Definition
Given a portfolio of algorithms , a set of instances and a cost metric , the algorithm selection problem consists of finding a mapping from instances to algorithms such that the cost across all instances is optimized. [1] [2]
Algorithm selection (sometimes also called per-instance algorithm selection or offline algorithm selection) is a meta-algorithmic technique to choose an algorithm from a portfolio on an instance-by-instance basis. It is motivated by the observation that on many practical problems, different algorithms have different performance characteristics. That is, while one algorithm performs well in some scenarios, it performs poorly in others and vice versa for another algorithm. If we can identify when to use which algorithm, we can optimize for each scenario and improve overall performance. This is what algorithm selection aims to do. The only prerequisite for applying algorithm selection techniques is that there exists (or that there can be constructed) a set of complementary algorithms.
Given a portfolio of algorithms , a set of instances and a cost metric , the algorithm selection problem consists of finding a mapping from instances to algorithms such that the cost across all instances is optimized. [1] [2]
A well-known application of algorithm selection is the Boolean satisfiability problem. Here, the portfolio of algorithms is a set of (complementary) SAT solvers, the instances are Boolean formulas, the cost metric is for example average runtime or number of unsolved instances. So, the goal is to select a well-performing SAT solver for each individual instance. In the same way, algorithm selection can be applied to many other -hard problems (such as mixed integer programming, CSP, AI planning, TSP, MAXSAT, QBF and answer set programming). Competition-winning systems in SAT are SATzilla, [3] 3S [4] and CSHC [5]
In machine learning, algorithm selection is better known as meta-learning. The portfolio of algorithms consists of machine learning algorithms (e.g., Random Forest, SVM, DNN), the instances are data sets and the cost metric is for example the error rate. So, the goal is to predict which machine learning algorithm will have a small error on each data set.
The algorithm selection problem is mainly solved with machine learning techniques. By representing the problem instances by numerical features , algorithm selection can be seen as a multi-class classification problem by learning a mapping for a given instance .
Instance features are numerical representations of instances. For example, we can count the number of variables, clauses, average clause length for Boolean formulas, [6] or number of samples, features, class balance for ML data sets to get an impression about their characteristics.
We distinguish between two kinds of features:
Depending on the used performance metric , feature computation can be associated with costs. For example, if we use running time as performance metric, we include the time to compute our instance features into the performance of an algorithm selection system. SAT solving is a concrete example, where such feature costs cannot be neglected, since instance features for CNF formulas can be either very cheap (e.g., to get the number of variables can be done in constant time for CNFs in the DIMACs format) or very expensive (e.g., graph features which can cost tens or hundreds of seconds).
It is important to take the overhead of feature computation into account in practice in such scenarios; otherwise a misleading impression of the performance of the algorithm selection approach is created. For example, if the decision which algorithm to choose can be made with perfect accuracy, but the features are the running time of the portfolio algorithms, there is no benefit to the portfolio approach. This would not be obvious if feature costs were omitted.
One of the first successful algorithm selection approaches predicted the performance of each algorithm and selected the algorithm with the best predicted performance for an instance . [3]
A common assumption is that the given set of instances can be clustered into homogeneous subsets and for each of these subsets, there is one well-performing algorithm for all instances in there. So, the training consists of identifying the homogeneous clusters via an unsupervised clustering approach and associating an algorithm with each cluster. A new instance is assigned to a cluster and the associated algorithm selected. [7]
A more modern approach is cost-sensitive hierarchical clustering [5] using supervised learning to identify the homogeneous instance subsets.
A common approach for multi-class classification is to learn pairwise models between every pair of classes (here algorithms) and choose the class that was predicted most often by the pairwise models. We can weight the instances of the pairwise prediction problem by the performance difference between the two algorithms. This is motivated by the fact that we care most about getting predictions with large differences correct, but the penalty for an incorrect prediction is small if there is almost no performance difference. Therefore, each instance for training a classification model vs is associated with a cost . [8]


The algorithm selection problem can be effectively applied under the following assumptions:
Algorithm selection is not limited to single domains but can be applied to any kind of algorithm if the above requirements are satisfied. Application domains include:
For an extensive list of literature about algorithm selection, we refer to a literature overview.
Online algorithm selection refers to switching between different algorithms during the solving process. This is useful as a hyper-heuristic. In contrast, offline algorithm selection selects an algorithm for a given instance only once and before the solving process.
An extension of algorithm selection is the per-instance algorithm scheduling problem, in which we do not select only one solver, but we select a time budget for each algorithm on a per-instance base. This approach improves the performance of selection systems in particular if the instance features are not very informative and a wrong selection of a single solver is likely. [11]
Given the increasing importance of parallel computation, an extension of algorithm selection for parallel computation is parallel portfolio selection, in which we select a subset of the algorithms to simultaneously run in a parallel portfolio. [12]
In machine learning, support vector machines are supervised max-margin models with associated learning algorithms that analyze data for classification and regression analysis. Developed at AT&T Bell Laboratories by Vladimir Vapnik with colleagues SVMs are one of the most studied models, being based on statistical learning frameworks or VC theory proposed by Vapnik and Chervonenkis (1974).
Pattern recognition is the task of assigning a class to an observation based on patterns extracted from data. While similar, pattern recognition (PR) is not to be confused with pattern machines (PM) which may possess (PR) capabilities but their primary function is to distinguish and create emergent pattern. PR has applications in statistical data analysis, signal processing, image analysis, information retrieval, bioinformatics, data compression, computer graphics and machine learning. Pattern recognition has its origins in statistics and engineering; some modern approaches to pattern recognition include the use of machine learning, due to the increased availability of big data and a new abundance of processing power.
Multi-task learning (MTL) is a subfield of machine learning in which multiple learning tasks are solved at the same time, while exploiting commonalities and differences across tasks. This can result in improved learning efficiency and prediction accuracy for the task-specific models, when compared to training the models separately. Early versions of MTL were called "hints".
Feature selection is the process of selecting a subset of relevant features for use in model construction. Stylometry and DNA microarray analysis are two cases where feature selection is used. It should be distinguished from feature extraction.
Empirical risk minimization is a principle in statistical learning theory which defines a family of learning algorithms based on evaluating performance over a known and fixed dataset. The core idea is based on an application of the law of large numbers; more specifically, we cannot know exactly how well a predictive algorithm will work in practice because we do not know the true distribution of the data, but we can instead estimate and optimize the performance of the algorithm on a known set of training data. The performance over the known set of training data is referred to as the "empirical risk".
In statistics, the k-nearest neighbors algorithm (k-NN) is a non-parametric supervised learning method first developed by Evelyn Fix and Joseph Hodges in 1951, and later expanded by Thomas Cover. It is used for classification and regression. In both cases, the input consists of the k closest training examples in a data set. The output depends on whether k-NN is used for classification or regression:
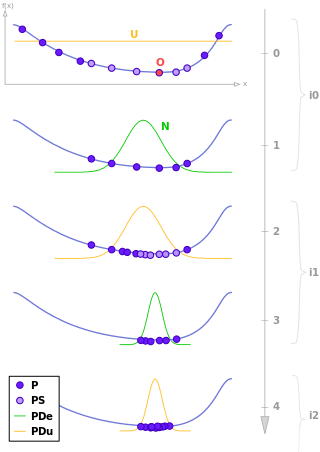
Estimation of distribution algorithms (EDAs), sometimes called probabilistic model-building genetic algorithms (PMBGAs), are stochastic optimization methods that guide the search for the optimum by building and sampling explicit probabilistic models of promising candidate solutions. Optimization is viewed as a series of incremental updates of a probabilistic model, starting with the model encoding an uninformative prior over admissible solutions and ending with the model that generates only the global optima.
In computational complexity theory, the maximum satisfiability problem (MAX-SAT) is the problem of determining the maximum number of clauses, of a given Boolean formula in conjunctive normal form, that can be made true by an assignment of truth values to the variables of the formula. It is a generalization of the Boolean satisfiability problem, which asks whether there exists a truth assignment that makes all clauses true.
In machine learning, kernel machines are a class of algorithms for pattern analysis, whose best known member is the support-vector machine (SVM). These methods involve using linear classifiers to solve nonlinear problems. The general task of pattern analysis is to find and study general types of relations in datasets. For many algorithms that solve these tasks, the data in raw representation have to be explicitly transformed into feature vector representations via a user-specified feature map: in contrast, kernel methods require only a user-specified kernel, i.e., a similarity function over all pairs of data points computed using inner products. The feature map in kernel machines is infinite dimensional but only requires a finite dimensional matrix from user-input according to the Representer theorem. Kernel machines are slow to compute for datasets larger than a couple of thousand examples without parallel processing.
In mathematical optimization, the ellipsoid method is an iterative method for minimizing convex functions over convex sets. The ellipsoid method generates a sequence of ellipsoids whose volume uniformly decreases at every step, thus enclosing a minimizer of a convex function.
The study of facility location problems (FLP), also known as location analysis, is a branch of operations research and computational geometry concerned with the optimal placement of facilities to minimize transportation costs while considering factors like avoiding placing hazardous materials near housing, and competitors' facilities. The techniques also apply to cluster analysis.
Job-shop scheduling, the job-shop problem (JSP) or job-shop scheduling problem (JSSP) is an optimization problem in computer science and operations research. It is a variant of optimal job scheduling. In a general job scheduling problem, we are given n jobs J1, J2, ..., Jn of varying processing times, which need to be scheduled on m machines with varying processing power, while trying to minimize the makespan – the total length of the schedule. In the specific variant known as job-shop scheduling, each job consists of a set of operationsO1, O2, ..., On which need to be processed in a specific order. Each operation has a specific machine that it needs to be processed on and only one operation in a job can be processed at a given time. A common relaxation is the flexible job shop, where each operation can be processed on any machine of a given set.
Consensus clustering is a method of aggregating results from multiple clustering algorithms. Also called cluster ensembles or aggregation of clustering, it refers to the situation in which a number of different (input) clusterings have been obtained for a particular dataset and it is desired to find a single (consensus) clustering which is a better fit in some sense than the existing clusterings. Consensus clustering is thus the problem of reconciling clustering information about the same data set coming from different sources or from different runs of the same algorithm. When cast as an optimization problem, consensus clustering is known as median partition, and has been shown to be NP-complete, even when the number of input clusterings is three. Consensus clustering for unsupervised learning is analogous to ensemble learning in supervised learning.
Large margin nearest neighbor (LMNN) classification is a statistical machine learning algorithm for metric learning. It learns a pseudometric designed for k-nearest neighbor classification. The algorithm is based on semidefinite programming, a sub-class of convex optimization.
In data mining and machine learning, kq-flats algorithm is an iterative method which aims to partition m observations into k clusters where each cluster is close to a q-flat, where q is a given integer.
In machine learning, multiple-instance learning (MIL) is a type of supervised learning. Instead of receiving a set of instances which are individually labeled, the learner receives a set of labeled bags, each containing many instances. In the simple case of multiple-instance binary classification, a bag may be labeled negative if all the instances in it are negative. On the other hand, a bag is labeled positive if there is at least one instance in it which is positive. From a collection of labeled bags, the learner tries to either (i) induce a concept that will label individual instances correctly or (ii) learn how to label bags without inducing the concept.
Automated machine learning (AutoML) is the process of automating the tasks of applying machine learning to real-world problems.
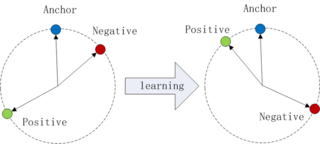
Triplet loss is a loss function for machine learning algorithms where a reference input is compared to a matching input and a non-matching input. The distance from the anchor to the positive is minimized, and the distance from the anchor to the negative input is maximized. An early formulation equivalent to triplet loss was introduced for metric learning from relative comparisons by M. Schultze and T. Joachims in 2003.
Weak supervision is a paradigm in machine learning, the relevance and notability of which increased with the advent of large language models due to large amount of data required to train them. It is characterized by using a combination of a small amount of human-labeled data, followed by a large amount of unlabeled data. In other words, the desired output values are provided only for a subset of the training data. The remaining data is unlabeled or imprecisely labeled. Intuitively, it can be seen as an exam and labeled data as sample problems that the teacher solves for the class as an aid in solving another set of problems. In the transductive setting, these unsolved problems act as exam questions. In the inductive setting, they become practice problems of the sort that will make up the exam. Technically, it could be viewed as performing clustering and then labeling the clusters with the labeled data, pushing the decision boundary away from high-density regions, or learning an underlying one-dimensional manifold where the data reside.
Marius Lindauer is a German computer scientist and professor of machine learning at the institute of artificial intelligence of the Leibniz University Hannover. He is known for his research on Automated Machine Learning and other meta-algorithmic approaches.
















