This article needs additional citations for verification .(August 2012) |
In the design of pipelined computer processors, a pipeline stall is a delay in execution of an instruction in order to resolve a hazard. [1]
This article needs additional citations for verification .(August 2012) |
In the design of pipelined computer processors, a pipeline stall is a delay in execution of an instruction in order to resolve a hazard. [1]
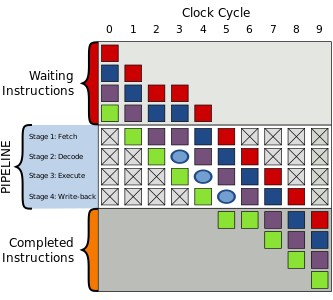
In a standard five-stage pipeline, during the decoding stage, the control unit will determine whether the decoded instruction reads from a register to which the currently executed instruction writes. If this condition holds, the control unit will stall the instruction by one clock cycle. It also stalls the instruction in the fetch stage, to prevent the instruction in that stage from being overwritten by the next instruction in the program. [2]
In a Von Neumann architecture which uses the program counter (PC) register to determine the current instruction being fetched in the pipeline, to prevent new instructions from being fetched when an instruction in the decoding stage has been stalled, the value in the PC register and the instruction in the fetch stage are preserved to prevent changes. The values are preserved until the instruction causing the conflict has passed through the execution stage. [3] Such an event is often called a bubble, by analogy with an air bubble in a fluid pipe.
In some architectures, the execution stage of the pipeline must always be performing an action at every cycle. In that case, the bubble is implemented by feeding NOP ("no operation") instructions to the execution stage, until the bubble is flushed past it.
The following is two executions of the same four instructions through a 4-stage pipeline but, for whatever reason, a delay in fetching of the purple instruction in cycle #2 leads to a bubble being created delaying all instructions after it as well.
 |  |
| Normal execution | Execution with a bubble |
The below example shows a bubble being inserted into a classic RISC pipeline, with five stages (IF = Instruction Fetch, ID = Instruction Decode, EX = Execute, MEM = Memory access, WB = Register write back). In this example, data available after the MEM stage (4th stage) of the first instruction is required as input by the EX stage (3rd stage) of the second instruction. Without a bubble, the EX stage (3rd stage) only has access to the output of the previous EX stage. Thus adding a bubble resolves the time dependence without needing to propagate data backwards in time (which is impossible).
| Bypassing backwards in time | Problem resolved using a bubble |
 |  |

A central processing unit (CPU), also called a central processor, main processor or just processor, is the electronic circuitry that executes instructions comprising a computer program. The CPU performs basic arithmetic, logic, controlling, and input/output (I/O) operations specified by the instructions in the program. This contrasts with external components such as main memory and I/O circuitry, and specialized processors such as graphics processing units (GPUs).
The control unit (CU) is a component of a computer's central processing unit (CPU) that directs the operation of the processor. A CU typically uses a binary decoder to convert coded instructions into timing and control signals that direct the operation of the other units.
In computing, the instruction register (IR) or current instruction register (CIR) is the part of a CPU's control unit that holds the instruction currently being executed or decoded. In simple processors, each instruction to be executed is loaded into the instruction register, which holds it while it is decoded, prepared and ultimately executed, which can take several steps.

The program counter (PC), commonly called the instruction pointer (IP) in Intel x86 and Itanium microprocessors, and sometimes called the instruction address register (IAR), the instruction counter, or just part of the instruction sequencer, is a processor register that indicates where a computer is in its program sequence.
In computer engineering, instruction pipelining is a technique for implementing instruction-level parallelism within a single processor. Pipelining attempts to keep every part of the processor busy with some instruction by dividing incoming instructions into a series of sequential steps performed by different processor units with different parts of instructions processed in parallel.
Tomasulo's algorithm is a computer architecture hardware algorithm for dynamic scheduling of instructions that allows out-of-order execution and enables more efficient use of multiple execution units. It was developed by Robert Tomasulo at IBM in 1967 and was first implemented in the IBM System/360 Model 91’s floating point unit.
In the domain of central processing unit (CPU) design, hazards are problems with the instruction pipeline in CPU microarchitectures when the next instruction cannot execute in the following clock cycle, and can potentially lead to incorrect computation results. Three common types of hazards are data hazards, structural hazards, and control hazards.
In the history of computer hardware, some early reduced instruction set computer central processing units used a very similar architectural solution, now called a classic RISC pipeline. Those CPUs were: MIPS, SPARC, Motorola 88000, and later the notional CPU DLX invented for education.
Execution in computer and software engineering is the process by which a computer or virtual machine reads and acts on the instructions of a computer program. Each instruction of a program is a description of a particular action which must be carried out, in order for a specific problem to be solved. Execution involves repeatedly following a 'fetch–decode–execute' cycle for each instruction done by control unit. As the executing machine follows the instructions, specific effects are produced in accordance with the semantics of those instructions.
The DLX is a RISC processor architecture designed by John L. Hennessy and David A. Patterson, the principal designers of the Stanford MIPS and the Berkeley RISC designs (respectively), the two benchmark examples of RISC design.

The instruction cycle is the cycle that the central processing unit (CPU) follows from boot-up until the computer has shut down in order to process instructions. It is composed of three main stages: the fetch stage, the decode stage, and the execute stage.
In computer engineering, out-of-order execution is a paradigm used in most high-performance central processing units to make use of instruction cycles that would otherwise be wasted. In this paradigm, a processor executes instructions in an order governed by the availability of input data and execution units, rather than by their original order in a program. In doing so, the processor can avoid being idle while waiting for the preceding instruction to complete and can, in the meantime, process the next instructions that are able to run immediately and independently.
In computing, a pipeline, also known as a data pipeline, is a set of data processing elements connected in series, where the output of one element is the input of the next one. The elements of a pipeline are often executed in parallel or in time-sliced fashion. Some amount of buffer storage is often inserted between elements.

In computer engineering, microarchitecture, also called computer organization and sometimes abbreviated as µarch or uarch, is the way a given instruction set architecture (ISA) is implemented in a particular processor. A given ISA may be implemented with different microarchitectures; implementations may vary due to different goals of a given design or due to shifts in technology.
In computer architecture, cycles per instruction is one aspect of a processor's performance: the average number of clock cycles per instruction for a program or program fragment. It is the multiplicative inverse of instructions per cycle.

The POWER3 is a microprocessor, designed and exclusively manufactured by IBM, that implemented the 64-bit version of the PowerPC instruction set architecture (ISA), including all of the optional instructions of the ISA such as instructions present in the POWER2 version of the POWER ISA but not in the PowerPC ISA. It was introduced on 5 October 1998, debuting in the RS/6000 43P Model 260, a high-end graphics workstation. The POWER3 was originally supposed to be called the PowerPC 630 but was renamed, probably to differentiate the server-oriented POWER processors it replaced from the more consumer-oriented 32-bit PowerPCs. The POWER3 was the successor of the P2SC derivative of the POWER2 and completed IBM's long-delayed transition from POWER to PowerPC, which was originally scheduled to conclude in 1995. The POWER3 was used in IBM RS/6000 servers and workstations at 200 MHz. It competed with the Digital Equipment Corporation (DEC) Alpha 21264 and the Hewlett-Packard (HP) PA-8500.
MIPS, an acronym for Microprocessor without Interlocked Pipeline Stages, was a research project conducted by John L. Hennessy at Stanford University between 1981 and 1984. MIPS investigated a type of instruction set architecture (ISA) now called reduced instruction set computer (RISC), its implementation as a microprocessor with very large scale integration (VLSI) semiconductor technology, and the effective exploitation of RISC architectures with optimizing compilers. MIPS, together with the IBM 801 and Berkeley RISC, were the three research projects that pioneered and popularized RISC technology in the mid-1980s. In recognition of the impact MIPS made on computing, Hennessey was awarded the IEEE John von Neumann Medal in 2000 by the Institute of Electrical and Electronics Engineers (IEEE), the Eckert–Mauchly Award in 2001 by the Association for Computing Machinery, the Seymour Cray Computer Engineering Award in 2001 by the IEEE Computer Society, and, again with David Patterson, the Turing Award in 2017 by the ACM.
Scoreboarding is a centralized method, first used in the CDC 6600 computer, for dynamically scheduling instructions so that they can execute out of order when there are no conflicts and the hardware is available.
The instruction unit, also called, e.g., instruction fetch unit (IFU), instruction issue unit (IIU), instruction sequencing unit (ISU), in a central processing unit (CPU) is responsible for organizing program instructions to be fetched from memory, and executed, in an appropriate order, and for forwarding them to an execution unit. The I-unit may also do, e.g., address resolution, pre-fetching, prior to forwarding an instruction. It is a part of the control unit, which in turn is part of the CPU.
Latency oriented processor architecture is the microarchitecture of a microprocessor designed to serve a serial computing thread with a low latency. This is typical of most central processing units (CPU) being developed since the 1970s. These architectures, in general, aim to execute as many instructions as possible belonging to a single serial thread, in a given window of time; however, the time to execute a single instruction completely from fetch to retire stages may vary from a few cycles to even a few hundred cycles in some cases. Latency oriented processor architectures are the opposite of throughput-oriented processors which concern themselves more with the total throughput of the system, rather than the service latencies for all individual threads that they work on.