Related Research Articles
ISO/IEC 8859-3:1999, Information technology — 8-bit single-byte coded graphic character sets — Part 3: Latin alphabet No. 3, is part of the ISO/IEC 8859 series of ASCII-based standard character encodings, first edition published in 1988. It is informally referred to as Latin-3 or South European. It was designed to cover Turkish, Maltese and Esperanto, though the introduction of ISO/IEC 8859-9 superseded it for Turkish. The encoding was popular for users of Esperanto, but fell out of use as application support for Unicode became more common.

Windows-1252 or CP-1252 is a single-byte character encoding of the Latin alphabet, used by default in the legacy components of Microsoft Windows for English and many European languages including Spanish, French, and German.
ISO/IEC 8859-11:2001, Information technology — 8-bit single-byte coded graphic character sets — Part 11: Latin/Thai alphabet, is part of the ISO/IEC 8859 series of ASCII-based standard character encodings, first edition published in 2001. It is informally referred to as Latin/Thai. It is nearly identical to the national Thai standard TIS-620 (1990). The sole difference is that ISO/IEC 8859-11 allocates non-breaking space to code 0xA0, while TIS-620 leaves it undefined.
ISO/IEC 8859-4:1998, Information technology — 8-bit single-byte coded graphic character sets — Part 4: Latin alphabet No. 4, is part of the ISO/IEC 8859 series of ASCII-based standard character encodings, first edition published in 1988. It is informally referred to as Latin-4 or North European. It was designed to cover Estonian, Latvian, Lithuanian, Greenlandic, and Sami. It has been largely superseded by ISO/IEC 8859-10 and Unicode. Microsoft has assigned code page 28594 a.k.a. Windows-28594 to ISO-8859-4 in Windows. IBM has assigned code page 914 to ISO 8859-4.
ISO/IEC 8859-7:2003, Information technology — 8-bit single-byte coded graphic character sets — Part 7: Latin/Greek alphabet, is part of the ISO/IEC 8859 series of ASCII-based standard character encodings, first edition published in 1987. It is informally referred to as Latin/Greek. It was designed to cover the modern Greek language. The original 1987 version of the standard had the same character assignments as the Greek national standard ELOT 928, published in 1986. The table in this article shows the updated 2003 version which adds three characters. Microsoft has assigned code page 28597 a.k.a. Windows-28597 to ISO-8859-7 in Windows. IBM has assigned code page 813 to ISO 8859-7. (IBM CCSID 813 is the original encoding. CCSID 4909 adds the euro sign. CCSID 9005 further adds the drachma sign and ypogegrammeni.)
ISO/IEC 8859-9:1999, Information technology — 8-bit single-byte coded graphic character sets — Part 9: Latin alphabet No. 5, is part of the ISO/IEC 8859 series of ASCII-based standard character encodings, first edition published in 1989. It is informally referred to as Latin-5 or Turkish. It was designed to cover the Turkish language, designed as being of more use than the ISO/IEC 8859-3 encoding. It is identical to ISO/IEC 8859-1 except for these six replacements of Icelandic characters with characters unique to the Turkish alphabet:
Windows-1258 is a code page used in Microsoft Windows to represent Vietnamese texts. It makes use of combining diacritical marks.
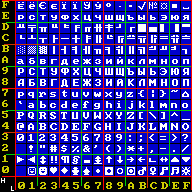
Code page 866 is a code page used under DOS and OS/2 in Russia to write Cyrillic script. It is based on the "alternative code page" developed in 1984 in IHNA AS USSR and published in 1986 by a research group at the Academy of Science of the USSR. The code page was widely used during the DOS era because it preserves all of the pseudographic symbols of code page 437 and maintains alphabetic order of Cyrillic letters. Initially, this encoding was only available in the Russian version of MS-DOS 4.01 (1990) and since MS-DOS 6.22 in any language version.
Windows-1254 is a code page used under Microsoft Windows to write Turkish. Characters with codepoints A0 through FF are compatible with ISO 8859-9, but the CR range, which is reserved for C1 control codes in ISO 8859, is instead used for additional characters.
Windows-1256 is a code page used under Microsoft Windows to write Arabic and other languages that use Arabic script, such as Persian and Urdu.
Windows-1257 is an 8-bit, single-byte extended ASCII code page used to support the Estonian, Latvian and Lithuanian languages under Microsoft Windows. In Lithuania, it is standardised as LST 1590-3, alongside a modified variant named LST 1590-4.
Code page 852 is a code page used under DOS to write Central European languages that use Latin script.

Code page 950 is the code page used on Microsoft Windows for Traditional Chinese. It is Microsoft's implementation of the de facto standard Big5 character encoding. The code page is not registered with IANA, and hence, it is not a standard to communicate information over the internet, although it is usually labelled simply as big5, including by Microsoft library functions.

Unified Hangul Code (UHC), or Extended Wansung, also known under Microsoft Windows as Code Page 949, is the Microsoft Windows code page for the Korean language. It is an extension of Wansung Code to include all 11172 non-partial Hangul syllables present in Johab. This corresponds to the pre-composed syllables available in Unicode 2.0 and later.
Code page 951 is a code page number used for different purposes by IBM and Microsoft.
Code page 896, called Japan 7-Bit Katakana Extended, is IBM's code page for code-set G2 of EUC-JP, a 7-bit code page representing the Kana set of JIS X 0201 and accompanying Code page 895 which corresponds to the lower half of that standard. It encodes half-width katakana.
Code page 903 is encoded for use as the single byte component of certain simplified Chinese character encodings. It is used in China. Despite this, it follows ISO 646-JP / the Roman half of JIS X 0201, in that it replaces the ASCII backslash 0x5C with the yen/yuan sign. It also uses the same C0 replacement graphics as code page 897. When combined with the double-byte Code page 928, it forms the two code-sets of IBM code page 936.
Code page 1043, also known as Traditional Chinese PC Data Extended, is a single byte character set (SBCS) used by IBM in its PC DOS operating system. This code page is intended for use with code page 927. It is an extension of Code page 904.
Code page 1115, also known as Simplified Chinese PC Data, is a single byte character set (SBCS) used by IBM in its PC DOS operating system in China.
Several mutually incompatible versions of the Extended Binary Coded Decimal Interchange Code (EBCDIC) have been used to represent the Japanese language on computers, including variants defined by Hitachi, Fujitsu, IBM and others. Some are variable-width encodings, employing locking shift codes to switch between single-byte and double-byte modes. Unlike other EBCDIC locales, the lowercase basic Latin letters are often not preserved in their usual locations.
References
- ↑ Character Sets, Internet Assigned Numbers Authority (IANA), 2018-12-12
- ↑ "CCSID 904 information document". Archived from the original on 2016-03-27.
- ↑ Code Page CPGID 00904 (pdf) (PDF), IBM
- ↑ Code Page CPGID 00904 (txt), IBM