
A central processing unit (CPU), also called a central processor, main processor, or just processor, is the most important processor in a given computer. Its electronic circuitry executes instructions of a computer program, such as arithmetic, logic, controlling, and input/output (I/O) operations. This role contrasts with that of external components, such as main memory and I/O circuitry, and specialized coprocessors such as graphics processing units (GPUs).

A superscalar processor is a CPU that implements a form of parallelism called instruction-level parallelism within a single processor. In contrast to a scalar processor, which can execute at most one single instruction per clock cycle, a superscalar processor can execute more than one instruction during a clock cycle by simultaneously dispatching multiple instructions to different execution units on the processor. It therefore allows more throughput than would otherwise be possible at a given clock rate. Each execution unit is not a separate processor, but an execution resource within a single CPU such as an arithmetic logic unit.
Very long instruction word (VLIW) refers to instruction set architectures that are designed to exploit instruction-level parallelism (ILP). A VLIW processor allows programs to explicitly specify instructions to execute in parallel, whereas conventional central processing units (CPUs) mostly allow programs to specify instructions to execute in sequence only. VLIW is intended to allow higher performance without the complexity inherent in some other designs.

Single instruction, multiple data (SIMD) is a type of parallel processing in Flynn's taxonomy. SIMD can be internal and it can be directly accessible through an instruction set architecture (ISA), but it should not be confused with an ISA. SIMD describes computers with multiple processing elements that perform the same operation on multiple data points simultaneously.

The program counter (PC), commonly called the instruction pointer (IP) in Intel x86 and Itanium microprocessors, and sometimes called the instruction address register (IAR), the instruction counter, or just part of the instruction sequencer, is a processor register that indicates where a computer is in its program sequence.

Parallel computing is a type of computation in which many calculations or processes are carried out simultaneously. Large problems can often be divided into smaller ones, which can then be solved at the same time. There are several different forms of parallel computing: bit-level, instruction-level, data, and task parallelism. Parallelism has long been employed in high-performance computing, but has gained broader interest due to the physical constraints preventing frequency scaling. As power consumption by computers has become a concern in recent years, parallel computing has become the dominant paradigm in computer architecture, mainly in the form of multi-core processors.
Computer science is the study of the theoretical foundations of information and computation and their implementation and application in computer systems. One well known subject classification system for computer science is the ACM Computing Classification System devised by the Association for Computing Machinery.
In parallel computer architectures, a systolic array is a homogeneous network of tightly coupled data processing units (DPUs) called cells or nodes. Each node or DPU independently computes a partial result as a function of the data received from its upstream neighbours, stores the result within itself and passes it downstream. Systolic arrays were first used in Colossus, which was an early computer used to break German Lorenz ciphers during World War II. Due to the classified nature of Colossus, they were independently invented or rediscovered by H. T. Kung and Charles Leiserson who described arrays for many dense linear algebra computations for banded matrices. Early applications include computing greatest common divisors of integers and polynomials. They are sometimes classified as multiple-instruction single-data (MISD) architectures under Flynn's taxonomy, but this classification is questionable because a strong argument can be made to distinguish systolic arrays from any of Flynn's four categories: SISD, SIMD, MISD, MIMD, as discussed later in this article.
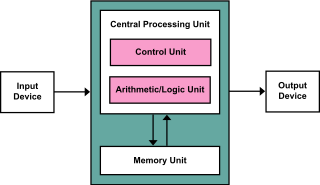
The von Neumann architecture—also known as the von Neumann model or Princeton architecture—is a computer architecture based on a 1945 description by John von Neumann, and by others, in the First Draft of a Report on the EDVAC. The document describes a design architecture for an electronic digital computer with these components:
In computing, single program, multiple data (SPMD) is a term that has been used to refer to computational models for exploiting parallelism where-by multiple processors cooperate in the execution of a program in order to obtain results faster.

Hardware acceleration is the use of computer hardware designed to perform specific functions more efficiently when compared to software running on a general-purpose central processing unit (CPU). Any transformation of data that can be calculated in software running on a generic CPU can also be calculated in custom-made hardware, or in some mix of both.
In computing, a parallel programming model is an abstraction of parallel computer architecture, with which it is convenient to express algorithms and their composition in programs. The value of a programming model can be judged on its generality: how well a range of different problems can be expressed for a variety of different architectures, and its performance: how efficiently the compiled programs can execute. The implementation of a parallel programming model can take the form of a library invoked from a programming language, as an extension to an existing languages.
Concurrent computing is a form of computing in which several computations are executed concurrently—during overlapping time periods—instead of sequentially—with one completing before the next starts.

Binary Modular Dataflow Machine (BMDFM) is a software package that enables running an application in parallel on shared memory symmetric multiprocessing (SMP) computers using the multiple processors to speed up the execution of single applications. BMDFM automatically identifies and exploits parallelism due to the static and mainly dynamic scheduling of the dataflow instruction sequences derived from the formerly sequential program.
In computer science, stream processing is a programming paradigm which views streams, or sequences of events in time, as the central input and output objects of computation. Stream processing encompasses dataflow programming, reactive programming, and distributed data processing. Stream processing systems aim to expose parallel processing for data streams and rely on streaming algorithms for efficient implementation. The software stack for these systems includes components such as programming models and query languages, for expressing computation; stream management systems, for distribution and scheduling; and hardware components for acceleration including floating-point units, graphics processing units, and field-programmable gate arrays.

The history of general-purpose CPUs is a continuation of the earlier history of computing hardware.
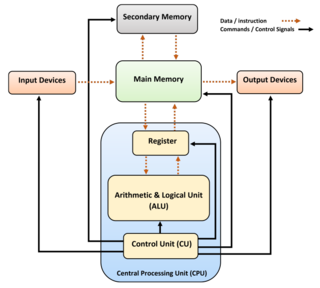
In computer science and computer engineering, computer architecture is a description of the structure of a computer system made from component parts. It can sometimes be a high-level description that ignores details of the implementation. At a more detailed level, the description may include the instruction set architecture design, microarchitecture design, logic design, and implementation.