Related Research Articles
Approximants are speech sounds that involve the articulators approaching each other but not narrowly enough nor with enough articulatory precision to create turbulent airflow. Therefore, approximants fall between fricatives, which do produce a turbulent airstream, and vowels, which produce no turbulence. This class is composed of sounds like and semivowels like and, as well as lateral approximants like.
In phonology, minimal pairs are pairs of words or phrases in a particular language, spoken or signed, that differ in only one phonological element, such as a phoneme, toneme or chroneme, and have distinct meanings. They are used to demonstrate that two phones represent two separate phonemes in the language.

Phonetics is a branch of linguistics that studies how humans produce and perceive sounds, or in the case of sign languages, the equivalent aspects of sign. Linguists who specialize in studying the physical properties of speech are phoneticians. The field of phonetics is traditionally divided into three sub-disciplines based on the research questions involved such as how humans plan and execute movements to produce speech, how various movements affect the properties of the resulting sound, or how humans convert sound waves to linguistic information. Traditionally, the minimal linguistic unit of phonetics is the phone—a speech sound in a language which differs from the phonological unit of phoneme; the phoneme is an abstract categorization of phones, and it is also defined as the smallest unit that discerns meaning between sounds in any given language.
Phonology is the branch of linguistics that studies how languages systematically organize their phones or, for sign languages, their constituent parts of signs. The term can also refer specifically to the sound or sign system of a particular language variety. At one time, the study of phonology related only to the study of the systems of phonemes in spoken languages, but may now relate to any linguistic analysis either:
Phonotactics is a branch of phonology that deals with restrictions in a language on the permissible combinations of phonemes. Phonotactics defines permissible syllable structure, consonant clusters and vowel sequences by means of phonotactic constraints.
Auditory phonetics is the branch of phonetics concerned with the hearing of speech sounds and with speech perception. It thus entails the study of the relationships between speech stimuli and a listener's responses to such stimuli as mediated by mechanisms of the peripheral and central auditory systems, including certain areas of the brain. It is said to compose one of the three main branches of phonetics along with acoustic and articulatory phonetics, though with overlapping methods and questions.
Phonological awareness is an individual's awareness of the phonological structure, or sound structure, of words. Phonological awareness is an important and reliable predictor of later reading ability and has, therefore, been the focus of much research.

Caleb Gattegno (1911–1988) was an Egyptian educator, psychologist, and mathematician. He is considered one of the most influential and prolific mathematics educators of the twentieth century. He is best known for introducing new approaches to teaching and learning mathematics, foreign languages and reading. Gattegno also developed pedagogical materials for each of these approaches, and was the author of more than 120 books and hundreds of articles largely on the topics of education and human development.
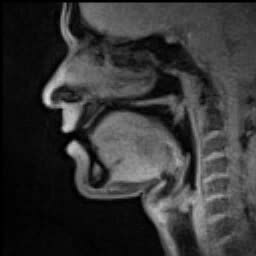
Speech is a human vocal communication using language. Each language uses phonetic combinations of vowel and consonant sounds that form the sound of its words, and using those words in their semantic character as words in the lexicon of a language according to the syntactic constraints that govern lexical words' function in a sentence. In speaking, speakers perform many different intentional speech acts, e.g., informing, declaring, asking, persuading, directing, and can use enunciation, intonation, degrees of loudness, tempo, and other non-representational or paralinguistic aspects of vocalization to convey meaning. In their speech, speakers also unintentionally communicate many aspects of their social position such as sex, age, place of origin, physical states, psychological states, physico-psychological states, education or experience, and the like.

Kenneth Noble Stevens was the Clarence J. LeBel Professor of Electrical Engineering and Computer Science, and professor of health sciences and technology at the research laboratory of electronics at MIT. Stevens was head of the speech communication group in MIT's research laboratory of electronics (RLE), and was one of the world's leading scientists in acoustic phonetics.
Accent reduction, also known as accent modification or accent neutralization, is a systematic approach for learning or adopting a new speech accent. It is the process of learning the sound system and melodic intonation of a language so the non-native speaker can communicate with clarity.
Speech perception is the process by which the sounds of language are heard, interpreted, and understood. The study of speech perception is closely linked to the fields of phonology and phonetics in linguistics and cognitive psychology and perception in psychology. Research in speech perception seeks to understand how human listeners recognize speech sounds and use this information to understand spoken language. Speech perception research has applications in building computer systems that can recognize speech, in improving speech recognition for hearing- and language-impaired listeners, and in foreign-language teaching.

Haskins Laboratories, Inc. is an independent 501(c) non-profit corporation, founded in 1935 and located in New Haven, Connecticut, since 1970. Haskins has formal affiliation agreements with both Yale University and the University of Connecticut; it remains fully independent, administratively and financially, of both Yale and UConn. Haskins is a multidisciplinary and international community of researchers that conducts basic research on spoken and written language. A guiding perspective of their research is to view speech and language as emerging from biological processes, including those of adaptation, response to stimuli, and conspecific interaction. Haskins Laboratories has a long history of technological and theoretical innovation, from creating systems of rules for speech synthesis and development of an early working prototype of a reading machine for the blind to developing the landmark concept of phonemic awareness as the critical preparation for learning to read an alphabetic writing system.
Catherine Phebe Browman was an American linguist and speech scientist. She received her Ph.D. in linguistics from the University of California, Los Angeles (UCLA) in 1978. Browman was a research scientist at Bell Laboratories in New Jersey (1967–1972). While at Bell Laboratories, she was known for her work on speech synthesis using demisyllables. She later worked as researcher at Haskins Laboratories in New Haven, Connecticut (1982–1998). She was best known for developing, with Louis Goldstein, of the theory of articulatory phonology, a gesture-based approach to phonological and phonetic structure. The theoretical approach is incorporated in a computational model that generates speech from a gesturally-specified lexicon. Browman was made an honorary member of the Association for Laboratory Phonology.
A speech sound disorder (SSD) is a speech disorder in which some sounds (phonemes) are not produced or used correctly. The term "protracted phonological development" is sometimes preferred when describing children's speech, to emphasize the continuing development while acknowledging the delay.

Japanese has one liquid phoneme, realized usually as an apico-alveolar tap and sometimes as an alveolar lateral approximant. English has two: rhotic and lateral, with varying phonetic realizations centered on the postalveolar approximant and on the alveolar lateral approximant, respectively. Japanese speakers who learn English as a second language later than childhood often have difficulty in hearing and producing the and of English accurately.
The phonology of second languages is different from the phonology of first languages in various ways. The differences are considered to come from general characteristics of second languages, such as slower speech rate, lower proficiency than native speakers, and from the interaction between non-native speakers' first and second languages.
Language pedagogy is the discipline concerned with the theories and techniques of teaching language. It has been described as a type of teaching wherein the teacher draws from their own prior knowledge and actual experience in teaching language. The approach is distinguished from research-based methodologies.

The Silent Way is a language-teaching approach created by Caleb Gattegno that makes extensive use of silence as a teaching method. Gattegno introduced the method in 1963, in his book Teaching Foreign Languages in Schools: The Silent Way. Gattegno was critical of mainstream language education at the time, and he based the method on his general theories of education rather than on existing language pedagogy. It is usually regarded as an "alternative" language-teaching method; Cook groups it under "other styles", Richards groups it under "alternative approaches and methods" and Jin & Cortazzi group it under "Humanistic or Alternative Approaches".
In phonetics, the basis of articulation, also known as articulatory setting, is the default position or standard settings of a speaker's organs of articulation when ready to speak. Different languages each have their own basis of articulation, which means that native speakers will share a certain position of tongue, lips, jaw, possibly even uvula or larynx, when preparing to speak. These standard settings enable them to produce the sounds and prosody of their native language more efficiently. Beatrice Honikman suggests thinking of it in terms of having a "gear" for English, another for French, and so on depending on which language is being learned; in the classroom, when working on pronunciation, the first thing the learner must do is to think themselves into the right gear before starting on pronunciation exercises. Jenner (2001) gives a detailed account of how this idea arose and how Honikman has been credited with its invention despite a considerable history of prior study.
References
- ↑ Celce-Murcia, Marianne; Brinton, Donna; Goodwin, Janet (2010). Teaching Pronunciation (2 ed.). CUP. p. 2. ISBN 978-0521729765.
- ↑ N.S.Trubetzkoy, N.S. (1939) Grundzüge der Phonologie (Principles of Phonology), p.51
- ↑ Logan, John; Lively, Scott; Pisoni, David (1991). "Training Japanese listeners to identify English /r/ and /l/: A first report". J Acoust Soc Am. 89 (2): 874–886. Bibcode:1991ASAJ...89..874L. doi:10.1121/1.1894649. PMC 3518834 . PMID 2016438.
- ↑ Iverson, Paul; Hazan, Valerie; Bannister, Kerry (2005). "Phonetic training with acoustic cue manipulations: A comparison of methods for teaching English /r/-/l/ to Japanese adults". J Acoust Soc Am. 118 (5): 3267–3278. doi:10.1121/1.2062307. PMID 16334698.
- ↑ Linebaugh, Gary; Roche, Thomas (2015). "Evidence that L2 production training can enhance perception". Journal of Academic Language & Learning. 9 (1): 1–17.
- ↑ Sweet, H. (1877) A Handbook of Phonetics, London: MacMillan p.21
- ↑ Catford, J. C. (1988) A practical introduction to phonetics. Oxford: Clarendon Press p.v
- ↑ Catford, J. C. and Pisoni, D. B. (1970) Auditory vs. Articulatory Training in Exotic Sounds. The Modern Language Journal, 54: 477–481. doi : 10.1111/j.1540-4781.1970.tb03581.x
- ↑ Kho, Mu-Jeong (2016). How to Implant a Semiotic and Mathematical DNA into Learning English, Seoul: Booklab Publishing Co. ISBN 979-11-87300-04-5 (53740), 261 pages.
- ↑ Underhill, A. (2007) Sound Foundations: Learning and Teaching Pronunciation. London: Macmillan. ISBN 1405064102
- ↑ Messum, P. (2012) Teaching pronunciation without using imitation: Why and how. In. J. Levis & K. LeVelle (Eds.). Proceedings of the 3rd Pronunciation in Second Language Learning and Teaching Conference, Sept. 2011 (pp. 154–160). Ames, IA: Iowa State University
- ↑ Young R. (2012) Teaching Pronunciation Efficiently Means Not Using ‘Listen and Repeat’. Teaching Times (TESOL, France) 63:18