
In celestial mechanics, an orbit is the curved trajectory of an object such as the trajectory of a planet around a star, or of a natural satellite around a planet, or of an artificial satellite around an object or position in space such as a planet, moon, asteroid, or Lagrange point. Normally, orbit refers to a regularly repeating trajectory, although it may also refer to a non-repeating trajectory. To a close approximation, planets and satellites follow elliptic orbits, with the center of mass being orbited at a focal point of the ellipse, as described by Kepler's laws of planetary motion.
The likelihood function is the joint probability of observed data viewed as a function of the parameters of a statistical model.

The Navier–Stokes equations are partial differential equations which describe the motion of viscous fluid substances. They were named after French engineer and physicist Claude-Louis Navier and the Irish physicist and mathematician George Gabriel Stokes. They were developed over several decades of progressively building the theories, from 1822 (Navier) to 1842–1850 (Stokes).
Bayesian inference is a method of statistical inference in which Bayes' theorem is used to update the probability for a hypothesis as more evidence or information becomes available. Fundamentally, Bayesian inference uses prior knowledge, in the form of a prior distribution in order to estimate posterior probabilities. Bayesian inference is an important technique in statistics, and especially in mathematical statistics. Bayesian updating is particularly important in the dynamic analysis of a sequence of data. Bayesian inference has found application in a wide range of activities, including science, engineering, philosophy, medicine, sport, and law. In the philosophy of decision theory, Bayesian inference is closely related to subjective probability, often called "Bayesian probability".
Pattern recognition is the task of assigning a class to an observation based on patterns extracted from data. While similar, pattern recognition (PR) is not to be confused with pattern machines (PM) which may possess (PR) capabilities but their primary function is to distinguish and create emergent pattern. PR has applications in statistical data analysis, signal processing, image analysis, information retrieval, bioinformatics, data compression, computer graphics and machine learning. Pattern recognition has its origins in statistics and engineering; some modern approaches to pattern recognition include the use of machine learning, due to the increased availability of big data and a new abundance of processing power.
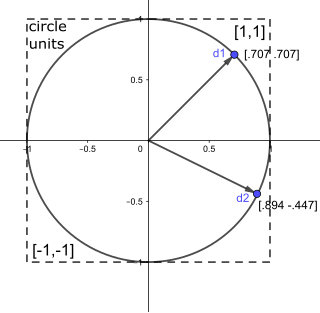
In mathematics, a unit vector in a normed vector space is a vector of length 1. A unit vector is often denoted by a lowercase letter with a circumflex, or "hat", as in .

In statistics, the logistic model is a statistical model that models the log-odds of an event as a linear combination of one or more independent variables. In regression analysis, logistic regression is estimating the parameters of a logistic model. Formally, in binary logistic regression there is a single binary dependent variable, coded by an indicator variable, where the two values are labeled "0" and "1", while the independent variables can each be a binary variable or a continuous variable. The corresponding probability of the value labeled "1" can vary between 0 and 1, hence the labeling; the function that converts log-odds to probability is the logistic function, hence the name. The unit of measurement for the log-odds scale is called a logit, from logistic unit, hence the alternative names. See § Background and § Definition for formal mathematics, and § Example for a worked example.

In mathematical optimization and decision theory, a loss function or cost function is a function that maps an event or values of one or more variables onto a real number intuitively representing some "cost" associated with the event. An optimization problem seeks to minimize a loss function. An objective function is either a loss function or its opposite, in which case it is to be maximized. The loss function could include terms from several levels of the hierarchy.

In statistics, an expectation–maximization (EM) algorithm is an iterative method to find (local) maximum likelihood or maximum a posteriori (MAP) estimates of parameters in statistical models, where the model depends on unobserved latent variables. The EM iteration alternates between performing an expectation (E) step, which creates a function for the expectation of the log-likelihood evaluated using the current estimate for the parameters, and a maximization (M) step, which computes parameters maximizing the expected log-likelihood found on the E step. These parameter-estimates are then used to determine the distribution of the latent variables in the next E step. It can be used, for example, to estimate a mixture of gaussians, or to solve the multiple linear regression problem.
In statistics, a generalized linear model (GLM) is a flexible generalization of ordinary linear regression. The GLM generalizes linear regression by allowing the linear model to be related to the response variable via a link function and by allowing the magnitude of the variance of each measurement to be a function of its predicted value.
In statistics, the theory of minimum norm quadratic unbiased estimation (MINQUE) was developed by C. R. Rao. MINQUE is a theory alongside other estimation methods in estimation theory, such as the method of moments or maximum likelihood estimation. Similar to the theory of best linear unbiased estimation, MINQUE is specifically concerned with linear regression models. The method was originally conceived to estimate heteroscedastic error variance in multiple linear regression. MINQUE estimators also provide an alternative to maximum likelihood estimators or restricted maximum likelihood estimators for variance components in mixed effects models. MINQUE estimators are quadratic forms of the response variable and are used to estimate a linear function of the variances.

In mathematics, the Ornstein–Uhlenbeck process is a stochastic process with applications in financial mathematics and the physical sciences. Its original application in physics was as a model for the velocity of a massive Brownian particle under the influence of friction. It is named after Leonard Ornstein and George Eugene Uhlenbeck.
In statistics, the generalized linear array model (GLAM) is used for analyzing data sets with array structures. It based on the generalized linear model with the design matrix written as a Kronecker product.
Non-linear least squares is the form of least squares analysis used to fit a set of m observations with a model that is non-linear in n unknown parameters (m ≥ n). It is used in some forms of nonlinear regression. The basis of the method is to approximate the model by a linear one and to refine the parameters by successive iterations. There are many similarities to linear least squares, but also some significant differences. In economic theory, the non-linear least squares method is applied in (i) the probit regression, (ii) threshold regression, (iii) smooth regression, (iv) logistic link regression, (v) Box–Cox transformed regressors ().
Gradient-enhanced kriging (GEK) is a surrogate modeling technique used in engineering. A surrogate model is a prediction of the output of an expensive computer code. This prediction is based on a small number of evaluations of the expensive computer code.
SAMV is a parameter-free superresolution algorithm for the linear inverse problem in spectral estimation, direction-of-arrival (DOA) estimation and tomographic reconstruction with applications in signal processing, medical imaging and remote sensing. The name was coined in 2013 to emphasize its basis on the asymptotically minimum variance (AMV) criterion. It is a powerful tool for the recovery of both the amplitude and frequency characteristics of multiple highly correlated sources in challenging environments. Applications include synthetic-aperture radar, computed tomography scan, and magnetic resonance imaging (MRI).
Stochastic gradient Langevin dynamics (SGLD) is an optimization and sampling technique composed of characteristics from Stochastic gradient descent, a Robbins–Monro optimization algorithm, and Langevin dynamics, a mathematical extension of molecular dynamics models. Like stochastic gradient descent, SGLD is an iterative optimization algorithm which uses minibatching to create a stochastic gradient estimator, as used in SGD to optimize a differentiable objective function. Unlike traditional SGD, SGLD can be used for Bayesian learning as a sampling method. SGLD may be viewed as Langevin dynamics applied to posterior distributions, but the key difference is that the likelihood gradient terms are minibatched, like in SGD. SGLD, like Langevin dynamics, produces samples from a posterior distribution of parameters based on available data. First described by Welling and Teh in 2011, the method has applications in many contexts which require optimization, and is most notably applied in machine learning problems.

The hyperbolastic functions, also known as hyperbolastic growth models, are mathematical functions that are used in medical statistical modeling. These models were originally developed to capture the growth dynamics of multicellular tumor spheres, and were introduced in 2005 by Mohammad Tabatabai, David Williams, and Zoran Bursac. The precision of hyperbolastic functions in modeling real world problems is somewhat due to their flexibility in their point of inflection. These functions can be used in a wide variety of modeling problems such as tumor growth, stem cell proliferation, pharma kinetics, cancer growth, sigmoid activation function in neural networks, and epidemiological disease progression or regression.
Bayesian history matching is a statistical method for calibrating complex computer models. The equations inside many scientific computer models contain parameters which have a true value, but that true value is often unknown; history matching is one technique for learning what these parameters could be.
Integrated nested Laplace approximations (INLA) is a method for approximate Bayesian inference based on Laplace's method. It is designed for a class of models called latent Gaussian models (LGMs), for which it can be a fast and accurate alternative for Markov chain Monte Carlo methods to compute posterior marginal distributions. Due to its relative speed even with large data sets for certain problems and models, INLA has been a popular inference method in applied statistics, in particular spatial statistics, ecology, and epidemiology. It is also possible to combine INLA with a finite element method solution of a stochastic partial differential equation to study e.g. spatial point processes and species distribution models. The INLA method is implemented in the R-INLA R package.


























