
In computing, a database is an organized collection of data or a type of data store based on the use of a database management system (DBMS), the software that interacts with end users, applications, and the database itself to capture and analyze the data. The DBMS additionally encompasses the core facilities provided to administer the database. The sum total of the database, the DBMS and the associated applications can be referred to as a database system. Often the term "database" is also used loosely to refer to any of the DBMS, the database system or an application associated with the database.
Denormalization is a strategy used on a previously-normalized database to increase performance. In computing, denormalization is the process of trying to improve the read performance of a database, at the expense of losing some write performance, by adding redundant copies of data or by grouping data. It is often motivated by performance or scalability in relational database software needing to carry out very large numbers of read operations. Denormalization differs from the unnormalized form in that denormalization benefits can only be fully realized on a data model that is otherwise normalized.
A relational database (RDB) is a database based on the relational model of data, as proposed by E. F. Codd in 1970. A database management system used to maintain relational databases is a relational database management system (RDBMS). Many relational database systems are equipped with the option of using SQL for querying and updating the database.
Structured Query Language (SQL) is a domain-specific language used to manage data, especially in a relational database management system (RDBMS). It is particularly useful in handling structured data, i.e., data incorporating relations among entities and variables.

An object–relational database (ORD), or object–relational database management system (ORDBMS), is a database management system (DBMS) similar to a relational database, but with an object-oriented database model: objects, classes and inheritance are directly supported in database schemas and in the query language. In addition, just as with pure relational systems, it supports extension of the data model with custom data types and methods.
First normal form (1NF) is a property of a relation in a relational database. A relation is in first normal form if and only if no attribute domain has relations as elements. Or more informally, that no table column can have tables as values. Database normalization is the process of representing a database in terms of relations in standard normal forms, where first normal is a minimal requirement. SQL-92 does not support creating or using table-valued columns, which means that using only the "traditional relational database features" most relational databases will be in first normal form by necessity. Database systems which do not require first normal form are often called NoSQL systems. Newer SQL standards like SQL:1999 have started to allow so called non-atomic types, which include composite types. Even newer versions like SQL:2016 allow JSON.
In database systems, isolation is one of the ACID transaction properties. It determines how transaction integrity is visible to other users and systems. A lower isolation level increases the ability of many users to access the same data at the same time, but also increases the number of concurrency effects users might encounter. Conversely, a higher isolation level reduces the types of concurrency effects that users may encounter, but requires more system resources and increases the chances that one transaction will block another.

In the context of SQL, data definition or data description language (DDL) is a syntax for creating and modifying database objects such as tables, indices, and users. DDL statements are similar to a computer programming language for defining data structures, especially database schemas. Common examples of DDL statements include CREATE, ALTER, and DROP. If you see a .ddl file, that means the file contains a statement to create a table. Oracle SQL Developer contains the ability to export from an ERD generated with Data Modeler to either a .sql file or a .ddl file.

A data dictionary, or metadata repository, as defined in the IBM Dictionary of Computing, is a "centralized repository of information about data such as meaning, relationships to other data, origin, usage, and format". Oracle defines it as a collection of tables with metadata. The term can have one of several closely related meanings pertaining to databases and database management systems (DBMS):
A database trigger is procedural code that is automatically executed in response to certain events on a particular table or view in a database. The trigger is mostly used for maintaining the integrity of the information on the database. For example, when a new record is added to the employees table, new records should also be created in the tables of the taxes, vacations and salaries. Triggers can also be used to log historical data, for example to keep track of employees' previous salaries.
The following tables compare general and technical information for a number of relational database management systems. Please see the individual products' articles for further information. Unless otherwise specified in footnotes, comparisons are based on the stable versions without any add-ons, extensions or external programs.
In a database, a table is a collection of related data organized in table format; consisting of columns and rows.
A query plan is a sequence of steps used to access data in a SQL relational database management system. This is a specific case of the relational model concept of access plans.
In computing, a materialized view is a database object that contains the results of a query. For example, it may be a local copy of data located remotely, or may be a subset of the rows and/or columns of a table or join result, or may be a summary using an aggregate function.
An entity–attribute–value model (EAV) is a data model optimized for the space-efficient storage of sparse—or ad-hoc—property or data values, intended for situations where runtime usage patterns are arbitrary, subject to user variation, or otherwise unforeseeable using a fixed design. The use-case targets applications which offer a large or rich system of defined property types, which are in turn appropriate to a wide set of entities, but where typically only a small, specific selection of these are instantiated for a given entity. Therefore, this type of data model relates to the mathematical notion of a sparse matrix. EAV is also known as object–attribute–value model, vertical database model, and open schema.
Apache Empire-db is a Java library that provides a high level object-oriented API for accessing relational database management systems (RDBMS) through JDBC. Apache Empire-db is open source and provided under the Apache License 2.0 from the Apache Software Foundation.
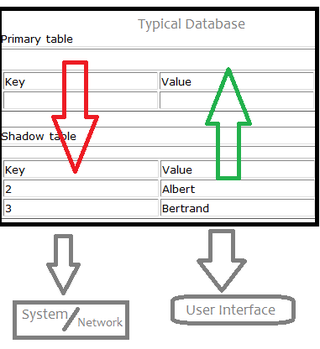
Shadow tables are objects in computer science used to improve the way machines, networks and programs handle information. More specifically, a shadow table is an object that is read and written by a processor and contains data similar to its primary table, which is the table it's "shadowing". Shadow tables usually contain data that is relevant to the operation and maintenance of its primary table, but not within the subset of data required for the primary table to exist. Shadow tables are related to the data type "trails" in data storage systems. Trails are very similar to shadow tables but instead of storing identically formatted information that is different, they store a history of modifications and functions operated on a table.
The following is provided as an overview of and topical guide to databases:

Oracle NoSQL Database is a NoSQL-type distributed key-value database from Oracle Corporation. It provides transactional semantics for data manipulation, horizontal scalability, and simple administration and monitoring.
The following outline is provided as an overview of and topical guide to MySQL: