercoiled and has the tendency to unwind. Hence the separation of strands is easier in negatively supercoiled DNA than in relaxed DNA. The two components of supercoiled DNA are solenoid and plectonemic. The plectonemic supercoil is found in prokaryotes, while the solenoidal supercoiling is mostly seen in eukaryotes.
The quaternary structure of nucleic acids is similar to that of protein quaternary structure. Although some of the concepts are not exactly the same, the quaternary structure refers to a higher-level of organization of nucleic acids. Moreover, it refers to interactions of the nucleic acids with other molecules. The most commonly seen form of higher-level organization of nucleic acids is seen in the form of chromatin which leads to its interactions with the small proteins histones. Also, the quaternary structure refers to the interactions between separate RNA units in the ribosome or spliceosome. [17]
{{cite book}}: |journal= ignored (help)