
In probability theory and statistics, variance is the expectation of the squared deviation of a random variable from its population mean or sample mean. Variance is a measure of dispersion, meaning it is a measure of how far a set of numbers is spread out from their average value. Variance has a central role in statistics, where some ideas that use it include descriptive statistics, statistical inference, hypothesis testing, goodness of fit, and Monte Carlo sampling. Variance is an important tool in the sciences, where statistical analysis of data is common. The variance is the square of the standard deviation, the second central moment of a distribution, and the covariance of the random variable with itself, and it is often represented by , , , , or .
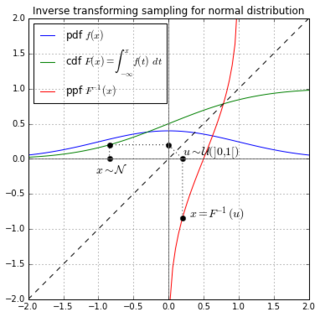
Inverse transform sampling is a basic method for pseudo-random number sampling, i.e., for generating sample numbers at random from any probability distribution given its cumulative distribution function.

In statistics and statistical physics, the Metropolis–Hastings algorithm is a Markov chain Monte Carlo (MCMC) method for obtaining a sequence of random samples from a probability distribution from which direct sampling is difficult. This sequence can be used to approximate the distribution or to compute an integral. Metropolis–Hastings and other MCMC algorithms are generally used for sampling from multi-dimensional distributions, especially when the number of dimensions is high. For single-dimensional distributions, there are usually other methods that can directly return independent samples from the distribution, and these are free from the problem of autocorrelated samples that is inherent in MCMC methods.

In probability theory, the law of large numbers (LLN) is a theorem that describes the result of performing the same experiment a large number of times. According to the law, the average of the results obtained from a large number of trials should be close to the expected value and tends to become closer to the expected value as more trials are performed.

In analysis, numerical integration comprises a broad family of algorithms for calculating the numerical value of a definite integral, and by extension, the term is also sometimes used to describe the numerical solution of differential equations. This article focuses on calculation of definite integrals.

In probability theory and statistics, the beta distribution is a family of continuous probability distributions defined on the interval [0, 1] parameterized by two positive shape parameters, denoted by α and β, that appear as exponents of the random variable and control the shape of the distribution. The generalization to multiple variables is called a Dirichlet distribution.
In statistics, Markov chain Monte Carlo (MCMC) methods comprise a class of algorithms for sampling from a probability distribution. By constructing a Markov chain that has the desired distribution as its equilibrium distribution, one can obtain a sample of the desired distribution by recording states from the chain. The more steps are included, the more closely the distribution of the sample matches the actual desired distribution. Various algorithms exist for constructing chains, including the Metropolis–Hastings algorithm.
In mathematics, the moments of a function are quantitative measures related to the shape of the function's graph. If the function represents mass, then the first moment is the center of the mass, and the second moment is the rotational inertia. If the function is a probability distribution, then the first moment is the expected value, the second central moment is the variance, the third standardized moment is the skewness, and the fourth standardized moment is the kurtosis. The mathematical concept is closely related to the concept of moment in physics.

In numerical analysis, the quasi-Monte Carlo method is a method for numerical integration and solving some other problems using low-discrepancy sequences. This is in contrast to the regular Monte Carlo method or Monte Carlo integration, which are based on sequences of pseudorandom numbers.
In statistics, importance sampling is a general technique for estimating properties of a particular distribution, while only having samples generated from a different distribution than the distribution of interest. The method was first introduced by Teun Kloek and Herman K. van Dijk in 1978, and is related to umbrella sampling in computational physics. Depending on the application, the term may refer to the process of sampling from this alternative distribution, the process of inference, or both.

In mathematics, Monte Carlo integration is a technique for numerical integration using random numbers. It is a particular Monte Carlo method that numerically computes a definite integral. While other algorithms usually evaluate the integrand at a regular grid, Monte Carlo randomly chooses points at which the integrand is evaluated. This method is particularly useful for higher-dimensional integrals.
Monte Carlo methods are used in corporate finance and mathematical finance to value and analyze (complex) instruments, portfolios and investments by simulating the various sources of uncertainty affecting their value, and then determining the distribution of their value over the range of resultant outcomes. This is usually done by help of stochastic asset models. The advantage of Monte Carlo methods over other techniques increases as the dimensions of the problem increase.
Estimation theory is a branch of statistics that deals with estimating the values of parameters based on measured empirical data that has a random component. The parameters describe an underlying physical setting in such a way that their value affects the distribution of the measured data. An estimator attempts to approximate the unknown parameters using the measurements. In estimation theory, two approaches are generally considered:
The control variates method is a variance reduction technique used in Monte Carlo methods. It exploits information about the errors in estimates of known quantities to reduce the error of an estimate of an unknown quantity.
The cross-entropy (CE) method is a Monte Carlo method for importance sampling and optimization. It is applicable to both combinatorial and continuous problems, with either a static or noisy objective.
The Wang and Landau algorithm, proposed by Fugao Wang and David P. Landau, is a Monte Carlo method designed to estimate the density of states of a system. The method performs a non-Markovian random walk to build the density of states by quickly visiting all the available energy spectrum. The Wang and Landau algorithm is an important method to obtain the density of states required to perform a multicanonical simulation.
In statistics, the antithetic variates method is a variance reduction technique used in Monte Carlo methods. Considering that the error in the simulated signal has a one-over square root convergence, a very large number of sample paths is required to obtain an accurate result. The antithetic variates method reduces the variance of the simulation results.
In probability and statistics, a compound probability distribution is the probability distribution that results from assuming that a random variable is distributed according to some parametrized distribution, with the parameters of that distribution themselves being random variables. If the parameter is a scale parameter, the resulting mixture is also called a scale mixture.
In statistics and physics, multicanonical ensemble is a Markov chain Monte Carlo sampling technique that uses the Metropolis–Hastings algorithm to compute integrals where the integrand has a rough landscape with multiple local minima. It samples states according to the inverse of the density of states, which has to be known a priori or be computed using other techniques like the Wang and Landau algorithm. Multicanonical sampling is an important technique for spin systems like the Ising model or spin glasses.
Probabilistic numerics is a scientific field at the intersection of statistics, machine learning and applied mathematics, where tasks in numerical analysis including finding numerical solutions for integration, linear algebra, optimisation and differential equations are seen as problems of statistical, probabilistic, or Bayesian inference.












