
An alpha helix is a sequence of amino acids in a protein that are twisted into a coil.
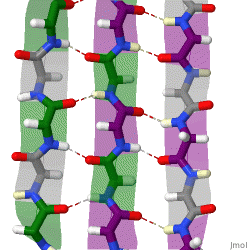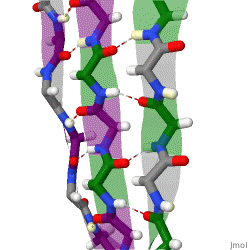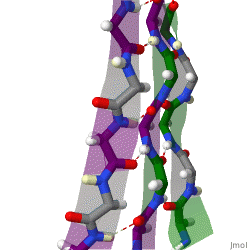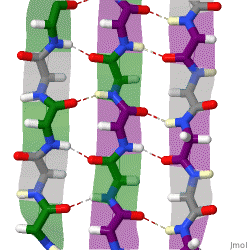
The beta sheet, (β-sheet) is a common motif of the regular protein secondary structure. Beta sheets consist of beta strands (β-strands) connected laterally by at least two or three backbone hydrogen bonds, forming a generally twisted, pleated sheet. A β-strand is a stretch of polypeptide chain typically 3 to 10 amino acids long with backbone in an extended conformation. The supramolecular association of β-sheets has been implicated in the formation of the fibrils and protein aggregates observed in amyloidosis, Alzheimer's disease and other proteinopathies.

Protein secondary structure is the local spatial conformation of the polypeptide backbone excluding the side chains. The two most common secondary structural elements are alpha helices and beta sheets, though beta turns and omega loops occur as well. Secondary structure elements typically spontaneously form as an intermediate before the protein folds into its three dimensional tertiary structure.

A protein contact map represents the distance between all possible amino acid residue pairs of a three-dimensional protein structure using a binary two-dimensional matrix. For two residues and , the element of the matrix is 1 if the two residues are closer than a predetermined threshold, and 0 otherwise. Various contact definitions have been proposed: The distance between the Cα-Cα atom with threshold 6-12 Å; distance between Cβ-Cβ atoms with threshold 6-12 Å ; and distance between the side-chain centers of mass.
A polyproline helix is a type of protein secondary structure which occurs in proteins comprising repeating proline residues. A left-handed polyproline II helix is formed when sequential residues all adopt (φ,ψ) backbone dihedral angles of roughly and have trans isomers of their peptide bonds. This PPII conformation is also common in proteins and polypeptides with other amino acids apart from proline. Similarly, a more compact right-handed polyproline I helix is formed when sequential residues all adopt (φ,ψ) backbone dihedral angles of roughly and have cis isomers of their peptide bonds. Of the twenty common naturally occurring amino acids, only proline is likely to adopt the cis isomer of the peptide bond, specifically the X-Pro peptide bond; steric and electronic factors heavily favor the trans isomer in most other peptide bonds. However, peptide bonds that replace proline with another N-substituted amino acid are also likely to adopt the cis isomer.

A 310 helix is a type of secondary structure found in proteins and polypeptides. Of the numerous protein secondary structures present, the 310-helix is the fourth most common type observed; following α-helices, β-sheets and reverse turns. 310-helices constitute nearly 10–15% of all helices in protein secondary structures, and are typically observed as extensions of α-helices found at either their N- or C- termini. Because of the α-helices tendency to consistently fold and unfold, it has been proposed that the 310-helix serves as an intermediary conformation of sorts, and provides insight into the initiation of α-helix folding.
β turns are the most common form of turns—a type of non-regular secondary structure in proteins that cause a change in direction of the polypeptide chain. They are very common motifs in proteins and polypeptides. Each consists of four amino acid residues. They can be defined in two ways:
- By the possession of an intra-main-chain hydrogen bond between the CO of residue i and the NH of residue i+3;
- By having a distance of less than 7Å between the Cα atoms of residues i and i+3.
The Walker A and Walker B motifs are protein sequence motifs, known to have highly conserved three-dimensional structures. These were first reported in ATP-binding proteins by Walker and co-workers in 1982.
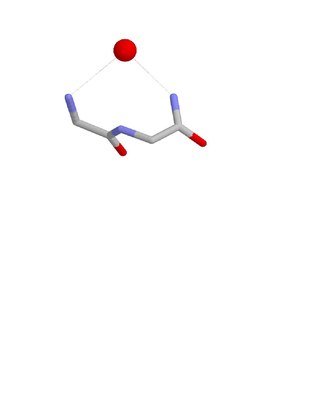
The Nest is a type of protein structural motif. It is a small recurring anion-binding feature of both proteins and peptides. Each consists of the main chain atoms of three consecutive amino acid residues. The main chain NH groups bind the anions while the side chain atoms are often not involved. Proline residues lack NH groups so are rare in nests. About one in 12 of amino acid residues in proteins, on average, belongs to a nest.
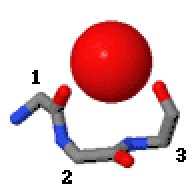
In the area of protein structural motifs, niches are three or four amino acid residue features in which main-chain CO groups are bridged by positively charged or δ+ groups. The δ+ groups include groups with two hydrogen bond donor atoms such as NH2 groups and water molecules. In typical proteins, 7% of amino acid residues belong to niches bound to a δ+ group, while another 7% have the conformation but no single cationic bridging group is detected.

Schellman loops are commonly occurring structural features of proteins and polypeptides. Each has six amino acid residues with two specific inter-mainchain hydrogen bonds and a characteristic main chain dihedral angle conformation. The CO group of residue i is hydrogen-bonded to the NH of residue i+5, and the CO group of residue i+1 is hydrogen-bonded to the NH of residue i+4. Residues i+1, i+2, and i+3 have negative φ (phi) angle values and the phi value of residue i+4 is positive. Schellman loops incorporate a three amino acid residue RL nest, in which three mainchain NH groups form a concavity for hydrogen bonding to carbonyl oxygens. About 2.5% of amino acids in proteins belong to Schellman loops. Two websites are available for examining small motifs in proteins, Motivated Proteins: ; or PDBeMotif:.
The Asx turn is a structural feature in proteins and polypeptides. It consists of three amino acid residues in which residue i is an aspartate (Asp) or asparagine (Asn) that forms a hydrogen bond from its sidechain CO group to the mainchain NH group of residue i+2. About 14% of Asx residues present in proteins belong to Asx turns.
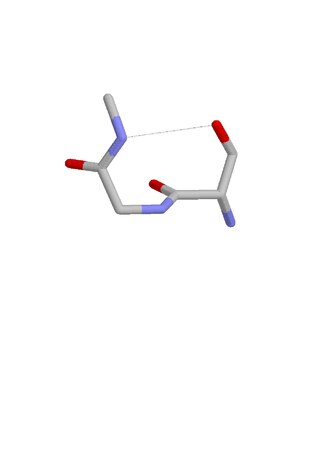
The ST turn is a structural feature in proteins and polypeptides. Each consists of three amino acid residues in which residue i is a serine (S) or threonine (T) that forms a hydrogen bond from its sidechain oxygen group to the mainchain NH group of residue i + 2.
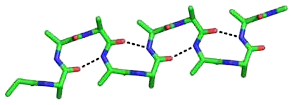
The beta bend ribbon, or beta-bend ribbon, is a structural feature in polypeptides and proteins. The shortest possible has six amino acid residues arranged as two overlapping hydrogen bonded beta turns in which the carbonyl group of residue i is hydrogen-bonded to the NH of residue i+3 while the carbonyl group of residue i+2 is hydrogen-bonded to the NH of residue i+5. In longer ribbons, this bonding is continued in peptides of 8, 10, etc., amino acid residues. A beta bend ribbon can be regarded as an aberrant 310 helix (3/10-helix) that has lost some of its hydrogen bonds. Two websites are available to facilitate finding and examining these features in proteins: Motivated Proteins; and PDBeMotif.

The ST motif is a commonly occurring feature in proteins and polypeptides. It consists of four or five amino acid residues with either serine or threonine as the first residue. It is defined by two internal hydrogen bonds. One is between the side chain oxygen of residue i and the main chain NH of residue i + 2 or i + 3; the other is between the main chain oxygen of residue i and the main chain NH of residue i + 3 or i + 4. Two websites are available for finding and examining ST motifs in proteins, Motivated Proteins: and PDBeMotif.
The term N cap describes an amino acid in a particular position within a protein or polypeptide. The N cap residue of an alpha helix is the first amino acid residue at the N terminus of the helix. More precisely, it is defined as the first residue (i) whose CO group is hydrogen-bonded to the NH group of residue i+4. Because of this it is sometimes also described as the residue prior to the helix.
The term C cap describes an amino acid in a particular position within a protein or polypeptide. The C cap residue of an alpha helix is the last amino acid residue at the C terminus of the helix. More precisely, it is defined as the last residue (i) whose NH group is hydrogen-bonded to the CO group of residue i-4. Because of this it is sometimes also described as the residue following the helix.
Amide Rings are small motifs in proteins and polypeptides. They consist of 9-atom or 11-atom rings formed by two CO...HN hydrogen bonds between a side chain amide group and the main chain atoms of a short polypeptide. They are observed with glutamine or asparagine side chains within proteins and polypeptides. Structurally similar rings occur in the binding of purine, pyrimidine and nicotinamide bases to the main chain atoms of proteins. About 4% of asparagines and glutamines form amide rings; in databases of protein domain structures, one is present, on average, every other protein.

Beta bulge loops are commonly occurring motifs in proteins and polypeptides consisting of five to six amino acids. There are two types: type 1, which is a pentapeptide; and type 2, with six amino acids. They are regarded as a type of beta bulge, and have the alternative name of type G1 beta bulge. Compared to other beta bulges, beta bulge loops give rise to chain reversal such that they often occur at the loop ends of beta hairpins; hairpins of this sort can be described as 3:5 or 4:6. Two websites are available for finding and examining β bulge loops in proteins, Motivated Proteins: and PDBeMotif:.
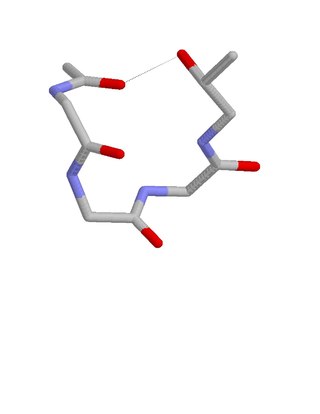
The ST staple is a common four- or five-amino acid residue motif in proteins and polypeptides with serine or threonine as the C-terminal residue. It is characterized by a single hydrogen bond between the hydroxyl group of the serine or threonine and the main chain carbonyl group of residue i. Motifs are of two types, depending whether the motif has 4 or 5 residues. Most ST staples occur in conjunction with an alpha helix, and are usually associated with a slight bend in the helix. Two websites are available for finding and examining ST staples in proteins: Motivated Proteins and PDBeMotif.
