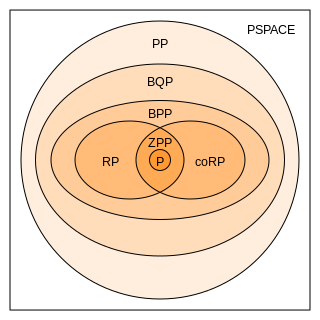
In computational complexity theory, bounded-error quantum polynomial time (BQP) is the class of decision problems solvable by a quantum computer in polynomial time, with an error probability of at most 1/3 for all instances. It is the quantum analogue to the complexity class BPP.
In artificial intelligence, with implications for cognitive science, the frame problem describes an issue with using first-order logic to express facts about a robot in the world. Representing the state of a robot with traditional first-order logic requires the use of many axioms that simply imply that things in the environment do not change arbitrarily. For example, Hayes describes a "block world" with rules about stacking blocks together. In a first-order logic system, additional axioms are required to make inferences about the environment. The frame problem is the problem of finding adequate collections of axioms for a viable description of a robot environment.
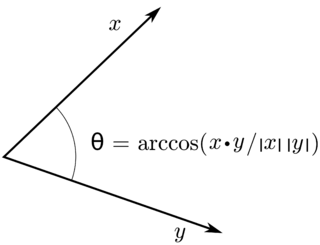
In mathematics, an inner product space is a real vector space or a complex vector space with an operation called an inner product. The inner product of two vectors in the space is a scalar, often denoted with angle brackets such as in . Inner products allow formal definitions of intuitive geometric notions, such as lengths, angles, and orthogonality of vectors. Inner product spaces generalize Euclidean vector spaces, in which the inner product is the dot product or scalar product of Cartesian coordinates. Inner product spaces of infinite dimension are widely used in functional analysis. Inner product spaces over the field of complex numbers are sometimes referred to as unitary spaces. The first usage of the concept of a vector space with an inner product is due to Giuseppe Peano, in 1898.

The uncertainty principle, also known as Heisenberg's indeterminacy principle, is a fundamental concept in quantum mechanics. It states that there is a limit to the precision with which certain pairs of physical properties, such as position and momentum, can be simultaneously known. In other words, the more accurately one property is measured, the less accurately the other property can be known.
Distributions, also known as Schwartz distributions or generalized functions, are objects that generalize the classical notion of functions in mathematical analysis. Distributions make it possible to differentiate functions whose derivatives do not exist in the classical sense. In particular, any locally integrable function has a distributional derivative.
In mathematics, a self-adjoint operator on a complex vector space V with inner product is a linear map A that is its own adjoint. If V is finite-dimensional with a given orthonormal basis, this is equivalent to the condition that the matrix of A is a Hermitian matrix, i.e., equal to its conjugate transpose A∗. By the finite-dimensional spectral theorem, V has an orthonormal basis such that the matrix of A relative to this basis is a diagonal matrix with entries in the real numbers. This article deals with applying generalizations of this concept to operators on Hilbert spaces of arbitrary dimension.
In mathematics as well as physics, a linear operator acting on an inner product space is called positive-semidefinite if, for every , and , where is the domain of . Positive-semidefinite operators are denoted as . The operator is said to be positive-definite, and written , if for all .

In linear algebra and functional analysis, a projection is a linear transformation from a vector space to itself such that . That is, whenever is applied twice to any vector, it gives the same result as if it were applied once. It leaves its image unchanged. This definition of "projection" formalizes and generalizes the idea of graphical projection. One can also consider the effect of a projection on a geometrical object by examining the effect of the projection on points in the object.
In computational complexity theory, the polynomial hierarchy is a hierarchy of complexity classes that generalize the classes NP and co-NP. Each class in the hierarchy is contained within PSPACE. The hierarchy can be defined using oracle machines or alternating Turing machines. It is a resource-bounded counterpart to the arithmetical hierarchy and analytical hierarchy from mathematical logic. The union of the classes in the hierarchy is denoted PH.

In quantum information theory, a quantum circuit is a model for quantum computation, similar to classical circuits, in which a computation is a sequence of quantum gates, measurements, initializations of qubits to known values, and possibly other actions. The minimum set of actions that a circuit needs to be able to perform on the qubits to enable quantum computation is known as DiVincenzo's criteria.
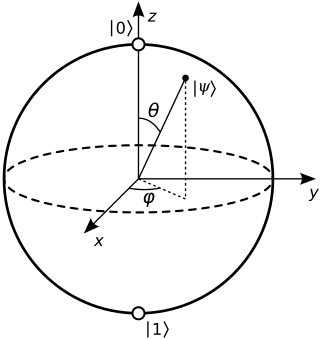
In quantum mechanics and computing, the Bloch sphere is a geometrical representation of the pure state space of a two-level quantum mechanical system (qubit), named after the physicist Felix Bloch.
In linear algebra and functional analysis, the partial trace is a generalization of the trace. Whereas the trace is a scalar valued function on operators, the partial trace is an operator-valued function. The partial trace has applications in quantum information and decoherence which is relevant for quantum measurement and thereby to the decoherent approaches to interpretations of quantum mechanics, including consistent histories and the relative state interpretation.
In probability theory and statistics, given a stochastic process, the autocovariance is a function that gives the covariance of the process with itself at pairs of time points. Autocovariance is closely related to the autocorrelation of the process in question.
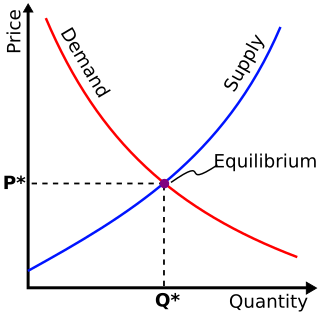
In mathematical economics, the Arrow–Debreu model is a theoretical general equilibrium model. It posits that under certain economic assumptions there must be a set of prices such that aggregate supplies will equal aggregate demands for every commodity in the economy.
In quantum computing, quantum finite automata (QFA) or quantum state machines are a quantum analog of probabilistic automata or a Markov decision process. They provide a mathematical abstraction of real-world quantum computers. Several types of automata may be defined, including measure-once and measure-many automata. Quantum finite automata can also be understood as the quantization of subshifts of finite type, or as a quantization of Markov chains. QFAs are, in turn, special cases of geometric finite automata or topological finite automata.
In logic, philosophy, and theoretical computer science, dynamic logic is an extension of modal logic capable of encoding properties of computer programs.
This is a glossary for the terminology often encountered in undergraduate quantum mechanics courses.
In computer science, a communicating finite-state machine is a finite state machine labeled with "receive" and "send" operations over some alphabet of channels. They were introduced by Brand and Zafiropulo, and can be used as a model of concurrent processes like Petri nets. Communicating finite state machines are used frequently for modeling a communication protocol since they make it possible to detect major protocol design errors, including boundedness, deadlocks, and unspecified receptions.
The Harrow–Hassidim–Lloyd algorithm or HHL algorithm is a quantum algorithm for numerically solving a system of linear equations, designed by Aram Harrow, Avinatan Hassidim, and Seth Lloyd. The algorithm estimates the result of a scalar measurement on the solution vector to a given linear system of equations.
In machine learning and computer vision, M-theory is a learning framework inspired by feed-forward processing in the ventral stream of visual cortex and originally developed for recognition and classification of objects in visual scenes. M-theory was later applied to other areas, such as speech recognition. On certain image recognition tasks, algorithms based on a specific instantiation of M-theory, HMAX, achieved human-level performance.
























