Discrete mathematics is the study of mathematical structures that can be considered "discrete" rather than "continuous". Objects studied in discrete mathematics include integers, graphs, and statements in logic. By contrast, discrete mathematics excludes topics in "continuous mathematics" such as real numbers, calculus or Euclidean geometry. Discrete objects can often be enumerated by integers; more formally, discrete mathematics has been characterized as the branch of mathematics dealing with countable sets. However, there is no exact definition of the term "discrete mathematics".

Probability theory or probability calculus is the branch of mathematics concerned with probability. Although there are several different probability interpretations, probability theory treats the concept in a rigorous mathematical manner by expressing it through a set of axioms. Typically these axioms formalise probability in terms of a probability space, which assigns a measure taking values between 0 and 1, termed the probability measure, to a set of outcomes called the sample space. Any specified subset of the sample space is called an event.
In probability theory and statistics, a probability distribution is the mathematical function that gives the probabilities of occurrence of different possible outcomes for an experiment. It is a mathematical description of a random phenomenon in terms of its sample space and the probabilities of events.
A random variable is a mathematical formalization of a quantity or object which depends on random events. The term 'random variable' can be misleading as its mathematical definition is not actually random nor a variable, but rather it is a function from possible outcomes in a sample space to a measurable space, often to the real numbers.
The likelihood function is the joint probability mass of observed data viewed as a function of the parameters of a statistical model. Intuitively, the likelihood function is the probability of observing data assuming is the actual parameter.
In probability theory and related fields, a stochastic or random process is a mathematical object usually defined as a sequence of random variables in a probability space, where the index of the sequence often has the interpretation of time. Stochastic processes are widely used as mathematical models of systems and phenomena that appear to vary in a random manner. Examples include the growth of a bacterial population, an electrical current fluctuating due to thermal noise, or the movement of a gas molecule. Stochastic processes have applications in many disciplines such as biology, chemistry, ecology, neuroscience, physics, image processing, signal processing, control theory, information theory, computer science, and telecommunications. Furthermore, seemingly random changes in financial markets have motivated the extensive use of stochastic processes in finance.

In probability and statistics, a probability mass function is a function that gives the probability that a discrete random variable is exactly equal to some value. Sometimes it is also known as the discrete probability density function. The probability mass function is often the primary means of defining a discrete probability distribution, and such functions exist for either scalar or multivariate random variables whose domain is discrete.

In statistics, the logistic model is a statistical model that models the log-odds of an event as a linear combination of one or more independent variables. In regression analysis, logistic regression is estimating the parameters of a logistic model. Formally, in binary logistic regression there is a single binary dependent variable, coded by an indicator variable, where the two values are labeled "0" and "1", while the independent variables can each be a binary variable or a continuous variable. The corresponding probability of the value labeled "1" can vary between 0 and 1, hence the labeling; the function that converts log-odds to probability is the logistic function, hence the name. The unit of measurement for the log-odds scale is called a logit, from logistic unit, hence the alternative names. See § Background and § Definition for formal mathematics, and § Example for a worked example.
A weight function is a mathematical device used when performing a sum, integral, or average to give some elements more "weight" or influence on the result than other elements in the same set. The result of this application of a weight function is a weighted sum or weighted average. Weight functions occur frequently in statistics and analysis, and are closely related to the concept of a measure. Weight functions can be employed in both discrete and continuous settings. They can be used to construct systems of calculus called "weighted calculus" and "meta-calculus".

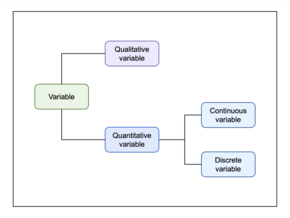
A variable is considered dependent if it depends on an independent variable. Dependent variables are studied under the supposition or demand that they depend, by some law or rule, on the values of other variables. Independent variables, in turn, are not seen as depending on any other variable in the scope of the experiment in question. In this sense, some common independent variables are time, space, density, mass, fluid flow rate, and previous values of some observed value of interest to predict future values.
In statistics, a categorical variable is a variable that can take on one of a limited, and usually fixed, number of possible values, assigning each individual or other unit of observation to a particular group or nominal category on the basis of some qualitative property. In computer science and some branches of mathematics, categorical variables are referred to as enumerations or enumerated types. Commonly, each of the possible values of a categorical variable is referred to as a level. The probability distribution associated with a random categorical variable is called a categorical distribution.

Given two random variables that are defined on the same probability space, the joint probability distribution is the corresponding probability distribution on all possible pairs of outputs. The joint distribution can just as well be considered for any given number of random variables. The joint distribution encodes the marginal distributions, i.e. the distributions of each of the individual random variables and the conditional probability distributions, which deal with how the outputs of one random variable are distributed when given information on the outputs of the other random variable(s).

Mathematical statistics is the application of probability theory, a branch of mathematics, to statistics, as opposed to techniques for collecting statistical data. Specific mathematical techniques which are used for this include mathematical analysis, linear algebra, stochastic analysis, differential equations, and measure theory.
This glossary of statistics and probability is a list of definitions of terms and concepts used in the mathematical sciences of statistics and probability, their sub-disciplines, and related fields. For additional related terms, see Glossary of mathematics and Glossary of experimental design.
In mathematics, a variable is a symbol that represents a mathematical object. A variable may represent a number, a vector, a matrix, a function, the argument of a function, a set, or an element of a set.
In probability theory, random element is a generalization of the concept of random variable to more complicated spaces than the simple real line. The concept was introduced by Maurice Fréchet (1948) who commented that the “development of probability theory and expansion of area of its applications have led to necessity to pass from schemes where (random) outcomes of experiments can be described by number or a finite set of numbers, to schemes where outcomes of experiments represent, for example, vectors, functions, processes, fields, series, transformations, and also sets or collections of sets.”
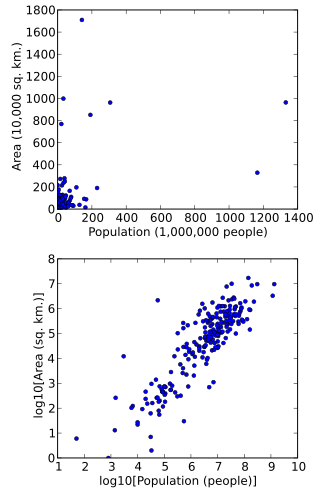
In statistics, data transformation is the application of a deterministic mathematical function to each point in a data set—that is, each data point zi is replaced with the transformed value yi = f(zi), where f is a function. Transforms are usually applied so that the data appear to more closely meet the assumptions of a statistical inference procedure that is to be applied, or to improve the interpretability or appearance of graphs.
In mathematical dynamics, discrete time and continuous time are two alternative frameworks within which variables that evolve over time are modeled.
In statistics, linear regression is a statistical model which estimates the linear relationship between a scalar response and one or more explanatory variables. The case of one explanatory variable is called simple linear regression; for more than one, the process is called multiple linear regression. This term is distinct from multivariate linear regression, where multiple correlated dependent variables are predicted, rather than a single scalar variable. If the explanatory variables are measured with error then errors-in-variables models are required, also known as measurement error models.