
In mathematics, the discrete Fourier transform (DFT) converts a finite sequence of equally-spaced samples of a function into a same-length sequence of equally-spaced samples of the discrete-time Fourier transform (DTFT), which is a complex-valued function of frequency. The interval at which the DTFT is sampled is the reciprocal of the duration of the input sequence. An inverse DFT (IDFT) is a Fourier series, using the DTFT samples as coefficients of complex sinusoids at the corresponding DTFT frequencies. It has the same sample-values as the original input sequence. The DFT is therefore said to be a frequency domain representation of the original input sequence. If the original sequence spans all the non-zero values of a function, its DTFT is continuous, and the DFT provides discrete samples of one cycle. If the original sequence is one cycle of a periodic function, the DFT provides all the non-zero values of one DTFT cycle.
In statistics, maximum likelihood estimation (MLE) is a method of estimating the parameters of an assumed probability distribution, given some observed data. This is achieved by maximizing a likelihood function so that, under the assumed statistical model, the observed data is most probable. The point in the parameter space that maximizes the likelihood function is called the maximum likelihood estimate. The logic of maximum likelihood is both intuitive and flexible, and as such the method has become a dominant means of statistical inference.
In mathematics, a self-adjoint operator on a complex vector space V with inner product is a linear map A that is its own adjoint. If V is finite-dimensional with a given orthonormal basis, this is equivalent to the condition that the matrix of A is a Hermitian matrix, i.e., equal to its conjugate transpose A∗. By the finite-dimensional spectral theorem, V has an orthonormal basis such that the matrix of A relative to this basis is a diagonal matrix with entries in the real numbers. This article deals with applying generalizations of this concept to operators on Hilbert spaces of arbitrary dimension.
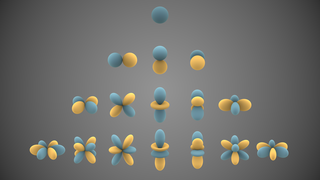
In mathematics and physical science, spherical harmonics are special functions defined on the surface of a sphere. They are often employed in solving partial differential equations in many scientific fields. The table of spherical harmonics contains a list of common spherical harmonics.
In mathematics, the classical orthogonal polynomials are the most widely used orthogonal polynomials: the Hermite polynomials, Laguerre polynomials, Jacobi polynomials.
In mathematics, the spectral radius of a square matrix is the maximum of the absolute values of its eigenvalues. More generally, the spectral radius of a bounded linear operator is the supremum of the absolute values of the elements of its spectrum. The spectral radius is often denoted by ρ(·).
The Lotka–Volterra equations, also known as the Lotka–Volterra predator–prey model, are a pair of first-order nonlinear differential equations, frequently used to describe the dynamics of biological systems in which two species interact, one as a predator and the other as prey. The populations change through time according to the pair of equations:
The effective population size (Ne) is the size of an idealised population that would experience the same rate of genetic drift as the real population. The effective population size is normally smaller than the census population size N, partly because chance events prevent some individuals from breeding, and partly due to background selection and genetic hitchhiking. Idealised populations are based on unrealistic but convenient assumptions including random mating, rarity of natural selection such that each gene evolves independently, and constant population size.
In probability theory and mathematical physics, a random matrix is a matrix-valued random variable—that is, a matrix in which some or all of its entries are sampled randomly from a probability distribution. Random matrix theory (RMT) is the study of properties of random matrices, often as they become large. RMT provides techniques like mean-field theory, diagrammatic methods, the cavity method, or the replica method to compute quantities like traces, spectral densities, or scalar products between eigenvectors. Many physical phenomena, such as the spectrum of nuclei of heavy atoms, the thermal conductivity of a lattice, or the emergence of quantum chaos, can be modeled mathematically as problems concerning large, random matrices.
In probability theory the hypoexponential distribution or the generalized Erlang distribution is a continuous distribution, that has found use in the same fields as the Erlang distribution, such as queueing theory, teletraffic engineering and more generally in stochastic processes. It is called the hypoexponetial distribution as it has a coefficient of variation less than one, compared to the hyper-exponential distribution which has coefficient of variation greater than one and the exponential distribution which has coefficient of variation of one.
In queueing theory, a discipline within the mathematical theory of probability, a Jackson network is a class of queueing network where the equilibrium distribution is particularly simple to compute as the network has a product-form solution. It was the first significant development in the theory of networks of queues, and generalising and applying the ideas of the theorem to search for similar product-form solutions in other networks has been the subject of much research, including ideas used in the development of the Internet. The networks were first identified by James R. Jackson and his paper was re-printed in the journal Management Science’s ‘Ten Most Influential Titles of Management Sciences First Fifty Years.’
Proportional hazards models are a class of survival models in statistics. Survival models relate the time that passes, before some event occurs, to one or more covariates that may be associated with that quantity of time. In a proportional hazards model, the unique effect of a unit increase in a covariate is multiplicative with respect to the hazard rate. The hazard rate at time is the probability per short time dt that an event will occur between and given that up to time no event has occurred yet. For example, taking a drug may halve one's hazard rate for a stroke occurring, or, changing the material from which a manufactured component is constructed, may double its hazard rate for failure. Other types of survival models such as accelerated failure time models do not exhibit proportional hazards. The accelerated failure time model describes a situation where the biological or mechanical life history of an event is accelerated.
Covariance matrix adaptation evolution strategy (CMA-ES) is a particular kind of strategy for numerical optimization. Evolution strategies (ES) are stochastic, derivative-free methods for numerical optimization of non-linear or non-convex continuous optimization problems. They belong to the class of evolutionary algorithms and evolutionary computation. An evolutionary algorithm is broadly based on the principle of biological evolution, namely the repeated interplay of variation and selection: in each generation (iteration) new individuals are generated by variation of the current parental individuals, usually in a stochastic way. Then, some individuals are selected to become the parents in the next generation based on their fitness or objective function value . Like this, individuals with better and better -values are generated over the generation sequence.
In population biology and demography, generation time is the average time between two consecutive generations in the lineages of a population. In human populations, generation time typically has ranged from 20 to 30 years, with wide variation based on gender and society. Historians sometimes use this to date events, by converting generations into years to obtain rough estimates of time.
In probability and statistics, the Tweedie distributions are a family of probability distributions which include the purely continuous normal, gamma and inverse Gaussian distributions, the purely discrete scaled Poisson distribution, and the class of compound Poisson–gamma distributions which have positive mass at zero, but are otherwise continuous. Tweedie distributions are a special case of exponential dispersion models and are often used as distributions for generalized linear models.

In probability theory and statistics, the Conway–Maxwell–Poisson distribution is a discrete probability distribution named after Richard W. Conway, William L. Maxwell, and Siméon Denis Poisson that generalizes the Poisson distribution by adding a parameter to model overdispersion and underdispersion. It is a member of the exponential family, has the Poisson distribution and geometric distribution as special cases and the Bernoulli distribution as a limiting case.
In mathematics, the spectral theory of ordinary differential equations is the part of spectral theory concerned with the determination of the spectrum and eigenfunction expansion associated with a linear ordinary differential equation. In his dissertation, Hermann Weyl generalized the classical Sturm–Liouville theory on a finite closed interval to second order differential operators with singularities at the endpoints of the interval, possibly semi-infinite or infinite. Unlike the classical case, the spectrum may no longer consist of just a countable set of eigenvalues, but may also contain a continuous part. In this case the eigenfunction expansion involves an integral over the continuous part with respect to a spectral measure, given by the Titchmarsh–Kodaira formula. The theory was put in its final simplified form for singular differential equations of even degree by Kodaira and others, using von Neumann's spectral theorem. It has had important applications in quantum mechanics, operator theory and harmonic analysis on semisimple Lie groups.
In the study of age-structured population growth, probably one of the most important equations is the Euler–Lotka equation. Based on the age demographic of females in the population and female births, this equation allows for an estimation of how a population is growing.

In probability theory and statistics, the Poisson distribution is a discrete probability distribution that expresses the probability of a given number of events occurring in a fixed interval of time if these events occur with a known constant mean rate and independently of the time since the last event. It can also be used for the number of events in other types of intervals than time, and in dimension greater than 1.

In the mathematical theory of random matrices, the Marchenko–Pastur distribution, or Marchenko–Pastur law, describes the asymptotic behavior of singular values of large rectangular random matrices. The theorem is named after soviet mathematicians Volodymyr Marchenko and Leonid Pastur who proved this result in 1967.







