In information theory, data compression, source coding, or bit-rate reduction is the process of encoding information using fewer bits than the original representation. Any particular compression is either lossy or lossless. Lossless compression reduces bits by identifying and eliminating statistical redundancy. No information is lost in lossless compression. Lossy compression reduces bits by removing unnecessary or less important information. Typically, a device that performs data compression is referred to as an encoder, and one that performs the reversal of the process (decompression) as a decoder.

In information technology, lossy compression or irreversible compression is the class of data compression methods that uses inexact approximations and partial data discarding to represent the content. These techniques are used to reduce data size for storing, handling, and transmitting content. The different versions of the photo of the cat on this page show how higher degrees of approximation create coarser images as more details are removed. This is opposed to lossless data compression which does not degrade the data. The amount of data reduction possible using lossy compression is much higher than using lossless techniques.

Image compression is a type of data compression applied to digital images, to reduce their cost for storage or transmission. Algorithms may take advantage of visual perception and the statistical properties of image data to provide superior results compared with generic data compression methods which are used for other digital data.

Motion compensation in computing is an algorithmic technique used to predict a frame in a video given the previous and/or future frames by accounting for motion of the camera and/or objects in the video. It is employed in the encoding of video data for video compression, for example in the generation of MPEG-2 files. Motion compensation describes a picture in terms of the transformation of a reference picture to the current picture. The reference picture may be previous in time or even from the future. When images can be accurately synthesized from previously transmitted/stored images, the compression efficiency can be improved.

A compression artifact is a noticeable distortion of media caused by the application of lossy compression. Lossy data compression involves discarding some of the media's data so that it becomes small enough to be stored within the desired disk space or transmitted (streamed) within the available bandwidth. If the compressor cannot store enough data in the compressed version, the result is a loss of quality, or introduction of artifacts. The compression algorithm may not be intelligent enough to discriminate between distortions of little subjective importance and those objectionable to the user.

Advanced Video Coding (AVC), also referred to as H.264 or MPEG-4 Part 10, is a video compression standard based on block-oriented, motion-compensated coding. It is by far the most commonly used format for the recording, compression, and distribution of video content, used by 91% of video industry developers as of September 2019. It supports a maximum resolution of 8K UHD.
An inter frame is a frame in a video compression stream which is expressed in terms of one or more neighboring frames. The "inter" part of the term refers to the use of Inter frame prediction. This kind of prediction tries to take advantage from temporal redundancy between neighboring frames enabling higher compression rates.
x264 is a free and open-source software library and a command-line utility developed by VideoLAN for encoding video streams into the H.264/MPEG-4 AVC video coding format. It is released under the terms of the GNU General Public License.

In computer vision and image processing, motion estimation is the process of determining motion vectors that describe the transformation from one 2D image to another; usually from adjacent frames in a video sequence. It is an ill-posed problem as the motion happens in three dimensions (3D) but the images are a projection of the 3D scene onto a 2D plane. The motion vectors may relate to the whole image or specific parts, such as rectangular blocks, arbitrary shaped patches or even per pixel. The motion vectors may be represented by a translational model or many other models that can approximate the motion of a real video camera, such as rotation and translation in all three dimensions and zoom.
Video quality is a characteristic of a video passed through a video transmission or processing system that describes perceived video degradation. Video processing systems may introduce some amount of distortion or artifacts in the video signal that negatively impacts the user's perception of a system. For many stakeholders in video production and distribution, assurance of video quality is an important task.
Quarter-pixel motion(also known as Q-pel motion or Qpel motion) refers to using a quarter of the distance between pixels as the motion vector precision for motion estimation and motion compensation in video compression schemes. It is used in many modern video coding formats such as MPEG-4 ASP and H.264/AVC. Though higher precision motion vectors take more bits to encode, they can sometimes result in more efficient compression overall, by increasing the quality of the prediction signal.
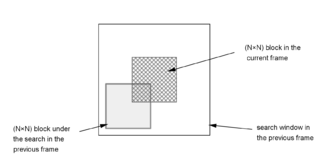
A Block Matching Algorithm is a way of locating matching macroblocks in a sequence of digital video frames for the purposes of motion estimation. The underlying supposition behind motion estimation is that the patterns corresponding to objects and background in a frame of video sequence move within the frame to form corresponding objects on the subsequent frame. This can be used to discover temporal redundancy in the video sequence, increasing the effectiveness of inter-frame video compression by defining the contents of a macroblock by reference to the contents of a known macroblock which is minimally different.
Α video codec is software or a device that provides encoding and decoding for digital video, and which may or may not include the use of video compression and/or decompression. Most codecs are typically implementations of video coding formats.
Trellis quantization is an algorithm that can improve data compression in DCT-based encoding methods. It is used to optimize residual DCT coefficients after motion estimation in lossy video compression encoders such as Xvid and x264. Trellis quantization reduces the size of some DCT coefficients while recovering others to take their place. This process can increase quality because coefficients chosen by Trellis have the lowest rate-distortion ratio. Trellis quantization effectively finds the optimal quantization for each block to maximize the PSNR relative to bitrate. It has varying effectiveness depending on the input data and compression method.
Rate-distortion optimization (RDO) is a method of improving video quality in video compression. The name refers to the optimization of the amount of distortion against the amount of data required to encode the video, the rate. While it is primarily used by video encoders, rate-distortion optimization can be used to improve quality in any encoding situation where decisions have to be made that affect both file size and quality simultaneously.
In digital image processing, the sum of absolute differences (SAD) is a measure of the similarity between image blocks. It is calculated by taking the absolute difference between each pixel in the original block and the corresponding pixel in the block being used for comparison. These differences are summed to create a simple metric of block similarity, the L1 norm of the difference image or Manhattan distance between two image blocks.

VP8 is an open and royalty-free video compression format released by On2 Technologies in 2008.
A video coding format is a content representation format of digital video content, such as in a data file or bitstream. It typically uses a standardized video compression algorithm, most commonly based on discrete cosine transform (DCT) coding and motion compensation. A specific software, firmware, or hardware implementation capable of compression or decompression in a specific video coding format is called a video codec.

VP9 is an open and royalty-free video coding format developed by Google.
ZPEG is a motion video technology that applies a human visual acuity model to a decorrelated transform-domain space, thereby optimally reducing the redundancies in motion video by removing the subjectively imperceptible. This technology is applicable to a wide range of video processing problems such as video optimization, real-time motion video compression, subjective quality monitoring, and format conversion.