A distributed system is a system whose components are located on different networked computers, which communicate and coordinate their actions by passing messages to one another. Distributed computing is a field of computer science that studies distributed systems.

The Harvard architecture is a computer architecture with separate storage and signal pathways for instructions and data. It is often contrasted with the von Neumann architecture, where program instructions and data share the same memory and pathways.

Static random-access memory is a type of random-access memory (RAM) that uses latching circuitry (flip-flop) to store each bit. SRAM is volatile memory; data is lost when power is removed.

Parallel computing is a type of computation in which many calculations or processes are carried out simultaneously. Large problems can often be divided into smaller ones, which can then be solved at the same time. There are several different forms of parallel computing: bit-level, instruction-level, data, and task parallelism. Parallelism has long been employed in high-performance computing, but has gained broader interest due to the physical constraints preventing frequency scaling. As power consumption by computers has become a concern in recent years, parallel computing has become the dominant paradigm in computer architecture, mainly in the form of multi-core processors.
In computer science, a parallel algorithm, as opposed to a traditional serial algorithm, is an algorithm which can do multiple operations in a given time. It has been a tradition of computer science to describe serial algorithms in abstract machine models, often the one known as random-access machine. Similarly, many computer science researchers have used a so-called parallel random-access machine (PRAM) as a parallel abstract machine (shared-memory).
In computer operating systems, memory paging is a memory management scheme by which a computer stores and retrieves data from secondary storage for use in main memory. In this scheme, the operating system retrieves data from secondary storage in same-size blocks called pages. Paging is an important part of virtual memory implementations in modern operating systems, using secondary storage to let programs exceed the size of available physical memory.

Theoretical computer science (TCS) is a subset of general computer science and mathematics that focuses on mathematical aspects of computer science such as the theory of computation, formal language theory, the lambda calculus and type theory.
In 3D computer graphics, solid objects are usually modeled by polyhedra. A face of a polyhedron is a planar polygon bounded by straight line segments, called edges. Curved surfaces are usually approximated by a polygon mesh. Computer programs for line drawings of opaque objects must be able to decide which edges or which parts of the edges are hidden by an object itself or by other objects, so that those edges can be clipped during rendering. This problem is known as hidden-line removal.

In computer science, concurrency is the ability of different parts or units of a program, algorithm, or problem to be executed out-of-order or in partial order, without affecting the outcome. This allows for parallel execution of the concurrent units, which can significantly improve overall speed of the execution in multi-processor and multi-core systems. In more technical terms, concurrency refers to the decomposability of a program, algorithm, or problem into order-independent or partially-ordered components or units of computation.
In parallel algorithms, the list ranking problem involves determining the position, or rank, of each item in a linked list. That is, the first item in the list should be assigned the number 1, the second item in the list should be assigned the number 2, etc. Although it is straightforward to solve this problem efficiently on a sequential computer, by traversing the list in order, it is more complicated to solve in parallel. As Anderson & Miller (1990) wrote, the problem was viewed as important in the parallel algorithms community both for its many applications and because solving it led to many important ideas that could be applied in parallel algorithms more generally.
In computer science, the prefix sum, cumulative sum, inclusive scan, or simply scan of a sequence of numbers x0, x1, x2, ... is a second sequence of numbers y0, y1, y2, ..., the sums of prefixes of the input sequence:
XMTC is a shared-memory parallel programming language. It is an extension of the C programming language which strives to enable easy PRAM-like programming based on the explicit multi-threading paradigm. It is developed as part of the XMT PRAM-On-Chip vision by a research team at the University of Maryland, College Park, led by Dr. Uzi Vishkin.
In computing, especially computational geometry, a real RAM is a mathematical model of a computer that can compute with exact real numbers instead of the binary fixed point or floating point numbers used by most actual computers. The real RAM was formulated by Michael Ian Shamos in his 1978 Ph.D. dissertation.
Uzi Vishkin is a computer scientist at the University of Maryland, College Park, where he is Professor of Electrical and Computer Engineering at the University of Maryland Institute for Advanced Computer Studies (UMIACS). Uzi Vishkin is known for his work in the field of parallel computing. In 1996, he was inducted as a Fellow of the Association for Computing Machinery, with the following citation: "One of the pioneers of parallel algorithms research, Dr. Vishkin's seminal contributions played a leading role in forming and shaping what thinking in parallel has come to mean in the fundamental theory of Computer Science."
In computer science, the all nearest smaller values problem is the following task: for each position in a sequence of numbers, search among the previous positions for the last position that contains a smaller value. This problem can be solved efficiently both by parallel and non-parallel algorithms: Berkman, Schieber & Vishkin (1993), who first identified the procedure as a useful subroutine for other parallel programs, developed efficient algorithms to solve it in the Parallel Random Access Machine model; it may also be solved in linear time on a non-parallel computer using a stack-based algorithm. Later researchers have studied algorithms to solve it in other models of parallel computation.
Explicit Multi-Threading (XMT) is a computer science paradigm for building and programming parallel computers designed around the parallel random-access machine (PRAM) parallel computational model. A more direct explanation of XMT starts with the rudimentary abstraction that made serial computing simple: that any single instruction available for execution in a serial program executes immediately. A consequence of this abstraction is a step-by-step (inductive) explication of the instruction available next for execution. The rudimentary parallel abstraction behind XMT, dubbed Immediate Concurrent Execution (ICE) in Vishkin (2011), is that indefinitely many instructions available for concurrent execution execute immediately. A consequence of ICE is a step-by-step (inductive) explication of the instructions available next for concurrent execution. Moving beyond the serial von Neumann computer, the aspiration of XMT is that computer science will again be able to augment mathematical induction with a simple one-line computing abstraction.
SuperPascal is an imperative, concurrent computing programming language developed by Per Brinch Hansen. It was designed as a publication language: a thinking tool to enable the clear and concise expression of concepts in parallel programming. This is in contrast with implementation languages which are often complicated with machine details and historical conventions. It was created to address the need at the time for a parallel publication language. Arguably, few languages today are expressive and concise enough to be used as thinking tools.
In computer science, the analysis of parallel algorithms is the process of finding the computational complexity of algorithms executed in parallel – the amount of time, storage, or other resources needed to execute them. In many respects, analysis of parallel algorithms is similar to the analysis of sequential algorithms, but is generally more involved because one must reason about the behavior of multiple cooperating threads of execution. One of the primary goals of parallel analysis is to understand how a parallel algorithm's use of resources changes as the number of processors is changed.
In computer science, the reduction operator is a type of operator that is commonly used in parallel programming to reduce the elements of an array into a single result. Reduction operators are associative and often commutative. The reduction of sets of elements is an integral part of programming models such as Map Reduce, where a reduction operator is applied (mapped) to all elements before they are reduced. Other parallel algorithms use reduction operators as primary operations to solve more complex problems. Many reduction operators can be used for broadcasting to distribute data to all processors.
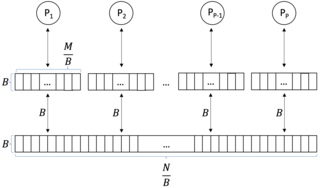
In computer science, a parallel external memory (PEM) model is a cache-aware, external-memory abstract machine. It is the parallel-computing analogy to the single-processor external memory (EM) model. In a similar way, it is the cache-aware analogy to the parallel random-access machine (PRAM). The PEM model consists of a number of processors, together with their respective private caches and a shared main memory.