Related Research Articles
In information theory, data compression, source coding, or bit-rate reduction is the process of encoding information using fewer bits than the original representation. Any particular compression is either lossy or lossless. Lossless compression reduces bits by identifying and eliminating statistical redundancy. No information is lost in lossless compression. Lossy compression reduces bits by removing unnecessary or less important information. Typically, a device that performs data compression is referred to as an encoder, and one that performs the reversal of the process (decompression) as a decoder.

In information technology, lossy compression or irreversible compression is the class of data compression methods that uses inexact approximations and partial data discarding to represent the content. These techniques are used to reduce data size for storing, handling, and transmitting content. The different versions of the photo of the cat on this page show how higher degrees of approximation create coarser images as more details are removed. This is opposed to lossless data compression which does not degrade the data. The amount of data reduction possible using lossy compression is much higher than using lossless techniques.
MPEG-1 is a standard for lossy compression of video and audio. It is designed to compress VHS-quality raw digital video and CD audio down to about 1.5 Mbit/s without excessive quality loss, making video CDs, digital cable/satellite TV and digital audio broadcasting (DAB) practical.
Speech coding is an application of data compression to digital audio signals containing speech. Speech coding uses speech-specific parameter estimation using audio signal processing techniques to model the speech signal, combined with generic data compression algorithms to represent the resulting modeled parameters in a compact bitstream.

Image compression is a type of data compression applied to digital images, to reduce their cost for storage or transmission. Algorithms may take advantage of visual perception and the statistical properties of image data to provide superior results compared with generic data compression methods which are used for other digital data.

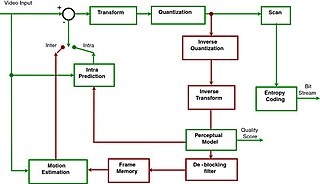
Motion compensation in computing is an algorithmic technique used to predict a frame in a video given the previous and/or future frames by accounting for motion of the camera and/or objects in the video. It is employed in the encoding of video data for video compression, for example in the generation of MPEG-2 files. Motion compensation describes a picture in terms of the transformation of a reference picture to the current picture. The reference picture may be previous in time or even from the future. When images can be accurately synthesized from previously transmitted/stored images, the compression efficiency can be improved.

A video codec is software or hardware that compresses and decompresses digital video. In the context of video compression, codec is a portmanteau of encoder and decoder, while a device that only compresses is typically called an encoder, and one that only decompresses is a decoder.
G.711 is a narrowband audio codec originally designed for use in telephony that provides toll-quality audio at 64 kbit/s. It is an ITU-T standard (Recommendation) for audio encoding, titled Pulse code modulation (PCM) of voice frequencies released for use in 1972.
Advanced Video Coding (AVC), also referred to as H.264 or MPEG-4 Part 10, is a video compression standard based on block-oriented, motion-compensated coding. It is by far the most commonly used format for the recording, compression, and distribution of video content, used by 91% of video industry developers as of September 2019. It supports a maximum resolution of 8K UHD.
H.261 is an ITU-T video compression standard, first ratified in November 1988. It is the first member of the H.26x family of video coding standards in the domain of the ITU-T Study Group 16 Video Coding Experts Group. It was the first video coding standard that was useful in practical terms.
H.262 or MPEG-2 Part 2 is a video coding format standardised and jointly maintained by ITU-T Study Group 16 Video Coding Experts Group (VCEG) and ISO/IEC Moving Picture Experts Group (MPEG), and developed with the involvement of many companies. It is the second part of the ISO/IEC MPEG-2 standard. The ITU-T Recommendation H.262 and ISO/IEC 13818-2 documents are identical.
Video quality is a characteristic of a video passed through a video transmission or processing system that describes perceived video degradation. Video processing systems may introduce some amount of distortion or artifacts in the video signal that negatively impact the user's perception of the system. For many stakeholders in video production and distribution, ensuring video quality is an important task.
Α video codec is software or a device that provides encoding and decoding for digital video, and which may or may not include the use of video compression and/or decompression. Most codecs are typically implementations of video coding formats.
The Video Coding Experts Group or Visual Coding Experts Group is a working group of the ITU Telecommunication Standardization Sector (ITU-T) concerned with standards for compression coding of video, images, audio, and other signals. It is responsible for standardization of the "H.26x" line of video coding standards, the "T.8xx" line of image coding standards, and related technologies.
Intra-frame coding is a data compression technique used within a video frame, enabling smaller file sizes and lower bitrates, with little or no loss in quality. Since neighboring pixels within an image are often very similar, rather than storing each pixel independently, the frame image is divided into blocks and the typically minor difference between each pixel can be encoded using fewer bits.
Adaptive differential pulse-code modulation (ADPCM) is a variant of differential pulse-code modulation (DPCM) that varies the size of the quantization step, to allow further reduction of the required data bandwidth for a given signal-to-noise ratio.
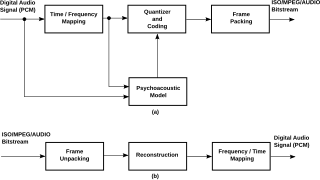
In signal processing, sub-band coding (SBC) is any form of transform coding that breaks a signal into a number of different frequency bands, typically by using a fast Fourier transform, and encodes each one independently. This decomposition is often the first step in data compression for audio and video signals.
A video coding format is a content representation format of digital video content, such as in a data file or bitstream. It typically uses a standardized video compression algorithm, most commonly based on discrete cosine transform (DCT) coding and motion compensation. A specific software, firmware, or hardware implementation capable of compression or decompression in a specific video coding format is called a video codec.
ZPEG is a motion video technology that applies a human visual acuity model to a decorrelated transform-domain space, thereby optimally reducing the redundancies in motion video by removing the subjectively imperceptible. This technology is applicable to a wide range of video processing problems such as video optimization, real-time motion video compression, subjective quality monitoring, and format conversion.
JPEG XS is an interoperable, visually lossless, low-latency and lightweight image and video coding system used in professional applications. Applications of the standard include streaming high quality content for virtual reality, drones, autonomous vehicles using cameras, gaming, and broadcasting. It was the first ISO codec ever designed for this specific purpose. JPEG XS, built on core technology from both intoPIX and Fraunhofer IIS, is formally standardized as ISO/IEC 21122 by the Joint Photographic Experts Group with the first edition published in 2019. Although not official, the XS acronym was chosen to highlight the eXtra Small and eXtra Speed characteristics of the codec. Today, the JPEG committee is still actively working on further improvements to XS, with the second edition scheduled for publication and initial efforts being launched towards a third edition.