In computer architecture, a bus is a communication system that transfers data between components inside a computer, or between computers. This expression covers all related hardware components and software, including communication protocols.
A distributed system is a system whose components are located on different networked computers, which communicate and coordinate their actions by passing messages to one another. Distributed computing is a field of computer science that studies distributed systems.

Network topology is the arrangement of the elements of a communication network. Network topology can be used to define or describe the arrangement of various types of telecommunication networks, including command and control radio networks, industrial fieldbusses and computer networks.

Symmetric multiprocessing or shared-memory multiprocessing (SMP) involves a multiprocessor computer hardware and software architecture where two or more identical processors are connected to a single, shared main memory, have full access to all input and output devices, and are controlled by a single operating system instance that treats all processors equally, reserving none for special purposes. Most multiprocessor systems today use an SMP architecture. In the case of multi-core processors, the SMP architecture applies to the cores, treating them as separate processors.
Multiprocessing is the use of two or more central processing units (CPUs) within a single computer system. The term also refers to the ability of a system to support more than one processor or the ability to allocate tasks between them. There are many variations on this basic theme, and the definition of multiprocessing can vary with context, mostly as a function of how CPUs are defined.

A Connection Machine (CM) is a member of a series of massively parallel supercomputers that grew out of doctoral research on alternatives to the traditional von Neumann architecture of computers by Danny Hillis at Massachusetts Institute of Technology (MIT) in the early 1980s. Starting with CM-1, the machines were intended originally for applications in artificial intelligence (AI) and symbolic processing, but later versions found greater success in the field of computational science.

Parallel computing is a type of computation in which many calculations or processes are carried out simultaneously. Large problems can often be divided into smaller ones, which can then be solved at the same time. There are several different forms of parallel computing: bit-level, instruction-level, data, and task parallelism. Parallelism has long been employed in high-performance computing, but has gained broader interest due to the physical constraints preventing frequency scaling. As power consumption by computers has become a concern in recent years, parallel computing has become the dominant paradigm in computer architecture, mainly in the form of multi-core processors.
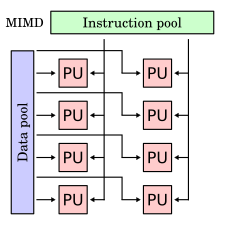
Flynn's taxonomy is a classification of computer architectures, proposed by Michael J. Flynn in 1966 and extended in 1972. The classification system has stuck, and it has been used as a tool in the design of modern processors and their functionalities. Since the rise of multiprocessing central processing units (CPUs), a multiprogramming context has evolved as an extension of the classification system. Vector processing, covered by Duncan's taxonomy, is missing from Flynn's work because the Cray-1 was released in 1977: Flynn's second paper was published in 1972.
In parallel computer architectures, a systolic array is a homogeneous network of tightly coupled data processing units (DPUs) called cells or nodes. Each node or DPU independently computes a partial result as a function of the data received from its upstream neighbours, stores the result within itself and passes it downstream. Systolic arrays were first used in Colossus, which was an early computer used to break German Lorenz ciphers during World War II. Due to the classified nature of Colossus, they were independently invented or rediscovered by H. T. Kung and Charles Leiserson who described arrays for many dense linear algebra computations for banded matrices. Early applications include computing greatest common divisors of integers and polynomials. They are sometimes classified as multiple-instruction single-data (MISD) architectures under Flynn's taxonomy, but this classification is questionable because a strong argument can be made to distinguish systolic arrays from any of Flynn's four categories: SISD, SIMD, MISD, MIMD, as discussed later in this article.
In computer science, distributed shared memory (DSM) is a form of memory architecture where physically separated memories can be addressed as a single shared address space. The term "shared" does not mean that there is a single centralized memory, but that the address space is shared—i.e., the same physical address on two processors refers to the same location in memory. Distributed global address space (DGAS), is a similar term for a wide class of software and hardware implementations, in which each node of a cluster has access to shared memory in addition to each node's private memory.

In computing, multiple instruction, single data (MISD) is a type of parallel computing architecture where many functional units perform different operations on the same data. Pipeline architectures belong to this type, though a purist might say that the data is different after processing by each stage in the pipeline. Fault tolerance executing the same instructions redundantly in order to detect and mask errors, in a manner known as task replication, may be considered to belong to this type. Applications for this architecture are much less common than MIMD and SIMD, as the latter two are often more appropriate for common data parallel techniques. Specifically, they allow better scaling and use of computational resources. However, one prominent example of MISD in computing are the Space Shuttle flight control computers.
In computing, single program, multiple data (SPMD) is a technique employed to achieve parallelism; it is a subcategory of MIMD. Tasks are split up and run simultaneously on multiple processors with different input in order to obtain results faster. SPMD is the most common style of parallel programming. It is also a prerequisite for research concepts such as active messages and distributed shared memory.
In computing, a parallel programming model is an abstraction of parallel computer architecture, with which it is convenient to express algorithms and their composition in programs. The value of a programming model can be judged on its generality: how well a range of different problems can be expressed for a variety of different architectures, and its performance: how efficiently the compiled programs can execute. The implementation of a parallel programming model can take the form of a library invoked from a sequential language, as an extension to an existing language, or as an entirely new language.
Multistage interconnection networks (MINs) are a class of high-speed computer networks usually composed of processing elements (PEs) on one end of the network and memory elements (MEs) on the other end, connected by switching elements (SEs). The switching elements themselves are usually connected to each other in stages, hence the name.
Duncan's taxonomy is a classification of computer architectures, proposed by Ralph Duncan in 1990. Duncan suggested modifications to Flynn's taxonomy to include pipelined vector processes.
SUPRENUM was a German research project to develop a parallel computer from 1985 through 1990. It was a major effort which was aimed at developing a national expertise in massively parallel processing both at hardware and at software level.
ISRA VISION PARSYTEC AG is a company of ISRA VISION AG and was founded in 1985 as Parsytec in Aachen, Germany.

In computer networking, hypercube networks are a type of network topology used to connect multiple processors with memory modules and accurately route data. Hypercube networks consist of 2m nodes, which form the vertices of squares to create an internetwork connection. A hypercube is basically a multidimensional mesh network with two nodes in each dimension. Due to similarity, such topologies are usually grouped into a k-ary d-dimensional mesh topology family, where d represents the number of dimensions and k represents the number of nodes in each dimension.

A butterfly network is a technique to link multiple computers into a high-speed network. This form of multistage interconnection network topology can be used to connect different nodes in a multiprocessor system. The interconnect network for a shared memory multiprocessor system must have low latency and high bandwidth unlike other network systems, like local area networks (LANs) or internet for three reasons:
A multiprocessor system is defined as "a system with more than one processor", and, more precisely, "a number of central processing units linked together to enable parallel processing to take place".