In probability theory and statistics, Bayes' theorem, named after Thomas Bayes, describes the probability of an event, based on prior knowledge of conditions that might be related to the event. For example, if the risk of developing health problems is known to increase with age, Bayes' theorem allows the risk to an individual of a known age to be assessed more accurately by conditioning it relative to their age, rather than assuming that the individual is typical of the population as a whole.
Bayesian inference is a method of statistical inference in which Bayes' theorem is used to update the probability for a hypothesis as more evidence or information becomes available. Fundamentally, Bayesian inference uses prior knowledge, in the form of a prior distribution in order to estimate posterior probabilities. Bayesian inference is an important technique in statistics, and especially in mathematical statistics. Bayesian updating is particularly important in the dynamic analysis of a sequence of data. Bayesian inference has found application in a wide range of activities, including science, engineering, philosophy, medicine, sport, and law. In the philosophy of decision theory, Bayesian inference is closely related to subjective probability, often called "Bayesian probability".
Geostatistics is a branch of statistics focusing on spatial or spatiotemporal datasets. Developed originally to predict probability distributions of ore grades for mining operations, it is currently applied in diverse disciplines including petroleum geology, hydrogeology, hydrology, meteorology, oceanography, geochemistry, geometallurgy, geography, forestry, environmental control, landscape ecology, soil science, and agriculture. Geostatistics is applied in varied branches of geography, particularly those involving the spread of diseases (epidemiology), the practice of commerce and military planning (logistics), and the development of efficient spatial networks. Geostatistical algorithms are incorporated in many places, including geographic information systems (GIS).

In statistics and statistical physics, the Metropolis–Hastings algorithm is a Markov chain Monte Carlo (MCMC) method for obtaining a sequence of random samples from a probability distribution from which direct sampling is difficult. New samples are added to the sequence in two steps: first a new sample is proposed based on the previous sample, then the proposed sample is either added to the sequence or rejected depending on the value of the probability distribution at that point. The resulting sequence can be used to approximate the distribution or to compute an integral.
The principle of maximum entropy states that the probability distribution which best represents the current state of knowledge about a system is the one with largest entropy, in the context of precisely stated prior data.

The unified neutral theory of biodiversity and biogeography is a theory and the title of a monograph by ecologist Stephen P. Hubbell. It aims to explain the diversity and relative abundance of species in ecological communities. Like other neutral theories of ecology, Hubbell assumes that the differences between members of an ecological community of trophically similar species are "neutral", or irrelevant to their success. This implies that niche differences do not influence abundance and the abundance of each species follows a random walk. The theory has sparked controversy, and some authors consider it a more complex version of other null models that fit the data better.
Mark and recapture is a method commonly used in ecology to estimate an animal population's size where it is impractical to count every individual. A portion of the population is captured, marked, and released. Later, another portion will be captured and the number of marked individuals within the sample is counted. Since the number of marked individuals within the second sample should be proportional to the number of marked individuals in the whole population, an estimate of the total population size can be obtained by dividing the number of marked individuals by the proportion of marked individuals in the second sample. The method assumes, rightly or wrongly, that the probability of capture is the same for all individuals. Other names for this method, or closely related methods, include capture-recapture, capture-mark-recapture, mark-recapture, sight-resight, mark-release-recapture, multiple systems estimation, band recovery, the Petersen method, and the Lincoln method.
Spatial ecology studies the ultimate distributional or spatial unit occupied by a species. In a particular habitat shared by several species, each of the species is usually confined to its own microhabitat or spatial niche because two species in the same general territory cannot usually occupy the same ecological niche for any significant length of time.
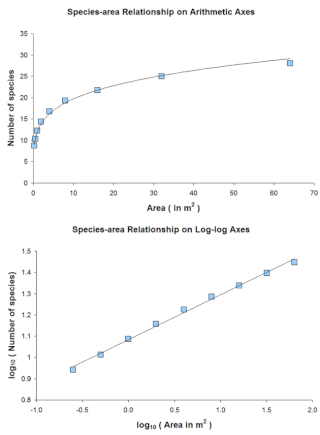
The species–area relationship or species–area curve describes the relationship between the area of a habitat, or of part of a habitat, and the number of species found within that area. Larger areas tend to contain larger numbers of species, and empirically, the relative numbers seem to follow systematic mathematical relationships. The species–area relationship is usually constructed for a single type of organism, such as all vascular plants or all species of a specific trophic level within a particular site. It is rarely if ever, constructed for all types of organisms if simply because of the prodigious data requirements. It is related but not identical to the species discovery curve.

In Bayesian statistics, a credible interval is an interval used to characterize a probability distribution. It is defined such that an unobserved parameter value has a particular probability to fall within it. For example, in an experiment that determines the distribution of possible values of the parameter , if the probability that lies between 35 and 45 is , then is a 95% credible interval.
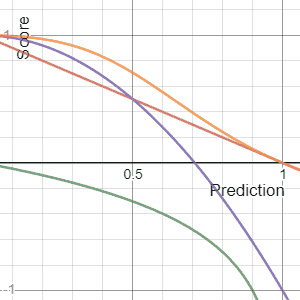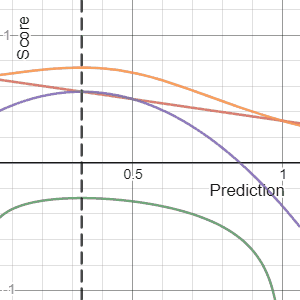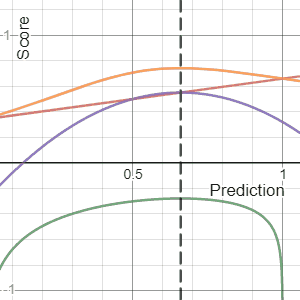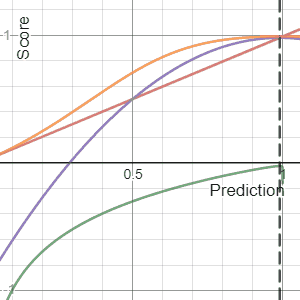
In decision theory, a scoring rule provides evaluation metrics for probabilistic predictions or forecasts. While "regular" loss functions assign a goodness-of-fit score to a predicted value and an observed value, scoring rules assign such a score to a predicted probability distribution and an observed value. On the other hand, a scoring function provides a summary measure for the evaluation of point predictions, i.e. one predicts a property or functional , like the expectation or the median.

A multifractal system is a generalization of a fractal system in which a single exponent is not enough to describe its dynamics; instead, a continuous spectrum of exponents is needed.
Approximate Bayesian computation (ABC) constitutes a class of computational methods rooted in Bayesian statistics that can be used to estimate the posterior distributions of model parameters.
In ecology, the occupancy–abundance (O–A) relationship is the relationship between the abundance of species and the size of their ranges within a region. This relationship is perhaps one of the most well-documented relationships in macroecology, and applies both intra- and interspecifically. In most cases, the O–A relationship is a positive relationship. Although an O–A relationship would be expected, given that a species colonizing a region must pass through the origin and could reach some theoretical maximum abundance and distribution, the relationship described here is somewhat more substantial, in that observed changes in range are associated with greater-than-proportional changes in abundance. Although this relationship appears to be pervasive, and has important implications for the conservation of endangered species, the mechanism(s) underlying it remain poorly understood.
Mechanistic models for niche apportionment are biological models used to explain relative species abundance distributions. These niche apportionment models describe how species break up resource pool in multi-dimensional space, determining the distribution of abundances of individuals among species. The relative abundances of species are usually expressed as a Whittaker plot, or rank abundance plot, where species are ranked by number of individuals on the x-axis, plotted against the log relative abundance of each species on the y-axis. The relative abundance can be measured as the relative number of individuals within species or the relative biomass of individuals within species.
In macroecology and community ecology, an occupancy frequency distribution (OFD) is the distribution of the numbers of species occupying different numbers of areas. It was first reported in 1918 by the Danish botanist Christen C. Raunkiær in his study on plant communities. The OFD is also known as the species-range size distribution in literature.
Taylor's power law is an empirical law in ecology that relates the variance of the number of individuals of a species per unit area of habitat to the corresponding mean by a power law relationship. It is named after the ecologist who first proposed it in 1961, Lionel Roy Taylor (1924–2007). Taylor's original name for this relationship was the law of the mean. The name Taylor's law was coined by Southwood in 1966.
In ecology, plot sampling is a widely used method of abundance estimation in which specific areas, or plots, are selected from within a survey region and sampled. This approach allows scientists to make population estimates using statistical techniques such as the Horvitz–Thompson estimator. Plot sampling is generally effective when it can be assumed that each survey will identify all of the animals in the sampled area, and that the animals will be distributed uniformly and independently.
In probability theory and statistics, the discrete Weibull distribution is the discrete variant of the Weibull distribution. The Discrete Weibull Distribution, first introduced by Toshio Nakagawa and Shunji Osaki, is a discrete analog of the continuous Weibull distribution, predominantly used in reliability engineering. It is particularly applicable for modeling failure data measured in discrete units like cycles or shocks. This distribution provides a versatile tool for analyzing scenarios where the timing of events is counted in distinct intervals, making it distinctively useful in fields that deal with discrete data patterns and reliability analysis.





