Related Research Articles

JPEG is a commonly used method of lossy compression for digital images, particularly for those images produced by digital photography. The degree of compression can be adjusted, allowing a selectable tradeoff between storage size and image quality. JPEG typically achieves 10:1 compression with little perceptible loss in image quality. Since its introduction in 1992, JPEG has been the most widely used image compression standard in the world, and the most widely used digital image format, with several billion JPEG images produced every day as of 2015.

Motion compensation in computing, is an algorithmic technique used to predict a frame in a video, given the previous and/or future frames by accounting for motion of the camera and/or objects in the video. It is employed in the encoding of video data for video compression, for example in the generation of MPEG-2 files. Motion compensation describes a picture in terms of the transformation of a reference picture to the current picture. The reference picture may be previous in time or even from the future. When images can be accurately synthesized from previously transmitted/stored images, the compression efficiency can be improved.

A compression artifact is a noticeable distortion of media caused by the application of lossy compression. Lossy data compression involves discarding some of the media's data so that it becomes small enough to be stored within the desired disk space or transmitted (streamed) within the available bandwidth. If the compressor cannot store enough data in the compressed version, the result is a loss of quality, or introduction of artifacts. The compression algorithm may not be intelligent enough to discriminate between distortions of little subjective importance and those objectionable to the user.

In digital image processing and computer vision, image segmentation is the process of partitioning a digital image into multiple image segments, also known as image regions or image objects. The goal of segmentation is to simplify and/or change the representation of an image into something that is more meaningful and easier to analyze. Image segmentation is typically used to locate objects and boundaries in images. More precisely, image segmentation is the process of assigning a label to every pixel in an image such that pixels with the same label share certain characteristics.
Template matching is a technique in digital image processing for finding small parts of an image which match a template image. It can be used for quality control in manufacturing, navigation of mobile robots, or edge detection in images.
The scale-invariant feature transform (SIFT) is a computer vision algorithm to detect, describe, and match local features in images, invented by David Lowe in 1999. Applications include object recognition, robotic mapping and navigation, image stitching, 3D modeling, gesture recognition, video tracking, individual identification of wildlife and match moving.
An inter frame is a frame in a video compression stream which is expressed in terms of one or more neighboring frames. The "inter" part of the term refers to the use of Inter frame prediction. This kind of prediction tries to take advantage from temporal redundancy between neighboring frames enabling higher compression rates.
Peak signal-to-noise ratio (PSNR) is an engineering term for the ratio between the maximum possible power of a signal and the power of corrupting noise that affects the fidelity of its representation. Because many signals have a very wide dynamic range, PSNR is usually expressed as a logarithmic quantity using the decibel scale.
S3 Texture Compression (S3TC) is a group of related lossy texture compression algorithms originally developed by Iourcha et al. of S3 Graphics, Ltd. for use in their Savage 3D computer graphics accelerator. The method of compression is strikingly similar to the previously published Color Cell Compression, which is in turn an adaptation of Block Truncation Coding published in the late 1970s. Unlike some image compression algorithms, S3TC's fixed-rate data compression coupled with the single memory access made it well-suited for use in compressing textures in hardware-accelerated 3D computer graphics. Its subsequent inclusion in Microsoft's DirectX 6.0 and OpenGL 1.3 led to widespread adoption of the technology among hardware and software makers. While S3 Graphics is no longer a competitor in the graphics accelerator market, license fees have been levied and collected for the use of S3TC technology until October 2017, for example in game consoles and graphics cards. The wide use of S3TC has led to a de facto requirement for OpenGL drivers to support it, but the patent-encumbered status of S3TC presented a major obstacle to open source implementations, while implementation approaches which tried to avoid the patented parts existed.

In computer vision and image processing, motion estimation is the process of determining motion vectors that describe the transformation from one 2D image to another; usually from adjacent frames in a video sequence. It is an ill-posed problem as the motion happens in three dimensions (3D) but the images are a projection of the 3D scene onto a 2D plane. The motion vectors may relate to the whole image or specific parts, such as rectangular blocks, arbitrary shaped patches or even per pixel. The motion vectors may be represented by a translational model or many other models that can approximate the motion of a real video camera, such as rotation and translation in all three dimensions and zoom.
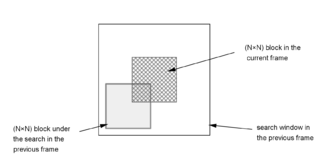
A Block Matching Algorithm is a way of locating matching macroblocks in a sequence of digital video frames for the purposes of motion estimation. The underlying supposition behind motion estimation is that the patterns corresponding to objects and background in a frame of video sequence move within the frame to form corresponding objects on the subsequent frame. This can be used to discover temporal redundancy in the video sequence, increasing the effectiveness of inter-frame video compression by defining the contents of a macroblock by reference to the contents of a known macroblock which is minimally different.
The structural similarityindex measure (SSIM) is a method for predicting the perceived quality of digital television and cinematic pictures, as well as other kinds of digital images and videos. SSIM is used for measuring the similarity between two images. The SSIM index is a full reference metric; in other words, the measurement or prediction of image quality is based on an initial uncompressed or distortion-free image as reference.
Doppler echocardiography is a procedure that uses Doppler ultrasonography to examine the heart. An echocardiogram uses high frequency sound waves to create an image of the heart while the use of Doppler technology allows determination of the speed and direction of blood flow by utilizing the Doppler effect.
Binocular disparity refers to the difference in image location of an object seen by the left and right eyes, resulting from the eyes’ horizontal separation (parallax). The brain uses binocular disparity to extract depth information from the two-dimensional retinal images in stereopsis. In computer vision, binocular disparity refers to the difference in coordinates of similar features within two stereo images.
Rate-distortion optimization (RDO) is a method of improving video quality in video compression. The name refers to the optimization of the amount of distortion against the amount of data required to encode the video, the rate. While it is primarily used by video encoders, rate-distortion optimization can be used to improve quality in any encoding situation where decisions have to be made that affect both file size and quality simultaneously.
The sum of absolute transformed differences (SATD) is a block matching criterion widely used in fractional motion estimation for video compression. It works by taking a frequency transform, usually a Hadamard transform, of the differences between the pixels in the original block and the corresponding pixels in the block being used for comparison. The transform itself is often of a small block rather than the entire macroblock. For example, in x264, a series of 4×4 blocks are transformed rather than doing the more processor-intensive 16×16 transform.
Computer stereo vision is the extraction of 3D information from digital images, such as those obtained by a CCD camera. By comparing information about a scene from two vantage points, 3D information can be extracted by examining the relative positions of objects in the two panels. This is similar to the biological process of stereopsis.
In computer vision, rigid motion segmentation is the process of separating regions, features, or trajectories from a video sequence into coherent subsets of space and time. These subsets correspond to independent rigidly moving objects in the scene. The goal of this segmentation is to differentiate and extract the meaningful rigid motion from the background and analyze it. Image segmentation techniques labels the pixels to be a part of pixels with certain characteristics at a particular time. Here, the pixels are segmented depending on its relative movement over a period of time i.e. the time of the video sequence.

In computer vision, a saliency map is an image that highlights the region on which people's eyes focus first. The goal of a saliency map is to reflect the degree of importance of a pixel to the human visual system. For example, in this image, a person first looks at the fort and light clouds, so they should be highlighted on the saliency map. Saliency maps engineered in artificial or computer vision are typically not the same as the actual saliency map constructed by biological or natural vision.
ZPEG is a motion video technology that applies a human visual acuity model to a decorrelated transform-domain space, thereby optimally reducing the redundancies in motion video by removing the subjectively imperceptible. This technology is applicable to a wide range of video processing problems such as video optimization, real-time motion video compression, subjective quality monitoring, and format conversion.
References
- E. G. Richardson, Iain (2003). H.264 and MPEG-4 Video Compression: Video Coding for Next-generation Multimedia. Chichester: John Wiley & Sons Ltd.