Sensitivity analysis methods
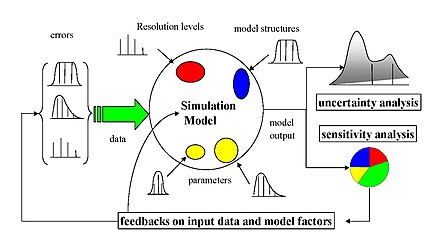

There are a large number of approaches to performing a sensitivity analysis, many of which have been developed to address one or more of the constraints discussed above. They are also distinguished by the type of sensitivity measure, be it based on (for example) variance decompositions, partial derivatives or elementary effects. In general, however, most procedures adhere to the following outline:
- Quantify the uncertainty in each input (e.g. ranges, probability distributions). Note that this can be difficult and many methods exist to elicit uncertainty distributions from subjective data. [15]
- Identify the model output to be analysed (the target of interest should ideally have a direct relation to the problem tackled by the model).
- Run the model a number of times using some design of experiments, [16] dictated by the method of choice and the input uncertainty.
- Using the resulting model outputs, calculate the sensitivity measures of interest.
In some cases this procedure will be repeated, for example in high-dimensional problems where the user has to screen out unimportant variables before performing a full sensitivity analysis.
The various types of "core methods" (discussed below) are distinguished by the various sensitivity measures which are calculated. These categories can somehow overlap. Alternative ways of obtaining these measures, under the constraints of the problem, can be given.
One-at-a-time (OAT)
One of the simplest and most common approaches is that of changing one-factor-at-a-time (OAT), to see what effect this produces on the output. [17] [18] [19] OAT customarily involves
- moving one input variable, keeping others at their baseline (nominal) values, then,
- returning the variable to its nominal value, then repeating for each of the other inputs in the same way.
Sensitivity may then be measured by monitoring changes in the output, e.g. by partial derivatives or linear regression. This appears a logical approach as any change observed in the output will unambiguously be due to the single variable changed. Furthermore, by changing one variable at a time, one can keep all other variables fixed to their central or baseline values. This increases the comparability of the results (all 'effects' are computed with reference to the same central point in space) and minimizes the chances of computer program crashes, more likely when several input factors are changed simultaneously. OAT is frequently preferred by modelers because of practical reasons. In case of model failure under OAT analysis the modeler immediately knows which is the input factor responsible for the failure.
Despite its simplicity however, this approach does not fully explore the input space, since it does not take into account the simultaneous variation of input variables. This means that the OAT approach cannot detect the presence of interactions between input variables and is unsuitable for nonlinear models. [20]
The proportion of input space which remains unexplored with an OAT approach grows superexponentially with the number of inputs. For example, a 3-variable parameter space which is explored one-at-a-time is equivalent to taking points along the x, y, and z axes of a cube centered at the origin. The convex hull bounding all these points is an octahedron which has a volume only 1/6th of the total parameter space. More generally, the convex hull of the axes of a hyperrectangle forms a hyperoctahedron which has a volume fraction of . With 5 inputs, the explored space already drops to less than 1% of the total parameter space. And even this is an overestimate, since the off-axis volume is not actually being sampled at all. Compare this to random sampling of the space, where the convex hull approaches the entire volume as more points are added. [21] While the sparsity of OAT is theoretically not a concern for linear models, true linearity is rare in nature.

Derivative-based local methods
Local derivative-based methods involve taking the partial derivative of the output Y with respect to an input factor Xi :

where the subscript x0 indicates that the derivative is taken at some fixed point in the space of the input (hence the 'local' in the name of the class). Adjoint modelling [22] [23] and Automated Differentiation [24] are methods which allow to compute all partial derivatives at a cost at most 4-6 times of that for evaluating the original function. Similar to OAT, local methods do not attempt to fully explore the input space, since they examine small perturbations, typically one variable at a time. It is possible to select similar samples from derivative-based sensitivity through Neural Networks and perform uncertainty quantification.
One advantage of the local methods is that it is possible to make a matrix to represent all the sensitivities in a system, thus providing an overview that cannot be achieved with global methods if there is a large number of input and output variables.
Regression analysis
Regression analysis, in the context of sensitivity analysis, involves fitting a linear regression to the model response and using standardized regression coefficients as direct measures of sensitivity. The regression is required to be linear with respect to the data (i.e. a hyperplane, hence with no quadratic terms, etc., as regressors) because otherwise it is difficult to interpret the standardised coefficients. This method is therefore most suitable when the model response is in fact linear; linearity can be confirmed, for instance, if the coefficient of determination is large. The advantages of regression analysis are that it is simple and has a low computational cost.
Variance-based methods
Variance-based methods [26] are a class of probabilistic approaches which quantify the input and output uncertainties as probability distributions, and decompose the output variance into parts attributable to input variables and combinations of variables. The sensitivity of the output to an input variable is therefore measured by the amount of variance in the output caused by that input. These can be expressed as conditional expectations, i.e., considering a model Y = f(X) for X = {X1, X2, ... Xk}, a measure of sensitivity of the ith variable Xi is given as,

where "Var" and "E" denote the variance and expected value operators respectively, and X~i denotes the set of all input variables except Xi. This expression essentially measures the contribution Xi alone to the uncertainty (variance) in Y (averaged over variations in other variables), and is known as the first-order sensitivity index or main effect index. Importantly, it does not measure the uncertainty caused by interactions with other variables. A further measure, known as the total effect index, gives the total variance in Y caused by Xiand its interactions with any of the other input variables. Both quantities are typically standardised by dividing by Var(Y).
Variance-based methods allow full exploration of the input space, accounting for interactions, and nonlinear responses. For these reasons they are widely used when it is feasible to calculate them. Typically this calculation involves the use of Monte Carlo methods, but since this can involve many thousands of model runs, other methods (such as emulators) can be used to reduce computational expense when necessary.
Variogram analysis of response surfaces (VARS)
One of the major shortcomings of the previous sensitivity analysis methods is that none of them considers the spatially ordered structure of the response surface/output of the model Y=f(X) in the parameter space. By utilizing the concepts of directional variograms and covariograms, variogram analysis of response surfaces (VARS) addresses this weakness through recognizing a spatially continuous correlation structure to the values of Y, and hence also to the values of . [27] [28]

Basically, the higher the variability the more heterogeneous is the response surface along a particular direction/parameter, at a specific perturbation scale. Accordingly, in the VARS framework, the values of directional variograms for a given perturbation scale can be considered as a comprehensive illustration of sensitivity information, through linking variogram analysis to both direction and perturbation scale concepts. As a result, the VARS framework accounts for the fact that sensitivity is a scale-dependent concept, and thus overcomes the scale issue of traditional sensitivity analysis methods. [29] More importantly, VARS is able to provide relatively stable and statistically robust estimates of parameter sensitivity with much lower computational cost than other strategies (about two orders of magnitude more efficient). [30] Noteworthy, it has been shown that there is a theoretical link between the VARS framework and the variance-based and derivative-based approaches.