
A central processing unit (CPU) is the most important processor in a given computer. Its electronic circuitry executes instructions of a computer program, such as arithmetic, logic, controlling, and input/output (I/O) operations. This role contrasts with that of external components, such as main memory and I/O circuitry, and specialized coprocessors such as graphics processing units (GPUs).
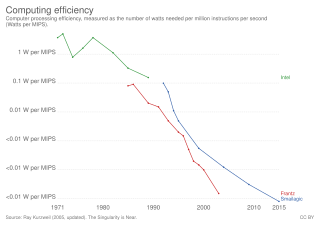
Instructions per second (IPS) is a measure of a computer's processor speed. For complex instruction set computers (CISCs), different instructions take different amounts of time, so the value measured depends on the instruction mix; even for comparing processors in the same family the IPS measurement can be problematic. Many reported IPS values have represented "peak" execution rates on artificial instruction sequences with few branches and no cache contention, whereas realistic workloads typically lead to significantly lower IPS values. Memory hierarchy also greatly affects processor performance, an issue barely considered in IPS calculations. Because of these problems, synthetic benchmarks such as Dhrystone are now generally used to estimate computer performance in commonly used applications, and raw IPS has fallen into disuse.
In computer science, an instruction set architecture (ISA) is a part of the abstract model of a computer, which generally defines how software controls the CPU. A device that executes instructions described by that ISA, such as a central processing unit (CPU), is called an implementation.

A superscalar processor is a CPU that implements a form of parallelism called instruction-level parallelism within a single processor. In contrast to a scalar processor, which can execute at most one single instruction per clock cycle, a superscalar processor can execute more than one instruction during a clock cycle by simultaneously dispatching multiple instructions to different execution units on the processor. It therefore allows more throughput than would otherwise be possible at a given clock rate. Each execution unit is not a separate processor, but an execution resource within a single CPU such as an arithmetic logic unit.

Parallel computing is a type of computation in which many calculations or processes are carried out simultaneously. Large problems can often be divided into smaller ones, which can then be solved at the same time. There are several different forms of parallel computing: bit-level, instruction-level, data, and task parallelism. Parallelism has long been employed in high-performance computing, but has gained broader interest due to the physical constraints preventing frequency scaling. As power consumption by computers has become a concern in recent years, parallel computing has become the dominant paradigm in computer architecture, mainly in the form of multi-core processors.

In computing, the clock rate or clock speed typically refers to the frequency at which the clock generator of a processor can generate pulses, which are used to synchronize the operations of its components, and is used as an indicator of the processor's speed. It is measured in the SI unit of frequency hertz (Hz).
In the history of computer hardware, some early reduced instruction set computer central processing units used a very similar architectural solution, now called a classic RISC pipeline. Those CPUs were: MIPS, SPARC, Motorola 88000, and later the notional CPU DLX invented for education.
The DLX is a RISC processor architecture designed by John L. Hennessy and David A. Patterson, the principal designers of the Stanford MIPS and the Berkeley RISC designs (respectively), the two benchmark examples of RISC design.
A translation lookaside buffer (TLB) is a memory cache that stores the recent translations of virtual memory to physical memory. It is used to reduce the time taken to access a user memory location. It can be called an address-translation cache. It is a part of the chip's memory-management unit (MMU). A TLB may reside between the CPU and the CPU cache, between CPU cache and the main memory or between the different levels of the multi-level cache. The majority of desktop, laptop, and server processors include one or more TLBs in the memory-management hardware, and it is nearly always present in any processor that utilizes paged or segmented virtual memory.

In electronics, computer science and computer engineering, microarchitecture, also called computer organization and sometimes abbreviated as µarch or uarch, is the way a given instruction set architecture (ISA) is implemented in a particular processor. A given ISA may be implemented with different microarchitectures; implementations may vary due to different goals of a given design or due to shifts in technology.
In computer architecture, speedup is a number that measures the relative performance of two systems processing the same problem. More technically, it is the improvement in speed of execution of a task executed on two similar architectures with different resources. The notion of speedup was established by Amdahl's law, which was particularly focused on parallel processing. However, speedup can be used more generally to show the effect on performance after any resource enhancement.

In computing, a benchmark is the act of running a computer program, a set of programs, or other operations, in order to assess the relative performance of an object, normally by running a number of standard tests and trials against it.
The megahertz myth, or in more recent cases the gigahertz myth, refers to the misconception of only using clock rate to compare the performance of different microprocessors. While clock rates are a valid way of comparing the performance of different speeds of the same model and type of processor, other factors such as an amount of execution units, pipeline depth, cache hierarchy, branch prediction, and instruction sets can greatly affect the performance when considering different processors. For example, one processor may take two clock cycles to add two numbers and another clock cycle to multiply by a third number, whereas another processor may do the same calculation in two clock cycles. Comparisons between different types of processors are difficult because performance varies depending on the type of task. A benchmark is a more thorough way of measuring and comparing computer performance.
In computer architecture, cycles per instruction is one aspect of a processor's performance: the average number of clock cycles per instruction for a program or program fragment. It is the multiplicative inverse of instructions per cycle.
In computing, computer performance is the amount of useful work accomplished by a computer system. Outside of specific contexts, computer performance is estimated in terms of accuracy, efficiency and speed of executing computer program instructions. When it comes to high computer performance, one or more of the following factors might be involved:

The history of general-purpose CPUs is a continuation of the earlier history of computing hardware.
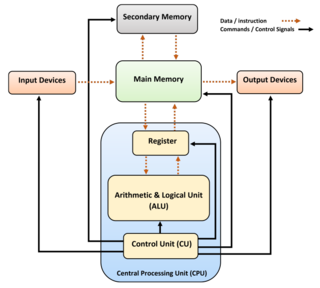
In computer science and computer engineering, computer architecture is a description of the structure of a computer system made from component parts. It can sometimes be a high-level description that ignores details of the implementation. At a more detailed level, the description may include the instruction set architecture design, microarchitecture design, logic design, and implementation.

MikroSim is an educational software computer program for hardware-non-specific explanation of the general functioning and behaviour of a virtual processor, running on the Microsoft Windows operating system. Devices like miniaturized calculators, microcontroller, microprocessors, and computer can be explained on custom-developed instruction code on a register transfer level controlled by sequences of micro instructions (microcode). Based on this it is possible to develop an instruction set to control a virtual application board at higher level of abstraction.
Latency oriented processor architecture is the microarchitecture of a microprocessor designed to serve a serial computing thread with a low latency. This is typical of most central processing units (CPU) being developed since the 1970s. These architectures, in general, aim to execute as many instructions as possible belonging to a single serial thread, in a given window of time; however, the time to execute a single instruction completely from fetch to retire stages may vary from a few cycles to even a few hundred cycles in some cases. Latency oriented processor architectures are the opposite of throughput-oriented processors which concern themselves more with the total throughput of the system, rather than the service latencies for all individual threads that they work on.

Cache hierarchy, or multi-level cache, is a memory architecture that uses a hierarchy of memory stores based on varying access speeds to cache data. Highly requested data is cached in high-speed access memory stores, allowing swifter access by central processing unit (CPU) cores.