In digital signal processing, spatial anti-aliasing is a technique for minimizing the distortion artifacts known as aliasing when representing a high-resolution image at a lower resolution. Anti-aliasing is used in digital photography, computer graphics, digital audio, and many other applications.

Texture mapping is a method for defining high frequency detail, surface texture, or color information on a computer-generated graphic or 3D model. The original technique was pioneered by Edwin Catmull in 1974.

Shading refers to the depiction of depth perception in 3D models or illustrations by varying the level of darkness. Shading tries to approximate local behavior of light on the object's surface and is not to be confused with techniques of adding shadows, such as shadow mapping or shadow volumes, which fall under global behavior of light.

The Sobel operator, sometimes called the Sobel–Feldman operator or Sobel filter, is used in image processing and computer vision, particularly within edge detection algorithms where it creates an image emphasising edges. It is named after Irwin Sobel and Gary Feldman, colleagues at the Stanford Artificial Intelligence Laboratory (SAIL). Sobel and Feldman presented the idea of an "Isotropic 3x3 Image Gradient Operator" at a talk at SAIL in 1968. Technically, it is a discrete differentiation operator, computing an approximation of the gradient of the image intensity function. At each point in the image, the result of the Sobel–Feldman operator is either the corresponding gradient vector or the norm of this vector. The Sobel–Feldman operator is based on convolving the image with a small, separable, and integer-valued filter in the horizontal and vertical directions and is therefore relatively inexpensive in terms of computations. On the other hand, the gradient approximation that it produces is relatively crude, in particular for high-frequency variations in the image.

The Canny edge detector is an edge detection operator that uses a multi-stage algorithm to detect a wide range of edges in images. It was developed by John F. Canny in 1986. Canny also produced a computational theory of edge detection explaining why the technique works.

A Bayer filter mosaic is a color filter array (CFA) for arranging RGB color filters on a square grid of photosensors. Its particular arrangement of color filters is used in most single-chip digital image sensors used in digital cameras, camcorders, and scanners to create a color image. The filter pattern is half green, one quarter red and one quarter blue, hence is also called BGGR,RGBG, GRBG, or RGGB.

In mathematics, bilinear interpolation is an extension of linear interpolation for interpolating functions of two variables on a rectilinear 2D grid.

In mathematics, bicubic interpolation is an extension of cubic interpolation for interpolating data points on a two-dimensional regular grid. The interpolated surface is smoother than corresponding surfaces obtained by bilinear interpolation or nearest-neighbor interpolation. Bicubic interpolation can be accomplished using either Lagrange polynomials, cubic splines, or cubic convolution algorithm.
Inverse distance weighting (IDW) is a type of deterministic method for multivariate interpolation with a known scattered set of points. The assigned values to unknown points are calculated with a weighted average of the values available at the known points.

Pixel-art scaling algorithms are graphical filters that are often used in video game console emulators to enhance hand-drawn 2D pixel art graphics. The re-scaling of pixel art is a specialist sub-field of image rescaling.

In image processing, a Gaussian blur is the result of blurring an image by a Gaussian function.

Lanczos filtering and Lanczos resampling are two applications of a mathematical formula. It can be used as a low-pass filter or used to smoothly interpolate the value of a digital signal between its samples. In the latter case it maps each sample of the given signal to a translated and scaled copy of the Lanczos kernel, which is a sinc function windowed by the central lobe of a second, longer, sinc function. The sum of these translated and scaled kernels is then evaluated at the desired points.

In computer graphics and digital imaging, imagescaling refers to the resizing of a digital image. In video technology, the magnification of digital material is known as upscaling or resolution enhancement.
Marching squares is a computer graphics algorithm that generates contours for a two-dimensional scalar field. A similar method can be used to contour 2D triangle meshes.
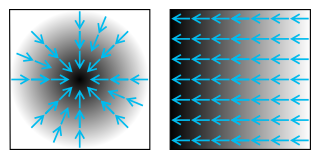
An image gradient is a directional change in the intensity or color in an image. The gradient of the image is one of the fundamental building blocks in image processing. For example, the Canny edge detector uses image gradient for edge detection. In graphics software for digital image editing, the term gradient or color gradient is also used for a gradual blend of color which can be considered as an even gradation from low to high values, as used from white to black in the images to the right. Another name for this is color progression.
A box blur is a spatial domain linear filter in which each pixel in the resulting image has a value equal to the average value of its neighboring pixels in the input image. It is a form of low-pass ("blurring") filter. A 3 by 3 box blur can be written as matrix
In computer vision, speeded up robust features (SURF) is a patented local feature detector and descriptor. It can be used for tasks such as object recognition, image registration, classification, or 3D reconstruction. It is partly inspired by the scale-invariant feature transform (SIFT) descriptor. The standard version of SURF is several times faster than SIFT and claimed by its authors to be more robust against different image transformations than SIFT.
In image processing, a kernel, convolution matrix, or mask is a small matrix. It is used for blurring, sharpening, embossing, edge detection, and more. This is accomplished by doing a convolution between a kernel and an image.
In image processing, line detection is an algorithm that takes a collection of n edge points and finds all the lines on which these edge points lie. The most popular line detectors are the Hough transform and convolution-based techniques.
Semi-global matching (SGM) is a computer vision algorithm for the estimation of a dense disparity map from a rectified stereo image pair, introduced in 2005 by Heiko Hirschmüller while working at the German Aerospace Center. Given its predictable run time, its favourable trade-off between quality of the results and computing time, and its suitability for fast parallel implementation in ASIC or FPGA, it has encountered wide adoption in real-time stereo vision applications such as robotics and advanced driver assistance systems.