
Supervised learning (SL) is the machine learning task of learning a function that maps an input to an output based on example input-output pairs. It infers a function from labeled training data consisting of a set of training examples. In supervised learning, each example is a pair consisting of an input object and a desired output value. A supervised learning algorithm analyzes the training data and produces an inferred function, which can be used for mapping new examples. An optimal scenario will allow for the algorithm to correctly determine the class labels for unseen instances. This requires the learning algorithm to generalize from the training data to unseen situations in a "reasonable" way. This statistical quality of an algorithm is measured through the so-called generalization error.
Pattern recognition is the automated recognition of patterns and regularities in data. It has applications in statistical data analysis, signal processing, image analysis, information retrieval, bioinformatics, data compression, computer graphics and machine learning. Pattern recognition has its origins in statistics and engineering; some modern approaches to pattern recognition include the use of machine learning, due to the increased availability of big data and a new abundance of processing power. These activities can be viewed as two facets of the same field of application, and they have undergone substantial development over the past few decades.
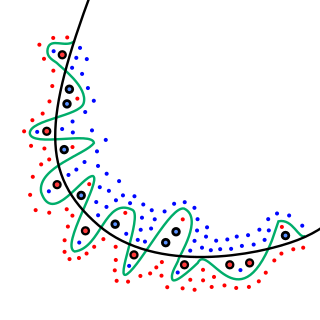
In mathematical modeling, overfitting is "the production of an analysis that corresponds too closely or exactly to a particular set of data, and may therefore fail to fit to additional data or predict future observations reliably". An overfitted model is a mathematical model that contains more parameters than can be justified by the data. The essence of overfitting is to have unknowingly extracted some of the residual variation as if that variation represented underlying model structure.
Machine learning (ML) is a field of inquiry devoted to understanding and building methods that 'learn', that is, methods that leverage data to improve performance on some set of tasks. It is seen as a part of artificial intelligence. Machine learning algorithms build a model based on sample data, known as training data, in order to make predictions or decisions without being explicitly programmed to do so. Machine learning algorithms are used in a wide variety of applications, such as in medicine, email filtering, speech recognition, and computer vision, where it is difficult or unfeasible to develop conventional algorithms to perform the needed tasks.
Unsupervised learning is a type of algorithm that learns patterns from untagged data. The hope is that through mimicry, which is an important mode of learning in people, the machine is forced to build a compact internal representation of its world and then generate imaginative content from it. In contrast to supervised learning where data is tagged by an expert, e.g. as a "ball" or "fish", unsupervised methods exhibit self-organization that captures patterns as probability densities or a combination of neural feature preferences. The other levels in the supervision spectrum are reinforcement learning where the machine is given only a numerical performance score as guidance, and semi-supervised learning where a smaller portion of the data is tagged.
In computer network research, network simulation is a technique whereby a software program replicates the behavior of a real network. This is achieved by calculating the interactions between the different network entities such as routers, switches, nodes, access points, links, etc. Most simulators use discrete event simulation in which the modeling of systems in which state variables change at discrete points in time. The behavior of the network and the various applications and services it supports can then be observed in a test lab; various attributes of the environment can also be modified in a controlled manner to assess how the network/protocols would behave under different conditions.
In machine learning, a common task is the study and construction of algorithms that can learn from and make predictions on data. Such algorithms function by making data-driven predictions or decisions, through building a mathematical model from input data. These input data used to build the model are usually divided in multiple data sets. In particular, three data sets are commonly used in different stages of the creation of the model: training, validation and test sets.

In data analysis, anomaly detection is generally understood to be the identification of rare items, events or observations which deviate significantly from the majority of the data and do not conform to a well defined notion of normal behaviour. Such examples may arouse suspicions of being generated by a different mechanism, or appear inconsistent with the remainder of that set of data.
Fault detection, isolation, and recovery (FDIR) is a subfield of control engineering which concerns itself with monitoring a system, identifying when a fault has occurred, and pinpointing the type of fault and its location. Two approaches can be distinguished: A direct pattern recognition of sensor readings that indicate a fault and an analysis of the discrepancy between the sensor readings and expected values, derived from some model. In the latter case, it is typical that a fault is said to be detected if the discrepancy or residual goes above a certain threshold. It is then the task of fault isolation to categorize the type of fault and its location in the machinery. Fault detection and isolation (FDI) techniques can be broadly classified into two categories. These include model-based FDI and signal processing based FDI.
Bayesian approaches to brain function investigate the capacity of the nervous system to operate in situations of uncertainty in a fashion that is close to the optimal prescribed by Bayesian statistics. This term is used in behavioural sciences and neuroscience and studies associated with this term often strive to explain the brain's cognitive abilities based on statistical principles. It is frequently assumed that the nervous system maintains internal probabilistic models that are updated by neural processing of sensory information using methods approximating those of Bayesian probability.
In network theory, link analysis is a data-analysis technique used to evaluate relationships (connections) between nodes. Relationships may be identified among various types of nodes (objects), including organizations, people and transactions. Link analysis has been used for investigation of criminal activity, computer security analysis, search engine optimization, market research, medical research, and art.
In machine learning, feature learning or representation learning is a set of techniques that allows a system to automatically discover the representations needed for feature detection or classification from raw data. This replaces manual feature engineering and allows a machine to both learn the features and use them to perform a specific task.

Land change models (LCMs) describe, project, and explain changes in and the dynamics of land use and land-cover. LCMs are a means of understanding ways that humans change the Earth's surface in the past, present, and future.
Neural architecture search (NAS) is a technique for automating the design of artificial neural networks (ANN), a widely used model in the field of machine learning. NAS has been used to design networks that are on par or outperform hand-designed architectures. Methods for NAS can be categorized according to the search space, search strategy and performance estimation strategy used:
Weak supervision is a branch of machine learning where noisy, limited, or imprecise sources are used to provide supervision signal for labeling large amounts of training data in a supervised learning setting. This approach alleviates the burden of obtaining hand-labeled data sets, which can be costly or impractical. Instead, inexpensive weak labels are employed with the understanding that they are imperfect, but can nonetheless be used to create a strong predictive model.

Y.3172 is an ITU-T Recommendation specifying an architecture for machine learning in future networks including 5G (IMT-2020). The architecture describes a machine learning pipeline in the context of telecommunication networks that involves the training of machine learning models, and also the deployment using methods such as containers and orchestration.
Y.3173 is an ITU-T Recommendation building upon Y.3172 specifying a framework for evaluation intelligence levels of future networks such as 5G (IMT-2020). This includes:
Y.3176 is an ITU-T Recommendation, building upon Y.3172 and Y.3173, specifying a framework for evaluation intelligence levels of future networks such as 5G (IMT-2020).
Applications of machine learning in earth sciences include geological mapping, gas leakage detection and geological features identification. Machine learning (ML) is a type of artificial intelligence (AI) that enables computer systems to classify, cluster, identify and analyze vast and complex sets of data while eliminating the need for explicit instructions and programming. Earth science is the study of the origin, evolution, and future of the planet Earth. The Earth system can be subdivided into four major components including the solid earth, atmosphere, hydrosphere and biosphere.