In computer science, an array is a data structure consisting of a collection of elements, of same memory size, each identified by at least one array index or key. An array is stored such that the position of each element can be computed from its index tuple by a mathematical formula. The simplest type of data structure is a linear array, also called a one-dimensional array.
Database normalization is the process of structuring a relational database accordance with a series of so-called normal forms in order to reduce data redundancy and improve data integrity. It was first proposed by British computer scientist Edgar F. Codd as part of his relational model.
A relational database (RDB) is a database based on the relational model of data, as proposed by E. F. Codd in 1970.
The relational model (RM) is an approach to managing data using a structure and language consistent with first-order predicate logic, first described in 1969 by English computer scientist Edgar F. Codd, where all data is represented in terms of tuples, grouped into relations. A database organized in terms of the relational model is a relational database.
In database theory, relational algebra is a theory that uses algebraic structures for modeling data and defining queries on it with well founded semantics. The theory was introduced by Edgar F. Codd.
First normal form (1NF) is a property of a relation in a relational database. A relation is in first normal form if and only if no attribute domain has relations as elements. Or more informally, that no table column can have tables as values. Database normalization is the process of representing a database in terms of relations in standard normal forms, where first normal is a minimal requirement. SQL-92 does not support creating or using table-valued columns, which means that using only the "traditional relational database features" most relational databases will be in first normal form by necessity. Database systems which do not require first normal form are often called NoSQL systems. Newer SQL standards like SQL:1999 have started to allow so called non-atomic types, which include composite types. Even newer versions like SQL:2016 allow JSON.
In the relational model of databases, a primary key is a designated attribute (column) that can reliably identify and distinguish between each individual record in a table. The database creator can choose an existing unique attribute or combination of attributes from the table to act as its primary key, or create a new attribute containing a unique ID that exists solely for this purpose.
A foreign key is a set of attributes in a table that refers to the primary key of another table, linking these two tables. In the context of relational databases, a foreign key is subject to an inclusion dependency constraint that the tuples consisting of the foreign key attributes in one relation, R, must also exist in some other relation, S; furthermore that those attributes must also be a candidate key in S.
A surrogate key in a database is a unique identifier for either an entity in the modeled world or an object in the database. The surrogate key is not derived from application data, unlike a natural key.
In computer science, a record is a composite data structure – a collection of fields, possibly of different data types, typically fixed in number and sequence.

A flat-file database is a database stored in a file called a flat file. Records follow a uniform format, and there are no structures for indexing or recognizing relationships between records. The file is simple. A flat file can be a plain text file, or a binary file. Relationships can be inferred from the data in the database, but the database format itself does not make those relationships explicit.

A join clause in the Structured Query Language (SQL) combines columns from one or more tables into a new table. The operation corresponds to a join operation in relational algebra. Informally, a join stitches two tables and puts on the same row records with matching fields : INNER, LEFT OUTER, RIGHT OUTER, FULL OUTER and CROSS.
Database design is the organization of data according to a database model. The designer determines what data must be stored and how the data elements interrelate. With this information, they can begin to fit the data to the database model. A database management system manages the data accordingly.
In a relational database, a column is a set of data values of a particular type, one value for each row of a table. A column may contain text values, numbers, or even pointers to files in the operating system. Columns typically contain simple types, though some relational database systems allow columns to contain more complex data types, such as whole documents, images, or even video clips. A column can also be called an attribute.
In a database, a table is a collection of related data organized in table format; consisting of columns and rows.
A database index is a data structure that improves the speed of data retrieval operations on a database table at the cost of additional writes and storage space to maintain the index data structure. Indexes are used to quickly locate data without having to search every row in a database table every time said table is accessed. Indexes can be created using one or more columns of a database table, providing the basis for both rapid random lookups and efficient access of ordered records.
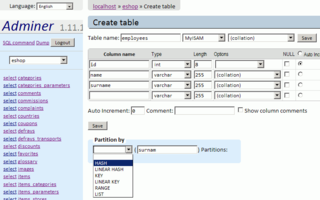
A partition is a division of a logical database or its constituent elements into distinct independent parts. Database partitioning is normally done for manageability, performance or availability reasons, or for load balancing. It is popular in distributed database management systems, where each partition may be spread over multiple nodes, with users at the node performing local transactions on the partition. This increases performance for sites that have regular transactions involving certain views of data, whilst maintaining availability and security.
In relational database management systems, a unique key is a candidate key. All the candidate keys of a relation can uniquely identify the records of the relation, but only one of them is used as the primary key of the relation. The remaining candidate keys are called unique keys because they can uniquely identify a record in a relation. Unique keys can consist of multiple columns. Unique keys are also called alternate keys. Unique keys are an alternative to the primary key of the relation. In SQL, the unique keys have a UNIQUE constraint assigned to them in order to prevent duplicates. Alternate keys may be used like the primary key when doing a single-table select or when filtering in a where clause, but are not typically used to join multiple tables.

A database model is a type of data model that determines the logical structure of a database. It fundamentally determines in which manner data can be stored, organized and manipulated. The most popular example of a database model is the relational model, which uses a table-based format.

In database theory, a relation, as originally defined by E. F. Codd, is a set of tuples (d1,d2,...,dn), where each element dj is a member of Dj, a data domain. Codd's original definition notwithstanding, and contrary to the usual definition in mathematics, there is no ordering to the elements of the tuples of a relation. Instead, each element is termed an attribute value. An attribute is a name paired with a domain. An attribute value is an attribute name paired with an element of that attribute's domain, and a tuple is a set of attribute values in which no two distinct elements have the same name. Thus, in some accounts, a tuple is described as a function, mapping names to values.