In computer science, the computational complexity or simply complexity of an algorithm is the amount of resources required to run it. Particular focus is given to computation time and memory storage requirements. The complexity of a problem is the complexity of the best algorithms that allow solving the problem.
In theoretical computer science and mathematics, computational complexity theory focuses on classifying computational problems according to their resource usage, and explores the relationships between these classifications. A computational problem is a task solved by a computer. A computation problem is solvable by mechanical application of mathematical steps, such as an algorithm.
In computer science, a priority queue is an abstract data type similar to a regular queue or stack abstract data type. Each element in a priority queue has an associated priority. In a priority queue, elements with high priority are served before elements with low priority. In some implementations, if two elements have the same priority, they are served in the same order in which they were enqueued. In other implementations, the order of elements with the same priority is undefined.

In computer science, a sorting algorithm is an algorithm that puts elements of a list into an order. The most frequently used orders are numerical order and lexicographical order, and either ascending or descending. Efficient sorting is important for optimizing the efficiency of other algorithms that require input data to be in sorted lists. Sorting is also often useful for canonicalizing data and for producing human-readable output.

A minimum spanning tree (MST) or minimum weight spanning tree is a subset of the edges of a connected, edge-weighted undirected graph that connects all the vertices together, without any cycles and with the minimum possible total edge weight. That is, it is a spanning tree whose sum of edge weights is as small as possible. More generally, any edge-weighted undirected graph has a minimum spanning forest, which is a union of the minimum spanning trees for its connected components.
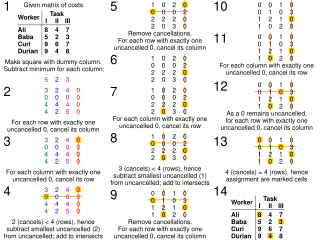
The assignment problem is a fundamental combinatorial optimization problem. In its most general form, the problem is as follows:

In theoretical computer science, the time complexity is the computational complexity that describes the amount of computer time it takes to run an algorithm. Time complexity is commonly estimated by counting the number of elementary operations performed by the algorithm, supposing that each elementary operation takes a fixed amount of time to perform. Thus, the amount of time taken and the number of elementary operations performed by the algorithm are taken to be related by a constant factor.
In computer science, a soft heap is a variant on the simple heap data structure that has constant amortized time complexity for 5 types of operations. This is achieved by carefully "corrupting" (increasing) the keys of at most a constant number of values in the heap.
In computer science, a selection algorithm is an algorithm for finding the th smallest value in a collection of ordered values, such as numbers. The value that it finds is called the th order statistic. Selection includes as special cases the problems of finding the minimum, median, and maximum element in the collection. Selection algorithms include quickselect, and the median of medians algorithm. When applied to a collection of values, these algorithms take linear time, as expressed using big O notation. For data that is already structured, faster algorithms may be possible; as an extreme case, selection in an already-sorted array takes time .
In computer science, a fusion tree is a type of tree data structure that implements an associative array on w-bit integers on a finite universe, where each of the input integers has size less than 2w and is non-negative. When operating on a collection of n key–value pairs, it uses O(n) space and performs searches in O(logwn) time, which is asymptotically faster than a traditional self-balancing binary search tree, and also better than the van Emde Boas tree for large values of w. It achieves this speed by using certain constant-time operations that can be done on a machine word. Fusion trees were invented in 1990 by Michael Fredman and Dan Willard.
In computer science, the AF-heap is a type of priority queue for integer data, an extension of the fusion tree using an atomic heap proposed by M. L. Fredman and D. E. Willard.
In computational complexity theory, the element distinctness problem or element uniqueness problem is the problem of determining whether all the elements of a list are distinct.
In computational complexity theory, and more specifically in the analysis of algorithms with integer data, the transdichotomous model is a variation of the random-access machine in which the machine word size is assumed to match the problem size. The model was proposed by Michael Fredman and Dan Willard, who chose its name "because the dichotomy between the machine model and the problem size is crossed in a reasonable manner."

A top tree is a data structure based on a binary tree for unrooted dynamic trees that is used mainly for various path-related operations. It allows simple divide-and-conquer algorithms. It has since been augmented to maintain dynamically various properties of a tree such as diameter, center and median.
In computer science, a family of hash functions is said to be k-independent, k-wise independent or k-universal if selecting a function at random from the family guarantees that the hash codes of any designated k keys are independent random variables. Such families allow good average case performance in randomized algorithms or data structures, even if the input data is chosen by an adversary. The trade-offs between the degree of independence and the efficiency of evaluating the hash function are well studied, and many k-independent families have been proposed.
In computer science, integer sorting is the algorithmic problem of sorting a collection of data values by integer keys. Algorithms designed for integer sorting may also often be applied to sorting problems in which the keys are floating point numbers, rational numbers, or text strings. The ability to perform integer arithmetic on the keys allows integer sorting algorithms to be faster than comparison sorting algorithms in many cases, depending on the details of which operations are allowed in the model of computing and how large the integers to be sorted are.
In computer science, the cell-probe model is a model of computation similar to the random-access machine, except that all operations are free except memory access. This model is useful for proving lower bounds of algorithms for data structure problems.

Dan Edward Willard was an American computer scientist and logician, and a professor of computer science at the University at Albany.

In computer science, sorting is the problem of sorting pairs of numbers by their sums. Applications of the problem include transit fare minimisation, VLSI design, and sparse polynomial multiplication. As with comparison sorting and integer sorting more generally, algorithms for this problem can be based only on comparisons of these sums, or on other operations that work only when the inputs are small integers.
In computer science, the predecessor problem involves maintaining a set of items to, given an element, efficiently query which element precedes or succeeds that element in an order. Data structures used to solve the problem include balanced binary search trees, van Emde Boas trees, and fusion trees. In the static predecessor problem, the set of elements does not change, but in the dynamic predecessor problem, insertions into and deletions from the set are allowed.








