
In computer programming, a string is traditionally a sequence of characters, either as a literal constant or as some kind of variable. The latter may allow its elements to be mutated and the length changed, or it may be fixed. A string is generally considered as a data type and is often implemented as an array data structure of bytes that stores a sequence of elements, typically characters, using some character encoding. String may also denote more general arrays or other sequence data types and structures.
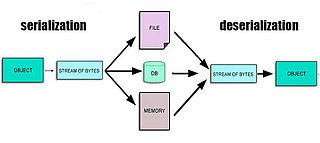
In computing, serialization is the process of translating a data structure or object state into a format that can be stored or transmitted and reconstructed later. When the resulting series of bits is reread according to the serialization format, it can be used to create a semantically identical clone of the original object. For many complex objects, such as those that make extensive use of references, this process is not straightforward. Serialization of objects does not include any of their associated methods with which they were previously linked.
Extensible Markup Language (XML) is a markup language and file format for storing, transmitting, and reconstructing arbitrary data. It defines a set of rules for encoding documents in a format that is both human-readable and machine-readable. The World Wide Web Consortium's XML 1.0 Specification of 1998 and several other related specifications—all of them free open standards—define XML.

In computer programming, an S-expression is an expression in a like-named notation for nested list (tree-structured) data. S-expressions were invented for and popularized by the programming language Lisp, which uses them for source code as well as data.
Abstract Syntax Notation One (ASN.1) is a standard interface description language (IDL) for defining data structures that can be serialized and deserialized in a cross-platform way. It is broadly used in telecommunications and computer networking, and especially in cryptography.
XSD, a recommendation of the World Wide Web Consortium (W3C), specifies how to formally describe the elements in an Extensible Markup Language (XML) document. It can be used by programmers to verify each piece of item content in a document, to assure it adheres to the description of the element it is placed in.
YAML is a human-readable data serialization language. It is commonly used for configuration files and in applications where data is being stored or transmitted. YAML targets many of the same communications applications as Extensible Markup Language (XML) but has a minimal syntax that intentionally differs from Standard Generalized Markup Language (SGML). It uses Python-style indentation to indicate nesting and does not require quotes around most string values.
In computer science, canonicalization is a process for converting data that has more than one possible representation into a "standard", "normal", or canonical form. This can be done to compare different representations for equivalence, to count the number of distinct data structures, to improve the efficiency of various algorithms by eliminating repeated calculations, or to make it possible to impose a meaningful sorting order.
Bencode is the encoding used by the peer-to-peer file sharing system BitTorrent for storing and transmitting loosely structured data.
JSON is an open standard file format and data interchange format that uses human-readable text to store and transmit data objects consisting of name–value pairs and arrays. It is a commonly used data format with diverse uses in electronic data interchange, including that of web applications with servers.
Fast Infoset is an international standard that specifies a binary encoding format for the XML Information Set as an alternative to the XML document format. It aims to provide more efficient serialization than the text-based XML format.
In the macOS, iOS, NeXTSTEP, and GNUstep programming frameworks, property list files are files that store serialized objects. Property list files use the filename extension .plist, and thus are often referred to as p-list files.
Within communication protocols, TLV is an encoding scheme used for informational elements. A TLV-encoded data stream contains code related to the record type, the record value's length, and finally the value itself.
BSON is a computer data interchange format. The name "BSON" is based on the term JSON and stands for "Binary JSON". It is a binary form for representing simple or complex data structures including associative arrays, integer indexed arrays, and a suite of fundamental scalar types. BSON originated in 2009 at MongoDB. Several scalar data types are of specific interest to MongoDB and the format is used both as a data storage and network transfer format for the MongoDB database, but it can be used independently outside of MongoDB. Implementations are available in a variety of languages such as C, C++, C#, D, Delphi, Erlang, Go, Haskell, Java, JavaScript, Julia, Lua, OCaml, Perl, PHP, Python, Ruby, Rust, Scala, Smalltalk, and Swift.
This is a comparison of data serialization formats, various ways to convert complex objects to sequences of bits. It does not include markup languages used exclusively as document file formats.
X.690 is an ITU-T standard specifying several ASN.1 encoding formats:
Data Format Description Language is a modeling language for describing general text and binary data in a standard way. It was published as an Open Grid Forum Recommendation in February 2021, and in April 2024 was published as an ISO standard.
Universal Binary JSON (UBJSON) is a computer data interchange format. It is a binary form directly imitating JSON, but requiring fewer bytes of data. It aims to achieve the generality of JSON, combined with being much easier to process than JSON.
JSONiq is a query and functional programming language that is designed to declaratively query and transform collections of hierarchical and heterogeneous data in format of JSON, XML, as well as unstructured, textual data.
Ion is a data serialization language developed by Amazon. It may be represented by either a human-readable text form or a compact binary form. The text form is a superset of JSON; thus, any valid JSON document is also a valid Ion document.