
In probability theory and statistics, the exponential distribution or negative exponential distribution is the probability distribution of the time between events in a Poisson point process, i.e., a process in which events occur continuously and independently at a constant average rate. It is a particular case of the gamma distribution. It is the continuous analogue of the geometric distribution, and it has the key property of being memoryless. In addition to being used for the analysis of Poisson point processes it is found in various other contexts.

In probability theory and statistics, the gamma distribution is a two-parameter family of continuous probability distributions. The exponential distribution, Erlang distribution, and chi-squared distribution are special cases of the gamma distribution. There are two equivalent parameterizations in common use:
- With a shape parameter and a scale parameter .
- With a shape parameter and an inverse scale parameter , called a rate parameter.

In probability theory and statistics, the Gumbel distribution is used to model the distribution of the maximum of a number of samples of various distributions.

In probability and statistics, the Dirichlet distribution (after Peter Gustav Lejeune Dirichlet), often denoted , is a family of continuous multivariate probability distributions parameterized by a vector of positive reals. It is a multivariate generalization of the beta distribution, hence its alternative name of multivariate beta distribution (MBD). Dirichlet distributions are commonly used as prior distributions in Bayesian statistics, and in fact, the Dirichlet distribution is the conjugate prior of the categorical distribution and multinomial distribution.
In probability theory and statistics, the generalized extreme value (GEV) distribution is a family of continuous probability distributions developed within extreme value theory to combine the Gumbel, Fréchet and Weibull families also known as type I, II and III extreme value distributions. By the extreme value theorem the GEV distribution is the only possible limit distribution of properly normalized maxima of a sequence of independent and identically distributed random variables. Note that a limit distribution needs to exist, which requires regularity conditions on the tail of the distribution. Despite this, the GEV distribution is often used as an approximation to model the maxima of long (finite) sequences of random variables.
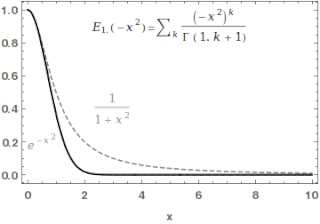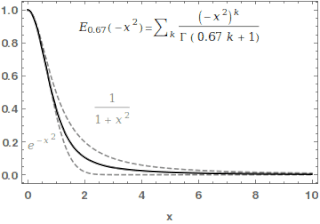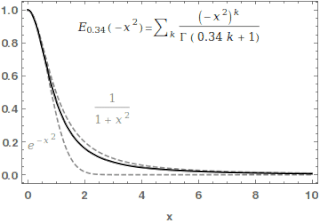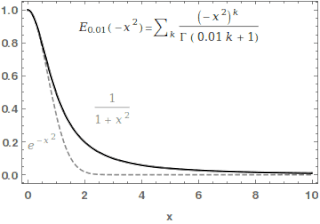
In mathematics, the Mittag-Leffler function is a special function, a complex function which depends on two complex parameters and . It may be defined by the following series when the real part of is strictly positive:

In probability theory and statistics, the inverse gamma distribution is a two-parameter family of continuous probability distributions on the positive real line, which is the distribution of the reciprocal of a variable distributed according to the gamma distribution.
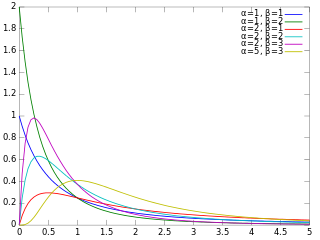
In probability theory and statistics, the beta prime distribution is an absolutely continuous probability distribution. If has a beta distribution, then the odds has a beta prime distribution.
In natural language processing, Latent Dirichlet Allocation (LDA) is a Bayesian network that explains a set of observations through unobserved groups, and each group explains why some parts of the data are similar. The LDA is an example of a Bayesian topic model. In this, observations are collected into documents, and each word's presence is attributable to one of the document's topics. Each document will contain a small number of topics.

In probability theory and statistics, the beta-binomial distribution is a family of discrete probability distributions on a finite support of non-negative integers arising when the probability of success in each of a fixed or known number of Bernoulli trials is either unknown or random. The beta-binomial distribution is the binomial distribution in which the probability of success at each of n trials is not fixed but randomly drawn from a beta distribution. It is frequently used in Bayesian statistics, empirical Bayes methods and classical statistics to capture overdispersion in binomial type distributed data.
In probability theory and statistics, the Dirichlet-multinomial distribution is a family of discrete multivariate probability distributions on a finite support of non-negative integers. It is also called the Dirichlet compound multinomial distribution (DCM) or multivariate Pólya distribution. It is a compound probability distribution, where a probability vector p is drawn from a Dirichlet distribution with parameter vector , and an observation drawn from a multinomial distribution with probability vector p and number of trials n. The Dirichlet parameter vector captures the prior belief about the situation and can be seen as a pseudocount: observations of each outcome that occur before the actual data is collected. The compounding corresponds to a Pólya urn scheme. It is frequently encountered in Bayesian statistics, machine learning, empirical Bayes methods and classical statistics as an overdispersed multinomial distribution.
A ratio distribution is a probability distribution constructed as the distribution of the ratio of random variables having two other known distributions. Given two random variables X and Y, the distribution of the random variable Z that is formed as the ratio Z = X/Y is a ratio distribution.
In probability theory and statistics, the normal-gamma distribution is a bivariate four-parameter family of continuous probability distributions. It is the conjugate prior of a normal distribution with unknown mean and precision.
In statistics, the generalized Dirichlet distribution (GD) is a generalization of the Dirichlet distribution with a more general covariance structure and almost twice the number of parameters. Random vectors with a GD distribution are completely neutral.

In probability theory and statistics, the normal-inverse-gamma distribution is a four-parameter family of multivariate continuous probability distributions. It is the conjugate prior of a normal distribution with unknown mean and variance.

In probability theory and statistics, the Poisson distribution is a discrete probability distribution that expresses the probability of a given number of events occurring in a fixed interval of time or space if these events occur with a known constant mean rate and independently of the time since the last event. It is named after French mathematician Siméon Denis Poisson. The Poisson distribution can also be used for the number of events in other specified interval types such as distance, area, or volume. It plays an important role for discrete-stable distributions.

The multivariate stable distribution is a multivariate probability distribution that is a multivariate generalisation of the univariate stable distribution. The multivariate stable distribution defines linear relations between stable distribution marginals. In the same way as for the univariate case, the distribution is defined in terms of its characteristic function.
In probability, statistics, economics, and actuarial science, the Benini distribution is a continuous probability distribution that is a statistical size distribution often applied to model incomes, severity of claims or losses in actuarial applications, and other economic data. Its tail behavior decays faster than a power law, but not as fast as an exponential. This distribution was introduced by Rodolfo Benini in 1905. Somewhat later than Benini's original work, the distribution has been independently discovered or discussed by a number of authors.
In probability theory, a beta negative binomial distribution is the probability distribution of a discrete random variable equal to the number of failures needed to get successes in a sequence of independent Bernoulli trials. The probability of success on each trial stays constant within any given experiment but varies across different experiments following a beta distribution. Thus the distribution is a compound probability distribution.
In statistics, the matrix t-distribution is the generalization of the multivariate t-distribution from vectors to matrices. The matrix t-distribution shares the same relationship with the multivariate t-distribution that the matrix normal distribution shares with the multivariate normal distribution. For example, the matrix t-distribution is the compound distribution that results from sampling from a matrix normal distribution having sampled the covariance matrix of the matrix normal from an inverse Wishart distribution.















