Db2 is a family of data management products, including database servers, developed by IBM. It initially supported the relational model, but was extended to support object–relational features and non-relational structures like JSON and XML. The brand name was originally styled as DB2 until 2017, when it changed to its present form.
HBase is an open-source non-relational distributed database modeled after Google's Bigtable and written in Java. It is developed as part of Apache Software Foundation's Apache Hadoop project and runs on top of HDFS or Alluxio, providing Bigtable-like capabilities for Hadoop. That is, it provides a fault-tolerant way of storing large quantities of sparse data.

Cassandra is a free and open-source, distributed, wide-column store, NoSQL database management system designed to handle large amounts of data across many commodity servers, providing high availability with no single point of failure. Cassandra offers support for clusters spanning multiple data centers, with asynchronous masterless replication allowing low latency operations for all clients. Cassandra was designed to implement a combination of Amazon's Dynamo distributed storage and replication techniques combined with Google's Bigtable data and storage engine model.
The following tables compare general and technical information for a number of online analytical processing (OLAP) servers. Please see the individual products articles for further information.

Couchbase Server, originally known as Membase, is a source-available, distributed multi-model NoSQL document-oriented database software package optimized for interactive applications. These applications may serve many concurrent users by creating, storing, retrieving, aggregating, manipulating and presenting data. In support of these kinds of application needs, Couchbase Server is designed to provide easy-to-scale key-value, or JSON document access, with low latency and high sustainability throughput. It is designed to be clustered from a single machine to very large-scale deployments spanning many machines.

Apache Hive is a data warehouse software project, built on top of Apache Hadoop for providing data query and analysis. Hive gives an SQL-like interface to query data stored in various databases and file systems that integrate with Hadoop. Traditional SQL queries must be implemented in the MapReduce Java API to execute SQL applications and queries over distributed data. Hive provides the necessary SQL abstraction to integrate SQL-like queries into the underlying Java without the need to implement queries in the low-level Java API. Since most data warehousing applications work with SQL-based querying languages, Hive aids the portability of SQL-based applications to Hadoop. While initially developed by Facebook, Apache Hive is used and developed by other companies such as Netflix and the Financial Industry Regulatory Authority (FINRA). Amazon maintains a software fork of Apache Hive included in Amazon Elastic MapReduce on Amazon Web Services.

InfiniDB was a database management software company based in Frisco, Texas. The company developed InfiniDB, a scalable, software-only columnar database management system for analytic applications.

Actian Vector is an SQL relational database management system designed for high performance in analytical database applications. It published record breaking results on the Transaction Processing Performance Council's TPC-H benchmark for database sizes of 100 GB, 300 GB, 1 TB and 3 TB on non-clustered hardware.

SingleStore is a proprietary, cloud-native database designed for data-intensive applications. A distributed, relational, SQL database management system (RDBMS) that features ANSI SQL support, it is known for speed in data ingest, transaction processing, and query processing.

Apache Drill is an open-source software framework that supports data-intensive distributed applications for interactive analysis of large-scale datasets. Built chiefly by contributions from developers from MapR, Drill is inspired by Google's Dremel system. Drill is an Apache top-level project. Tom Shiran is the founder of the Apache Drill Project. It was designated an Apache Software Foundation top-level project in December 2016.

Oracle NoSQL Database is a NoSQL-type distributed key-value database from Oracle Corporation. It provides transactional semantics for data manipulation, horizontal scalability, and simple administration and monitoring.
Apache Impala is an open source massively parallel processing (MPP) SQL query engine for data stored in a computer cluster running Apache Hadoop. Impala has been described as the open-source equivalent of Google F1, which inspired its development in 2012.

Apache Spark is an open-source unified analytics engine for large-scale data processing. Spark provides an interface for programming clusters with implicit data parallelism and fault tolerance. Originally developed at the University of California, Berkeley's AMPLab, the Spark codebase was later donated to the Apache Software Foundation, which has maintained it since.
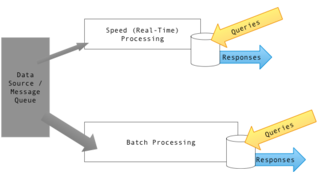
Lambda architecture is a data-processing architecture designed to handle massive quantities of data by taking advantage of both batch and stream-processing methods. This approach to architecture attempts to balance latency, throughput, and fault-tolerance by using batch processing to provide comprehensive and accurate views of batch data, while simultaneously using real-time stream processing to provide views of online data. The two view outputs may be joined before presentation. The rise of lambda architecture is correlated with the growth of big data, real-time analytics, and the drive to mitigate the latencies of map-reduce.
Presto is a distributed query engine for big data using the SQL query language. Its architecture allows users to query data sources such as Hadoop, Cassandra, Kafka, AWS S3, Alluxio, MySQL, MongoDB and Teradata, and allows use of multiple data sources within a query. Presto is community-driven open-source software released under the Apache License.
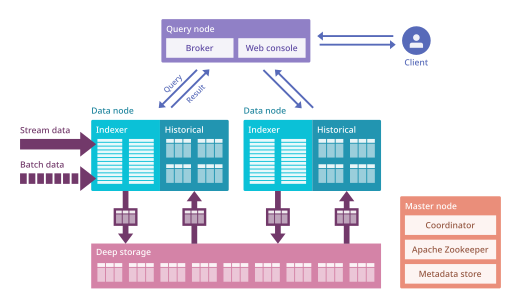
Imply Data, Inc. is an American software company. It develops and provides commercial support for the open-source Apache Druid, a real-time database designed to power analytics applications.

ClickHouse is an open-source column-oriented DBMS for online analytical processing (OLAP) that allows users to generate analytical reports using SQL queries in real-time. ClickHouse Inc. is headquartered in the San Francisco Bay Area with the subsidiary, ClickHouse B.V., based in Amsterdam, Netherlands.

Apache Ignite is a distributed database management system for high-performance computing.

Apache Pinot is a column-oriented, open-source, distributed data store written in Java. Pinot is designed to execute OLAP queries with low latency. It is suited in contexts where fast analytics, such as aggregations, are needed on immutable data, possibly, with real-time data ingestion. The name Pinot comes from the Pinot grape vines that are pressed into liquid that is used to produce a variety of different wines. The founders of the database chose the name as a metaphor for analyzing vast quantities of data from a variety of different file formats or streaming data sources.