Neurocomputational speech processing topics
Neurocomputational speech processing is speech processing by artificial neural networks. Neural maps, mappings and pathways as described below, are model structures, i.e. important structures within artificial neural networks.
Neural maps
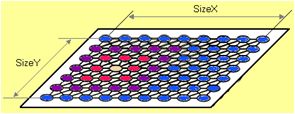
An artificial neural network can be separated in three types of neural maps, also called "layers":
- input maps (in the case of speech processing: primary auditory map within the auditory cortex, primary somatosensory map within the somatosensory cortex),
- output maps (primary motor map within the primary motor cortex), and
- higher level cortical maps (also called "hidden layers").
The term "neural map" is favoured here over the term "neural layer", because a cortical neural map should be modeled as a 2D-map of interconnected neurons (e.g. like a self-organizing map; see also Fig. 1). Thus, each "model neuron" or "artificial neuron" within this 2D-map is physiologically represented by a cortical column since the cerebral cortex anatomically exhibits a layered structure.
Neural representations (neural states)
A neural representation within an artificial neural network is a temporarily activated (neural) state within a specific neural map. Each neural state is represented by a specific neural activation pattern. This activation pattern changes during speech processing (e.g. from syllable to syllable).

In the ACT model (see below), it is assumed that an auditory state can be represented by a "neural spectrogram" (see Fig. 2) within an auditory state map. This auditory state map is assumed to be located in the auditory association cortex (see cerebral cortex).
A somatosensory state can be divided in a tactile and proprioceptive state and can be represented by a specific neural activation pattern within the somatosensory state map. This state map is assumed to be located in the somatosensory association cortex (see cerebral cortex, somatosensory system, somatosensory cortex).
A motor plan state can be assumed for representing a motor plan, i.e. the planning of speech articulation for a specific syllable or for a longer speech item (e.g. word, short phrase). This state map is assumed to be located in the premotor cortex, while the instantaneous (or lower level) activation of each speech articulator occurs within the primary motor cortex (see motor cortex).
The neural representations occurring in the sensory and motor maps (as introduced above) are distributed representations (Hinton et al. 1968 [5] ): Each neuron within the sensory or motor map is more or less activated, leading to a specific activation pattern.
The neural representation for speech units occurring in the speech sound map (see below: DIVA model) is a punctual or local representation. Each speech item or speech unit is represented here by a specific neuron (model cell, see below).
Neural mappings (synaptic projections)

A neural mapping connects two cortical neural maps. Neural mappings (in contrast to neural pathways) store training information by adjusting their neural link weights (see artificial neuron, artificial neural networks). Neural mappings are capable of generating or activating a distributed representation (see above) of a sensory or motor state within a sensory or motor map from a punctual or local activation within the other map (see for example the synaptic projection from speech sound map to motor map, to auditory target region map, or to somatosensory target region map in the DIVA model, explained below; or see for example the neural mapping from phonetic map to auditory state map and motor plan state map in the ACT model, explained below and Fig. 3).
Neural mapping between two neural maps are compact or dense: Each neuron of one neural map is interconnected with (nearly) each neuron of the other neural map (many-to-many-connection, see artificial neural networks). Because of this density criterion for neural mappings, neural maps which are interconnected by a neural mapping are not far apart from each other.
Neural pathways
In contrast to neural mappings neural pathways can connect neural maps which are far apart (e.g. in different cortical lobes, see cerebral cortex). From the functional or modeling viewpoint, neural pathways mainly forward information without processing this information. A neural pathway in comparison to a neural mapping need much less neural connections. A neural pathway can be modelled by using a one-to-one connection of the neurons of both neural maps (see topographic mapping and see somatotopic arrangement).
Example: In the case of two neural maps, each comprising 1,000 model neurons, a neural mapping needs up to 1,000,000 neural connections (many-to-many-connection), while only 1,000 connections are needed in the case of a neural pathway connection.
Furthermore, the link weights of the connections within a neural mapping are adjusted during training, while the neural connections in the case of a neural pathway need not to be trained (each connection is maximal exhibitory).



