Online analytical processing, or OLAP, is an approach to answer multi-dimensional analytical (MDA) queries swiftly in computing. OLAP is part of the broader category of business intelligence, which also encompasses relational databases, report writing and data mining. Typical applications of OLAP include business reporting for sales, marketing, management reporting, business process management (BPM), budgeting and forecasting, financial reporting and similar areas, with new applications emerging, such as agriculture.
In computer programming contexts, a data cube is a multi-dimensional ("n-D") array of values. Typically, the term data cube is applied in contexts where these arrays are massively larger than the hosting computer's main memory; examples include multi-terabyte/petabyte data warehouses and time series of image data.
Online transaction processing (OLTP) is a type of database system used in transaction-oriented applications, such as many operational systems. "Online" refers to that such systems are expected to respond to user requests and process them in real-time. The term is contrasted with online analytical processing (OLAP) which instead focuses on data analysis.
SAP IQ is a column-based, petabyte scale, relational database software system used for business intelligence, data warehousing, and data marts. Produced by Sybase Inc., now an SAP company, its primary function is to analyze large amounts of data in a low-cost, highly available environment. SAP IQ is often credited with pioneering the commercialization of column-store technology.
A database shard, or simply a shard, is a horizontal partition of data in a database or search engine. Each shard is held on a separate database server instance, to spread load.

Vertica is an analytic database management software company. Vertica was founded in 2005 by the database researcher Michael Stonebraker with Andrew Palmer as the founding CEO. Ralph Breslauer and Christopher P. Lynch served as CEOs later on.
The following tables compare general and technical information for a number of online analytical processing (OLAP) servers. Please see the individual products articles for further information.

Apache ZooKeeper is an open-source server for highly reliable distributed coordination of cloud applications. It is a project of the Apache Software Foundation.
HPCC, also known as DAS, is an open source, data-intensive computing system platform developed by LexisNexis Risk Solutions. The HPCC platform incorporates a software architecture implemented on commodity computing clusters to provide high-performance, data-parallel processing for applications utilizing big data. The HPCC platform includes system configurations to support both parallel batch data processing (Thor) and high-performance online query applications using indexed data files (Roxie). The HPCC platform also includes a data-centric declarative programming language for parallel data processing called ECL.

SingleStore is a proprietary, cloud-native database designed for data-intensive applications. A distributed, relational, SQL database management system (RDBMS) that features ANSI SQL support, it is known for speed in data ingest, transaction processing, and query processing.
NewSQL is a class of relational database management systems that seek to provide the scalability of NoSQL systems for online transaction processing (OLTP) workloads while maintaining the ACID guarantees of a traditional database system.

In computer science, the log-structured merge-tree is a data structure with performance characteristics that make it attractive for providing indexed access to files with high insert volume, such as transactional log data. LSM trees, like other search trees, maintain key-value pairs. LSM trees maintain data in two or more separate structures, each of which is optimized for its respective underlying storage medium; data is synchronized between the two structures efficiently, in batches.
Druid is a column-oriented, open-source, distributed data store written in Java. Druid is designed to quickly ingest massive quantities of event data, and provide low-latency queries on top of the data. The name Druid comes from the shapeshifting Druid class in many role-playing games, to reflect that the architecture of the system can shift to solve different types of data problems.

Apache Spark is an open-source unified analytics engine for large-scale data processing. Spark provides an interface for programming clusters with implicit data parallelism and fault tolerance. Originally developed at the University of California, Berkeley's AMPLab, the Spark codebase was later donated to the Apache Software Foundation, which has maintained it since.
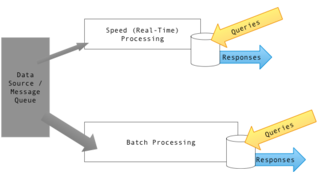
Lambda architecture is a data-processing architecture designed to handle massive quantities of data by taking advantage of both batch and stream-processing methods. This approach to architecture attempts to balance latency, throughput, and fault-tolerance by using batch processing to provide comprehensive and accurate views of batch data, while simultaneously using real-time stream processing to provide views of online data. The two view outputs may be joined before presentation. The rise of lambda architecture is correlated with the growth of big data, real-time analytics, and the drive to mitigate the latencies of map-reduce.

Apache Kylin is an open source distributed analytics engine designed to provide a SQL interface and multi-dimensional analysis (OLAP) on Hadoop and Alluxio supporting extremely large datasets.
Reynold Xin is a computer scientist and engineer specializing in big data, distributed systems, and cloud computing. He is a co-founder and Chief Architect of Databricks. He is best known for his work on Apache Spark, a leading open-source Big Data project. He was designer and lead developer of the GraphX, Project Tungsten, and Structured Streaming components and he co-designed DataFrames, all of which are part of the core Apache Spark distribution; he also served as the release manager for Spark's 2.0 release.

ClickHouse is an open-source column-oriented DBMS for online analytical processing (OLAP) that allows users to generate analytical reports using SQL queries in real-time. ClickHouse Inc. is headquartered in the San Francisco Bay Area with the subsidiary, ClickHouse B.V., based in Amsterdam, Netherlands.
Azure Data Explorer is a fully-managed big data analytics cloud platform and data-exploration service, developed by Microsoft, that ingests structured, semi-structured and unstructured data. The service then stores this data and answers analytic ad hoc queries on it with seconds of latency. It is a full text indexing and retrieval database, including time series analysis capabilities and regular expression evaluation and text parsing.