
ISO/IEC 8859-1:1998, Information technology — 8-bit single-byte coded graphic character sets — Part 1: Latin alphabet No. 1, is part of the ISO/IEC 8859 series of ASCII-based standard character encodings, first edition published in 1987. ISO/IEC 8859-1 encodes what it refers to as "Latin alphabet no. 1", consisting of 191 characters from the Latin script. This character-encoding scheme is used throughout the Americas, Western Europe, Oceania, and much of Africa. It is the basis for some popular 8-bit character sets and the first two blocks of characters in Unicode.
Big-5 or Big5 is a Chinese character encoding method used in Taiwan, Hong Kong, and Macau for traditional Chinese characters.
In computing, a code page is a character encoding and as such it is a specific association of a set of printable characters and control characters with unique numbers. Typically each number represents the binary value in a single byte.
ISO/IEC 8859-11:2001, Information technology — 8-bit single-byte coded graphic character sets — Part 11: Latin/Thai alphabet, is part of the ISO/IEC 8859 series of ASCII-based standard character encodings, first edition published in 2001. It is informally referred to as Latin/Thai. It is nearly identical to the national Thai standard TIS-620 (1990). The sole difference is that ISO/IEC 8859-11 allocates non-breaking space to code 0xA0, while TIS-620 leaves it undefined.
ISO/IEC 8859-6:1999, Information technology — 8-bit single-byte coded graphic character sets — Part 6: Latin/Arabic alphabet, is part of the ISO/IEC 8859 series of ASCII-based standard character encodings, first edition published in 1987. It is informally referred to as Latin/Arabic. It was designed to cover Arabic. Only nominal letters are encoded, no preshaped forms of the letters, so shaping processing is required for display. It does not include the extra letters needed to write most Arabic-script languages other than Arabic itself.
ISO/IEC 8859-9:1999, Information technology — 8-bit single-byte coded graphic character sets — Part 9: Latin alphabet No. 5, is part of the ISO/IEC 8859 series of ASCII-based standard character encodings, first edition published in 1989. It is designated ECMA-128 by Ecma International and TS 5881 as a Turkish standard. It is informally referred to as Latin-5 or Turkish. It was designed to cover the Turkish language, designed as being of more use than the ISO/IEC 8859-3 encoding. It is identical to ISO/IEC 8859-1 except for the replacement of six Icelandic characters with characters unique to the Turkish alphabet. And the uppercase of i is İ; the lowercase of I is ı.
Extended Unix Code (EUC) is a multibyte character encoding system used primarily for Japanese, Korean, and simplified Chinese (characters).
Windows-1251 is an 8-bit character encoding, designed to cover languages that use the Cyrillic script such as Russian, Ukrainian, Belarusian, Bulgarian, Serbian Cyrillic, Macedonian and other languages.
Windows-1250 is a code page used under Microsoft Windows to represent texts in Central European and Eastern European languages that use the Latin script. It is primarily used by Czech, though Czech has now moved to UTF-8 and mostly abandoned this legacy encoding. It is also used for Polish, Slovak, Hungarian, Slovene, Serbo-Croatian, Romanian, Rotokas and Albanian. It may also be used with the German language, though it's missing uppercase ẞ. German-language texts encoded with Windows-1250 and Windows-1252 are identical.
Windows code page 1253, commonly known by its IANA-registered name Windows-1253 or abbreviated as cp1253, is a Microsoft Windows code page used to write modern Greek. It is not capable of supporting the older polytonic Greek.
Windows-1254 is a code page used under Microsoft Windows, to write Turkish that it was designed for. Characters with codepoints A0 through FF are compatible with ISO 8859-9, but the CR range, which is reserved for C1 control codes in ISO 8859, is instead used for additional characters. It matches Windows-1252 except for the replacement of six Icelandic characters with characters unique to the Turkish alphabet.
Windows-1255 is a code page used under Microsoft Windows to write Hebrew. It is an almost compatible superset of ISO-8859-8 – most of the symbols are in the same positions, but Windows-1255 adds vowel-points and other signs in lower positions.
Windows-1256 is a code page used under Microsoft Windows to write Arabic and other languages that use Arabic script, such as Persian and Urdu.
Windows-1257 is an 8-bit, single-byte extended ASCII code page used to support the Estonian, Latvian and Lithuanian languages under Microsoft Windows. In Lithuania, it is standardised as LST 1590-3, alongside a modified variant named LST 1590-4.
Mac OS Central European is a character encoding used on Apple Macintosh computers to represent texts in Central European and Southeastern European languages that use the Latin script. This encoding is also known as Code Page 10029. IBM assigns code page/CCSID 1282 to this encoding. This codepage contains diacritical letters that ISO 8859-2 does not have, and vice versa.
The currency sign¤ is a character used to denote an unspecified currency. It can be described as a circle the size of a lowercase character with four short radiating arms at 45° (NE), 135° (SE), 225° (SW) and 315° (NW). It is raised slightly above the baseline. The character is sometimes called scarab.
Several 8-bit character sets (encodings) were designed for binary representation of common Western European languages, which use the Latin alphabet, a few additional letters and ones with precomposed diacritics, some punctuation, and various symbols. These character sets also happen to support many other languages such as Malay, Swahili, and Classical Latin.
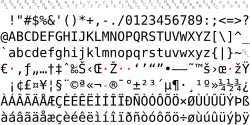
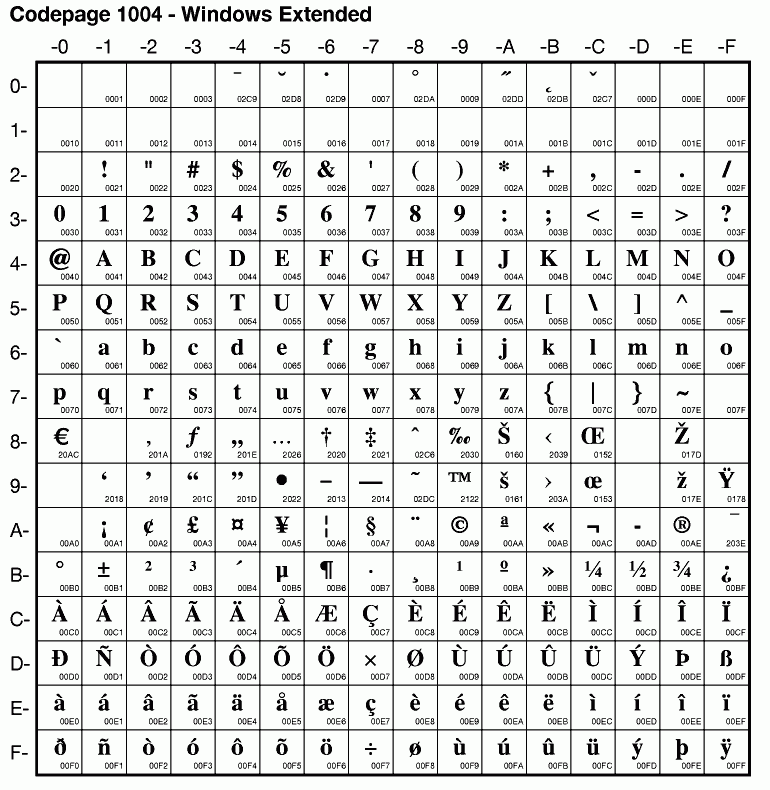
Windows code pages are sets of characters or code pages used in Microsoft Windows from the 1980s and 1990s. Windows code pages were gradually superseded when Unicode was implemented in Windows, although they are still supported both within Windows and other platforms, and still apply when Alt code shortcuts are used.

Extended ASCII is a repertoire of character encodings that include the original 96 ASCII character set, plus up to 128 additional characters. There is no formal definition of "extended ASCII", and even use of the term is sometimes criticized, because it can be mistakenly interpreted to mean that the American National Standards Institute (ANSI) had updated its ANSI X3.4-1986 standard to include more characters, or that the term identifies a single unambiguous encoding, neither of which is the case.

IBM code page 949 (IBM-949) is a character encoding which has been used by IBM to represent Korean language text on computers. It is a variable-width encoding which represents the characters from the Wansung code defined by the South Korean standard KS X 1001 in a format compatible with EUC-KR, but adds IBM extensions for additional hanja, additional precomposed Hangul syllables, and user-defined characters.
{kind=link}
{kind=link}