Related Research Articles

Artificial neural networks (ANNs), usually simply called neural networks (NNs) or neural nets, are computing systems inspired by the biological neural networks that constitute animal brains.

In machine learning, the perceptron is an algorithm for supervised learning of binary classifiers. A binary classifier is a function which can decide whether or not an input, represented by a vector of numbers, belongs to some specific class. It is a type of linear classifier, i.e. a classification algorithm that makes its predictions based on a linear predictor function combining a set of weights with the feature vector.
An artificial neuron is a mathematical function conceived as a model of biological neurons, a neural network. Artificial neurons are elementary units in an artificial neural network. The artificial neuron receives one or more inputs and sums them to produce an output. Usually each input is separately weighted, and the sum is passed through a non-linear function known as an activation function or transfer function. The transfer functions usually have a sigmoid shape, but they may also take the form of other non-linear functions, piecewise linear functions, or step functions. They are also often monotonically increasing, continuous, differentiable and bounded. Non-monotonic, unbounded and oscillating activation functions with multiple zeros that outperform sigmoidal and ReLU like activation functions on many tasks have also been recently explored. The thresholding function has inspired building logic gates referred to as threshold logic; applicable to building logic circuits resembling brain processing. For example, new devices such as memristors have been extensively used to develop such logic in recent times.
Stochastic gradient descent is an iterative method for optimizing an objective function with suitable smoothness properties. It can be regarded as a stochastic approximation of gradient descent optimization, since it replaces the actual gradient by an estimate thereof. Especially in high-dimensional optimization problems this reduces the very high computational burden, achieving faster iterations in exchange for a lower convergence rate.
In machine learning, the delta rule is a gradient descent learning rule for updating the weights of the inputs to artificial neurons in a single-layer neural network. It is a special case of the more general backpropagation algorithm. For a neuron with activation function , the delta rule for neuron 's th weight is given by
In machine learning, backpropagation is a widely used algorithm for training feedforward artificial neural networks or other parameterized networks with differentiable nodes. It is an efficient application of the Leibniz chain rule (1673) to such networks. It is also known as the reverse mode of automatic differentiation or reverse accumulation, due to Seppo Linnainmaa (1970). The term "back-propagating errors" was introduced in 1962 by Frank Rosenblatt, but he did not know how to implement this, although Henry J. Kelley had a continuous precursor of backpropagation already in 1960 in the context of control theory.
A recurrent neural network (RNN) is a class of artificial neural networks where connections between nodes can create a cycle, allowing output from some nodes to affect subsequent input to the same nodes. This allows it to exhibit temporal dynamic behavior. Derived from feedforward neural networks, RNNs can use their internal state (memory) to process variable length sequences of inputs. This makes them applicable to tasks such as unsegmented, connected handwriting recognition or speech recognition. Recurrent neural networks are theoretically Turing complete and can run arbitrary programs to process arbitrary sequences of inputs.

A feedforward neural network (FNN) is an artificial neural network wherein connections between the nodes do not form a cycle. As such, it is different from its descendant: recurrent neural networks.
A multilayer perceptron (MLP) is a fully connected class of feedforward artificial neural network (ANN). The term MLP is used ambiguously, sometimes loosely to mean any feedforward ANN, sometimes strictly to refer to networks composed of multiple layers of perceptrons ; see § Terminology. Multilayer perceptrons are sometimes colloquially referred to as "vanilla" neural networks, especially when they have a single hidden layer.
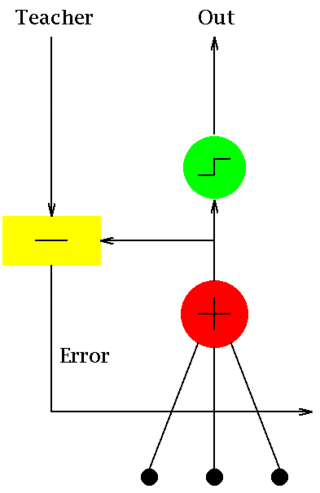
ADALINE is an early single-layer artificial neural network and the name of the physical device that implemented this network. The network uses memistors. It was developed by Professor Bernard Widrow and his doctoral student Ted Hoff at Stanford University in 1960. It is based on the McCulloch–Pitts neuron. It consists of a weight, a bias and a summation function.
In computer science, online machine learning is a method of machine learning in which data becomes available in a sequential order and is used to update the best predictor for future data at each step, as opposed to batch learning techniques which generate the best predictor by learning on the entire training data set at once. Online learning is a common technique used in areas of machine learning where it is computationally infeasible to train over the entire dataset, requiring the need of out-of-core algorithms. It is also used in situations where it is necessary for the algorithm to dynamically adapt to new patterns in the data, or when the data itself is generated as a function of time, e.g., stock price prediction. Online learning algorithms may be prone to catastrophic interference, a problem that can be addressed by incremental learning approaches.
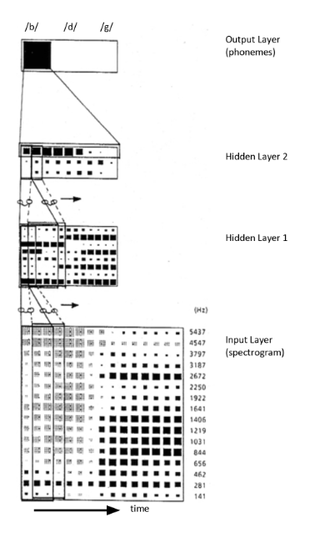
Time delay neural network (TDNN) is a multilayer artificial neural network architecture whose purpose is to 1) classify patterns with shift-invariance, and 2) model context at each layer of the network.

Encog is a machine learning framework available for Java and .Net. Encog supports different learning algorithms such as Bayesian Networks, Hidden Markov Models and Support Vector Machines. However, its main strength lies in its neural network algorithms. Encog contains classes to create a wide variety of networks, as well as support classes to normalize and process data for these neural networks. Encog trains using many different techniques. Multithreading is used to allow optimal training performance on multicore machines.
There are many types of artificial neural networks (ANN).

A restricted Boltzmann machine (RBM) is a generative stochastic artificial neural network that can learn a probability distribution over its set of inputs.
An artificial neural network's learning rule or learning process is a method, mathematical logic or algorithm which improves the network's performance and/or training time. Usually, this rule is applied repeatedly over the network. It is done by updating the weights and bias levels of a network when a network is simulated in a specific data environment. A learning rule may accept existing conditions of the network and will compare the expected result and actual result of the network to give new and improved values for weights and bias. Depending on the complexity of actual model being simulated, the learning rule of the network can be as simple as an XOR gate or mean squared error, or as complex as the result of a system of differential equations.
In machine learning, the vanishing gradient problem is encountered when training artificial neural networks with gradient-based learning methods and backpropagation. In such methods, during each iteration of training each of the neural network's weights receives an update proportional to the partial derivative of the error function with respect to the current weight. The problem is that in some cases, the gradient will be vanishingly small, effectively preventing the weight from changing its value. In the worst case, this may completely stop the neural network from further training. As one example of the problem cause, traditional activation functions such as the hyperbolic tangent function have gradients in the range (0,1], and backpropagation computes gradients by the chain rule. This has the effect of multiplying n of these small numbers to compute gradients of the early layers in an n-layer network, meaning that the gradient decreases exponentially with n while the early layers train very slowly.

A residual neural network (ResNet) is an artificial neural network (ANN). It is a gateless or open-gated variant of the HighwayNet, the first working very deep feedforward neural network with hundreds of layers, much deeper than previous neural networks. Skip connections or shortcuts are used to jump over some layers . Typical ResNet models are implemented with double- or triple- layer skips that contain nonlinearities (ReLU) and batch normalization in between. Models with several parallel skips are referred to as DenseNets. In the context of residual neural networks, a non-residual network may be described as a plain network.
In machine learning and statistics, the learning rate is a tuning parameter in an optimization algorithm that determines the step size at each iteration while moving toward a minimum of a loss function. Since it influences to what extent newly acquired information overrides old information, it metaphorically represents the speed at which a machine learning model "learns". In the adaptive control literature, the learning rate is commonly referred to as gain.
References
- ↑ Martin Riedmiller und Heinrich Braun: Rprop - A Fast Adaptive Learning Algorithm. Proceedings of the International Symposium on Computer and Information Science VII, 1992
- ↑ https://towardsdatascience.com/understanding-rmsprop-faster-neural-network-learning-62e116fcf29a
- 1 2 Christian Igel and Michael Hüsken. Improving the Rprop Learning Algorithm. Second International Symposium on Neural Computation (NC 2000), pp. 115-121, ICSC Academic Press, 2000
- 1 2 3 Christian Igel and Michael Hüsken. Empirical Evaluation of the Improved Rprop Learning Algorithm. Neurocomputing 50:105-123, 2003
- ↑ Martin Riedmiller and Heinrich Braun. A direct adaptive method for faster backpropagation learning: The Rprop algorithm. Proceedings of the IEEE International Conference on Neural Networks, 586-591, IEEE Press, 1993
- ↑ Martin Riedmiller. Advanced supervised learning in multi-layer perceptrons - From backpropagation to adaptive learning algorithms. Computer Standards and Interfaces 16(5), 265-278, 1994
- ↑ Martin Riedmiller. Rprop – Description and Implementation Details. Technical report, 1994