
In probability theory and statistics, the exponential distribution or negative exponential distribution is the probability distribution of the distance between events in a Poisson point process, i.e., a process in which events occur continuously and independently at a constant average rate; the distance parameter could be any meaningful mono-dimensional measure of the process, such as time between production errors, or length along a roll of fabric in the weaving manufacturing process. It is a particular case of the gamma distribution. It is the continuous analogue of the geometric distribution, and it has the key property of being memoryless. In addition to being used for the analysis of Poisson point processes it is found in various other contexts.

The Pareto distribution, named after the Italian civil engineer, economist, and sociologist Vilfredo Pareto, is a power-law probability distribution that is used in description of social, quality control, scientific, geophysical, actuarial, and many other types of observable phenomena; the principle originally applied to describing the distribution of wealth in a society, fitting the trend that a large portion of wealth is held by a small fraction of the population. The Pareto principle or "80-20 rule" stating that 80% of outcomes are due to 20% of causes was named in honour of Pareto, but the concepts are distinct, and only Pareto distributions with shape value of log45 ≈ 1.16 precisely reflect it. Empirical observation has shown that this 80-20 distribution fits a wide range of cases, including natural phenomena and human activities.

In probability theory, a log-normal (or lognormal) distribution is a continuous probability distribution of a random variable whose logarithm is normally distributed. Thus, if the random variable X is log-normally distributed, then Y = ln(X) has a normal distribution. Equivalently, if Y has a normal distribution, then the exponential function of Y, X = exp(Y), has a log-normal distribution. A random variable which is log-normally distributed takes only positive real values. It is a convenient and useful model for measurements in exact and engineering sciences, as well as medicine, economics and other topics (e.g., energies, concentrations, lengths, prices of financial instruments, and other metrics).
In statistics, maximum likelihood estimation (MLE) is a method of estimating the parameters of an assumed probability distribution, given some observed data. This is achieved by maximizing a likelihood function so that, under the assumed statistical model, the observed data is most probable. The point in the parameter space that maximizes the likelihood function is called the maximum likelihood estimate. The logic of maximum likelihood is both intuitive and flexible, and as such the method has become a dominant means of statistical inference.

In probability theory and statistics, the Weibull distribution is a continuous probability distribution. It models a broad range of random variables, largely in the nature of a time to failure or time between events. Examples are maximum one-day rainfalls and the time a user spends on a web page.

In probability theory and statistics, the Gumbel distribution is used to model the distribution of the maximum of a number of samples of various distributions.
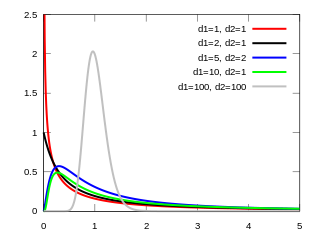
In probability theory and statistics, the F-distribution or F-ratio, also known as Snedecor's F distribution or the Fisher–Snedecor distribution, is a continuous probability distribution that arises frequently as the null distribution of a test statistic, most notably in the analysis of variance (ANOVA) and other F-tests.
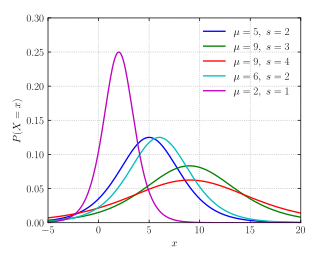
In probability theory and statistics, the logistic distribution is a continuous probability distribution. Its cumulative distribution function is the logistic function, which appears in logistic regression and feedforward neural networks. It resembles the normal distribution in shape but has heavier tails. The logistic distribution is a special case of the Tukey lambda distribution.

In probability theory, a distribution is said to be stable if a linear combination of two independent random variables with this distribution has the same distribution, up to location and scale parameters. A random variable is said to be stable if its distribution is stable. The stable distribution family is also sometimes referred to as the Lévy alpha-stable distribution, after Paul Lévy, the first mathematician to have studied it.
In probability theory and statistics, the generalized extreme value (GEV) distribution is a family of continuous probability distributions developed within extreme value theory to combine the Gumbel, Fréchet and Weibull families also known as type I, II and III extreme value distributions. By the extreme value theorem the GEV distribution is the only possible limit distribution of properly normalized maxima of a sequence of independent and identically distributed random variables. that a limit distribution needs to exist, which requires regularity conditions on the tail of the distribution. Despite this, the GEV distribution is often used as an approximation to model the maxima of long (finite) sequences of random variables.
In statistics and information theory, a maximum entropy probability distribution has entropy that is at least as great as that of all other members of a specified class of probability distributions. According to the principle of maximum entropy, if nothing is known about a distribution except that it belongs to a certain class, then the distribution with the largest entropy should be chosen as the least-informative default. The motivation is twofold: first, maximizing entropy minimizes the amount of prior information built into the distribution; second, many physical systems tend to move towards maximal entropy configurations over time.
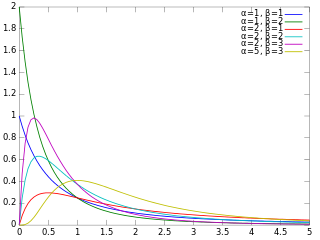
In probability theory and statistics, the beta prime distribution is an absolutely continuous probability distribution. If has a beta distribution, then the odds has a beta prime distribution.
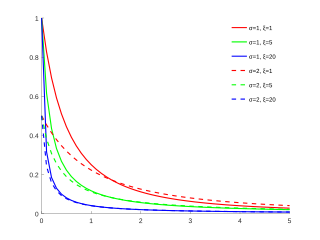
In statistics, the generalized Pareto distribution (GPD) is a family of continuous probability distributions. It is often used to model the tails of another distribution. It is specified by three parameters: location , scale , and shape . Sometimes it is specified by only scale and shape and sometimes only by its shape parameter. Some references give the shape parameter as .
A ratio distribution is a probability distribution constructed as the distribution of the ratio of random variables having two other known distributions. Given two random variables X and Y, the distribution of the random variable Z that is formed as the ratio Z = X/Y is a ratio distribution.

The Fréchet distribution, also known as inverse Weibull distribution, is a special case of the generalized extreme value distribution. It has the cumulative distribution function
The term generalized logistic distribution is used as the name for several different families of probability distributions. For example, Johnson et al. list four forms, which are listed below.

In probability theory and statistics, the normal-inverse-gamma distribution is a four-parameter family of multivariate continuous probability distributions. It is the conjugate prior of a normal distribution with unknown mean and variance.
In statistics, the Fisher–Tippett–Gnedenko theorem is a general result in extreme value theory regarding asymptotic distribution of extreme order statistics. The maximum of a sample of iid random variables after proper renormalization can only converge in distribution to one of three possible distribution families: the Gumbel distribution, the Fréchet distribution, or the Weibull distribution. Credit for the extreme value theorem and its convergence details are given to Fréchet (1927), Fisher and Tippett (1928), Mises (1936), and Gnedenko (1943).
Least-squares support-vector machines (LS-SVM) for statistics and in statistical modeling, are least-squares versions of support-vector machines (SVM), which are a set of related supervised learning methods that analyze data and recognize patterns, and which are used for classification and regression analysis. In this version one finds the solution by solving a set of linear equations instead of a convex quadratic programming (QP) problem for classical SVMs. Least-squares SVM classifiers were proposed by Johan Suykens and Joos Vandewalle. LS-SVMs are a class of kernel-based learning methods.
In statistics and probability theory, the nonparametric skew is a statistic occasionally used with random variables that take real values. It is a measure of the skewness of a random variable's distribution—that is, the distribution's tendency to "lean" to one side or the other of the mean. Its calculation does not require any knowledge of the form of the underlying distribution—hence the name nonparametric. It has some desirable properties: it is zero for any symmetric distribution; it is unaffected by a scale shift; and it reveals either left- or right-skewness equally well. In some statistical samples it has been shown to be less powerful than the usual measures of skewness in detecting departures of the population from normality.

























