
In computer science, the analysis of algorithms is the process of finding the computational complexity of algorithms—the amount of time, storage, or other resources needed to execute them. Usually, this involves determining a function that relates the size of an algorithm's input to the number of steps it takes or the number of storage locations it uses. An algorithm is said to be efficient when this function's values are small, or grow slowly compared to a growth in the size of the input. Different inputs of the same size may cause the algorithm to have different behavior, so best, worst and average case descriptions might all be of practical interest. When not otherwise specified, the function describing the performance of an algorithm is usually an upper bound, determined from the worst case inputs to the algorithm.
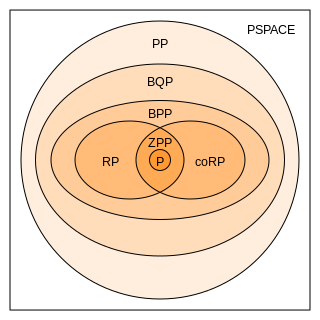
In computational complexity theory, bounded-error quantum polynomial time (BQP) is the class of decision problems solvable by a quantum computer in polynomial time, with an error probability of at most 1/3 for all instances. It is the quantum analogue to the complexity class BPP.
In computer science, the computational complexity or simply complexity of an algorithm is the amount of resources required to run it. Particular focus is given to computation time and memory storage requirements. The complexity of a problem is the complexity of the best algorithms that allow solving the problem.

In computer science, a sorting algorithm is an algorithm that puts elements of a list into an order. The most frequently used orders are numerical order and lexicographical order, and either ascending or descending. Efficient sorting is important for optimizing the efficiency of other algorithms that require input data to be in sorted lists. Sorting is also often useful for canonicalizing data and for producing human-readable output.
Big O notation is a mathematical notation that describes the limiting behavior of a function when the argument tends towards a particular value or infinity. Big O is a member of a family of notations invented by Paul Bachmann, Edmund Landau, and others, collectively called Bachmann–Landau notation or asymptotic notation. The letter O was chosen by Bachmann to stand for Ordnung, meaning the order of approximation.

Bucket sort, or bin sort, is a sorting algorithm that works by distributing the elements of an array into a number of buckets. Each bucket is then sorted individually, either using a different sorting algorithm, or by recursively applying the bucket sorting algorithm. It is a distribution sort, a generalization of pigeonhole sort that allows multiple keys per bucket, and is a cousin of radix sort in the most-to-least significant digit flavor. Bucket sort can be implemented with comparisons and therefore can also be considered a comparison sort algorithm. The computational complexity depends on the algorithm used to sort each bucket, the number of buckets to use, and whether the input is uniformly distributed.
In computational complexity theory, the time hierarchy theorems are important statements about time-bounded computation on Turing machines. Informally, these theorems say that given more time, a Turing machine can solve more problems. For example, there are problems that can be solved with n2 time but not n time.
The space complexity of an algorithm or a computer program is the amount of memory space required to solve an instance of the computational problem as a function of characteristics of the input. It is the memory required by an algorithm until it executes completely. This includes the memory space used by its inputs, called input space, and any other (auxiliary) memory it uses during execution, which is called auxiliary space.
In computer science, the time complexity is the computational complexity that describes the amount of computer time it takes to run an algorithm. Time complexity is commonly estimated by counting the number of elementary operations performed by the algorithm, supposing that each elementary operation takes a fixed amount of time to perform. Thus, the amount of time taken and the number of elementary operations performed by the algorithm are taken to be related by a constant factor.

In computational complexity theory, a complexity class is a set of computational problems "of related resource-based complexity". The two most commonly analyzed resources are time and memory.
In computational complexity theory, DSPACE or SPACE is the computational resource describing the resource of memory space for a deterministic Turing machine. It represents the total amount of memory space that a "normal" physical computer would need to solve a given computational problem with a given algorithm.
In computational complexity theory, the complexity class NTIME(f(n)) is the set of decision problems that can be solved by a non-deterministic Turing machine which runs in time O(f(n)). Here O is the big O notation, f is some function, and n is the size of the input (for which the problem is to be decided).
In computational complexity theory, the space hierarchy theorems are separation results that show that both deterministic and nondeterministic machines can solve more problems in (asymptotically) more space, subject to certain conditions. For example, a deterministic Turing machine can solve more decision problems in space n log n than in space n. The somewhat weaker analogous theorems for time are the time hierarchy theorems.
In computational complexity theory, P/poly is a complexity class representing problems that can be solved by small circuits. More precisely, it is the set of formal languages that have polynomial-size circuit families. It can also be defined equivalently in terms of Turing machines with advice, extra information supplied to the Turing machine along with its input, that may depend on the input length but not on the input itself. In this formulation, P/poly is the class of decision problems that can be solved by a polynomial-time Turing machine with advice strings of length polynomial in the input size. These two different definitions make P/poly central to circuit complexity and non-uniform complexity.
In computer science, an algorithm is said to be asymptotically optimal if, roughly speaking, for large inputs it performs at worst a constant factor worse than the best possible algorithm. It is a term commonly encountered in computer science research as a result of widespread use of big-O notation.

The closest pair of points problem or closest pair problem is a problem of computational geometry: given points in metric space, find a pair of points with the smallest distance between them. The closest pair problem for points in the Euclidean plane was among the first geometric problems that were treated at the origins of the systematic study of the computational complexity of geometric algorithms.
In computational complexity theory, the average-case complexity of an algorithm is the amount of some computational resource used by the algorithm, averaged over all possible inputs. It is frequently contrasted with worst-case complexity which considers the maximal complexity of the algorithm over all possible inputs.
Quantum complexity theory is the subfield of computational complexity theory that deals with complexity classes defined using quantum computers, a computational model based on quantum mechanics. It studies the hardness of computational problems in relation to these complexity classes, as well as the relationship between quantum complexity classes and classical complexity classes.
Generic-case complexity is a subfield of computational complexity theory that studies the complexity of computational problems on "most inputs".
In discrete mathematics, ideal lattices are a special class of lattices and a generalization of cyclic lattices. Ideal lattices naturally occur in many parts of number theory, but also in other areas. In particular, they have a significant place in cryptography. Micciancio defined a generalization of cyclic lattices as ideal lattices. They can be used in cryptosystems to decrease by a square root the number of parameters necessary to describe a lattice, making them more efficient. Ideal lattices are a new concept, but similar lattice classes have been used for a long time. For example, cyclic lattices, a special case of ideal lattices, are used in NTRUEncrypt and NTRUSign.
















