In statistics and computer software, a convolution random number generator is a pseudo-random number sampling method that can be used to generate random variates from certain classes of probability distribution. The particular advantage of this type of approach is that it allows advantage to be taken of existing software for generating random variates from other, usually non-uniform, distributions. However, faster algorithms may be obtainable for the same distributions by other more complicated approaches.
Statistics is a branch of mathematics dealing with data collection, organization, analysis, interpretation and presentation. In applying statistics to, for example, a scientific, industrial, or social problem, it is conventional to begin with a statistical population or a statistical model process to be studied. Populations can be diverse topics such as "all people living in a country" or "every atom composing a crystal". Statistics deals with all aspects of data, including the planning of data collection in terms of the design of surveys and experiments. See glossary of probability and statistics.
Pseudo-random number sampling or non-uniform pseudo-random variate generation is the numerical practice of generating pseudo-random numbers that are distributed according to a given probability distribution.
In the mathematical fields of probability and statistics, a random variate is a particular outcome of a random variable: the random variates which are other outcomes of the same random variable might have different values. A random deviate or simply deviate is the difference of random variate with respect to the distribution central location, often divided by the standard deviation of the distribution.
A number of distributions can be expressed in terms of the (possibly weighted) sum of two or more random variables from other distributions. (The distribution of the sum is the convolution of the distributions of the individual random variables).
In probability and statistics, a random variable, random quantity, aleatory variable, or stochastic variable is a variable whose possible values are outcomes of a random phenomenon. More specifically, a random variable is defined as a function that maps the outcomes of an unpredictable process to numerical quantities, typically real numbers. It is a variable, in the sense that it depends on the outcome of an underlying process providing the input to this function, and it is random in the sense that the underlying process is assumed to be random.
In mathematics convolution is a mathematical operation on two functions to produce a third function that expresses how the shape of one is modified by the other. The term convolution refers to both the result function and to the process of computing it. Convolution is similar to cross-correlation. For real-valued functions, of a continuous or discrete variable, it differs from cross-correlation only in that either f (x) or g(x) is reflected about the y-axis; thus it is a cross-correlation of f (x) and g(−x), or f (−x) and g(x). For continuous functions, the cross-correlation operator is the adjoint of the convolution operator.
Example
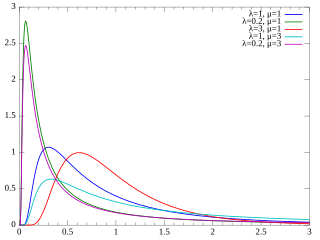
Consider the problem of generating a random variable with an Erlang distribution, . Such a random variable can be defined as the sum of k random variables each with an exponential distribution. This problem is equivalent to generating a random number for a special case of the Gamma distribution, in which the shape parameter takes an integer value.
The Erlang distribution is a two-parameter family of continuous probability distributions with support . The two parameters are:
In probability theory and statistics, the exponential distribution is the probability distribution that describes the time between events in a Poisson point process, i.e., a process in which events occur continuously and independently at a constant average rate. It is a particular case of the gamma distribution. It is the continuous analogue of the geometric distribution, and it has the key property of being memoryless. In addition to being used for the analysis of Poisson point processes it is found in various other contexts.
In probability theory and statistics, the gamma distribution is a two-parameter family of continuous probability distributions. The exponential distribution, Erlang distribution, and chi-squared distribution are special cases of the gamma distribution. There are three different parametrizations in common use:
With a shape parameter k and a scale parameter θ.
With a shape parameter α = k and an inverse scale parameter β = 1/θ, called a rate parameter.
With a shape parameter k and a mean parameter μ = kθ = α/β.
Notice that:
One can now generate samples using a random number generator for the exponential distribution:
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.
Related Research Articles
In probability theory and statistics, the chi-squared distribution with k degrees of freedom is the distribution of a sum of the squares of k independent standard normal random variables. The chi-squared distribution is a special case of the gamma distribution and is one of the most widely used probability distributions in inferential statistics, notably in hypothesis testing or in construction of confidence intervals. When it is being distinguished from the more general noncentral chi-squared distribution, this distribution is sometimes called the central chi-squared distribution.
In statistics, maximum likelihood estimation (MLE) is a method of estimating the parameters of a statistical model, given observations. The method obtains the parameter estimates by finding the parameter values that maximize the likelihood function. The estimates are called maximum likelihood estimates, which is also abbreviated as MLE.
In probability and statistics, an exponential family is a parametric set of probability distributions of a certain form, specified below. This special form is chosen for mathematical convenience, based on some useful algebraic properties, as well as for generality, as exponential families are in a sense very natural sets of distributions to consider. The term exponential class is sometimes used in place of "exponential family", or the older term Koopman-Darmois family. The terms "distribution" and "family" are often used loosely: properly, an exponential family is a set of distributions, where the specific distribution varies with the parameter; however, a parametric family of distributions is often referred to as "a distribution", and the set of all exponential families is sometimes loosely referred to as "the" exponential family.
In numerical analysis, rejection sampling is a basic technique used to generate observations from a distribution. It is also commonly called the acceptance-rejection method or "accept-reject algorithm" and is a type of exact simulation method. The method works for any distribution in
with a density.
In probability theory and statistics, the Laplace distribution is a continuous probability distribution named after Pierre-Simon Laplace. It is also sometimes called the double exponential distribution, because it can be thought of as two exponential distributions spliced together back-to-back, although the term is also sometimes used to refer to the Gumbel distribution. The difference between two independent identically distributed exponential random variables is governed by a Laplace distribution, as is a Brownian motion evaluated at an exponentially distributed random time. Increments of Laplace motion or a variance gamma process evaluated over the time scale also have a Laplace distribution.
In probability and statistics, the Dirichlet distribution, often denoted
, is a family of continuous multivariate probability distributions parameterized by a vector
of positive reals. It is a multivariate generalization of the beta distribution, hence its alternative name of Multivariate Beta distribution (MBD). Dirichlet distributions are commonly used as prior distributions in Bayesian statistics, and in fact the Dirichlet distribution is the conjugate prior of the categorical distribution and multinomial distribution.
In probability theory the hypoexponential distribution or the generalized Erlang distribution is a continuous distribution, that has found use in the same fields as the Erlang distribution, such as queueing theory, teletraffic engineering and more generally in stochastic processes. It is called the hypoexponetial distribution as it has a coefficient of variation less than one, compared to the hyper-exponential distribution which has coefficient of variation greater than one and the exponential distribution which has coefficient of variation of one.
In probability theory and statistics, the characteristic function of any real-valued random variable completely defines its probability distribution. If a random variable admits a probability density function, then the characteristic function is the Fourier transform of the probability density function. Thus it provides the basis of an alternative route to analytical results compared with working directly with probability density functions or cumulative distribution functions. There are particularly simple results for the characteristic functions of distributions defined by the weighted sums of random variables.
In probability theory, the inverse Gaussian distribution is a two-parameter family of continuous probability distributions with support on (0,∞).
In probability and statistics, a natural exponential family (NEF) is a class of probability distributions that is a special case of an exponential family (EF). Every distribution possessing a moment-generating function is a member of a natural exponential family, and the use of such distributions simplifies the theory and computation of generalized linear models.
The Nakagami distribution or the Nakagami-m distribution is a probability distribution related to the gamma distribution. The family of Nakagami distributions has two parameters: a shape parameter
and a second parameter controlling spread
.
In probability and statistics, the class of exponential dispersion models (EDM) is a set of probability distributions that represents a generalisation of the natural exponential family.
Exponential dispersion models play an important role in statistical theory, in particular in generalized linear models because they have a special structure which enables deductions to be made about appropriate statistical inference.
In probability theory and statistics, the Poisson distribution, named after French mathematician Siméon Denis Poisson, is a discrete probability distribution that expresses the probability of a given number of events occurring in a fixed interval of time or space if these events occur with a known constant rate and independently of the time since the last event. The Poisson distribution can also be used for the number of events in other specified intervals such as distance, area or volume.
A product distribution is a probability distribution constructed as the distribution of the product of random variables having two other known distributions. Given two statistically independent random variables X and Y, the distribution of the random variable Z that is formed as the product
In probability and statistics, a compound probability distribution is the probability distribution that results from assuming that a random variable is distributed according to some parametrized distribution, with the parameters of that distribution themselves being random variables.
In probability theory and statistics, the Hermite distribution, named after Charles Hermite, is a discrete probability distribution used to model count data with more than one parameter. This distribution is flexible in terms of its ability to allow a moderate over-dispersion in the data.
In statistics, the variance function is a smooth function which depicts the variance of a random quantity as a function of its mean. The variance function plays a large role in many settings of statistical modelling. It is a main ingredient in the generalized linear model framework and a tool used in non-parametric regression, semiparametric regression and functional data analysis. In parametric modeling, variance functions take on a parametric form and explicitly describe the relationship between the variance and the mean of a random quantity. In a non-parametric setting, the variance function is assumed to be a smooth function.