Upcoming conferences
| Conference | Year | City | Country | Date |
|---|---|---|---|---|
| ECMLPKDD | 2025 | Porto | September 15–19 | |
ECML PKDD, the European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases, is one of the leading [1] [2] academic conferences on machine learning and knowledge discovery, held in Europe every year.
ECML PKDD is a merger of two European conferences, European Conference on Machine Learning (ECML) and European Conference on Principles and Practice of Knowledge Discovery in Databases (PKDD). ECML and PKDD have been co-located since 2001; [3] however, both ECML and PKDD retained their own identity until 2007. For example, the 2007 conference was known as "the 18th European Conference on Machine Learning (ECML) and the 11th European Conference on Principles and Practice of Knowledge Discovery in Databases (PKDD)", or in brief, "ECML/PKDD 2007", and both ECML and PKDD had their own conference proceedings. In 2008 the conferences were merged into one conference, and the division into traditional ECML topics and traditional PKDD topics was removed. [4]
The history of ECML dates back to 1986, when the European Working Session on Learning was first held. In 1993 the name of the conference was changed to European Conference on Machine Learning.
PKDD was first organised in 1997. Originally PKDD stood for the European Symposium on Principles of Data Mining and Knowledge Discovery from Databases. [5] The name European Conference on Principles and Practice of Knowledge Discovery in Databases was used since 1999. [6]
| Conference | Year | City | Country | Date |
|---|---|---|---|---|
| ECMLPKDD | 2025 | Porto | September 15–19 | |
| Conference | Year | City | Country | Date |
|---|---|---|---|---|
| ECMLPKDD | 2024 | Vilnius | September 9–13 | |
| ECMLPKDD | 2023 | Turin | September 18–22 | |
| ECMLPKDD | 2022 | Grenoble | September 19–23 | |
| ECMLPKDD | 2021 | virtual | September 13–17 | |
| ECMLPKDD | 2020 | virtual | September 14-18 | |
| ECMLPKDD | 2019 | Würzburg | September 16–20 | |
| ECMLPKDD | 2018 | Dublin | September 10–14 | |
| ECMLPKDD | 2017 | Skopje | September 18–22 | |
| ECMLPKDD | 2016 | Riva del Garda | September 19–23 | |
| ECMLPKDD | 2015 | Porto | September 7–11 | |
| ECMLPKDD | 2014 | Nancy | September 15–19 | |
| ECMLPKDD | 2013 | Prague | September 23–27 | |
| ECML PKDD | 2012 | Bristol | | September 24–28 |
| ECML PKDD | 2011 | Athens | September 5–9 | |
| ECML PKDD | 2010 | Barcelona | September 20–24 | |
| ECML PKDD | 2009 | Bled | September 7–11 | |
| ECML PKDD | 2008 | Antwerp | September 15–19 | |
| 18th ECML/11th PKDD | 2007 | Warsaw | September 17–21 | |
| 17th ECML/10th PKDD | 2006 | Berlin | September 18–22 | |
| 16th ECML/9th PKDD | 2005 | Porto | October 3–7 | |
| 15th ECML/8th PKDD | 2004 | Pisa | September 20–24 | |
| 14th ECML/7th PKDD | 2003 | Cavtat/Dubrovnik | September 22–26 | |
| 13th ECML/6th PKDD | 2002 | Helsinki | August 19–23 | |
| 12th ECML/5th PKDD | 2001 | Freiburg | September 3–7 | |
| Conference | Year | City | Country | Date |
|---|---|---|---|---|
| 11th ECML | 2000 | Barcelona | May 30–June 2 | |
| 10th ECML | 1998 | Chemnitz | April 21–24 | |
| 9th ECML | 1997 | Prague | April 23–26 | |
| 8th ECML | 1995 | Heraclion | April 25–27 | |
| 7th ECML | 1994 | Catania | April 6–8 | |
| 6th ECML | 1993 | Vienna | April 5–7 | |
| 5th EWSL | 1991 | Porto | March 6–8 | |
| 4th EWSL | 1989 | Montpellier | December 4–6 | |
| 3rd EWSL | 1988 | Glasgow | | October 3–5 |
| 2nd EWSL | 1987 | Bled | May 13–15 | |
| 1st EWSL | 1986 | Orsay | February 3–4 | |
| Conference | Year | City | Country | Date |
|---|---|---|---|---|
| 4th PKDD | 2000 | Lyon | September 13–16 | |
| 3rd PKDD | 1999 | Prague | September 15–18 | |
| 2nd PKDD | 1998 | Nantes | September 23–26 | |
| 1st PKDD | 1997 | Trondheim | June 24–27 | |

Inductive logic programming (ILP) is a subfield of symbolic artificial intelligence which uses logic programming as a uniform representation for examples, background knowledge and hypotheses. The term "inductive" here refers to philosophical rather than mathematical induction. Given an encoding of the known background knowledge and a set of examples represented as a logical database of facts, an ILP system will derive a hypothesised logic program which entails all the positive and none of the negative examples.
In artificial intelligence, artificial immune systems (AIS) are a class of computationally intelligent, rule-based machine learning systems inspired by the principles and processes of the vertebrate immune system. The algorithms are typically modeled after the immune system's characteristics of learning and memory for use in problem-solving.
Data Stream Mining is the process of extracting knowledge structures from continuous, rapid data records. A data stream is an ordered sequence of instances that in many applications of data stream mining can be read only once or a small number of times using limited computing and storage capabilities.
In predictive analytics, data science, machine learning and related fields, concept drift or drift is an evolution of data that invalidates the data model. It happens when the statistical properties of the target variable, which the model is trying to predict, change over time in unforeseen ways. This causes problems because the predictions become less accurate as time passes. Drift detection and drift adaptation are of paramount importance in the fields that involve dynamically changing data and data models.
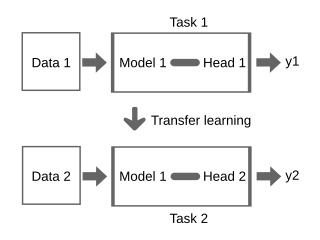
Transfer learning (TL) is a technique in machine learning (ML) in which knowledge learned from a task is re-used in order to boost performance on a related task. For example, for image classification, knowledge gained while learning to recognize cars could be applied when trying to recognize trucks. This topic is related to the psychological literature on transfer of learning, although practical ties between the two fields are limited. Reusing/transferring information from previously learned tasks to new tasks has the potential to significantly improve learning efficiency.

Stephen H. Muggleton is Professor of Machine Learning and Head of the Computational Bioinformatics Laboratory at Imperial College London.
Active learning is a special case of machine learning in which a learning algorithm can interactively query a human user, to label new data points with the desired outputs. The human user must possess knowledge/expertise in the problem domain, including the ability to consult/research authoritative sources when necessary. In statistics literature, it is sometimes also called optimal experimental design. The information source is also called teacher or oracle.
The Mexican International Conference on Artificial Intelligence (MICAI) is the name of an annual conference covering all areas of Artificial Intelligence (AI), held in Mexico. The first MICAI conference was held in 2000. The conference is attended every year by about two hundred of AI researchers and PhD students and 500−1000 local graduate students.
Inductive programming (IP) is a special area of automatic programming, covering research from artificial intelligence and programming, which addresses learning of typically declarative and often recursive programs from incomplete specifications, such as input/output examples or constraints.
Social media mining is the process of obtaining data from user-generated content on social media in order to extract actionable patterns, form conclusions about users, and act upon the information. Mining supports targeting advertising to users or academic research. The term is an analogy to the process of mining for minerals. Mining companies sift through raw ore to find the valuable minerals; likewise, social media mining sifts through social media data in order to discern patterns and trends about matters such as social media usage, online behaviour, content sharing, connections between individuals, buying behaviour. These patterns and trends are of interest to companies, governments and not-for-profit organizations, as such organizations can use the analyses for tasks such as design strategies, introduce programs, products, processes or services.

Author name disambiguation is the process of disambiguation and record linkage applied to the names of individual people. The process could, for example, distinguish individuals with the name "John Smith".
Longbing Cao is an AI and data science researcher at the University of Technology Sydney, Australia. His broad research interest involves artificial intelligence, data science, behavior informatics, and their enterprise applications.
Agent mining is an interdisciplinary area that synergizes multiagent systems with data mining and machine learning.
The International Conference on Agents and Artificial Intelligence (ICAART) is a meeting point for researchers with interest in the areas of Agents and Artificial Intelligence. There are 2 tracks in ICAART, one related to Agents and Distributed AI in general and the other one focused in topics related to Intelligent Systems and Computational Intelligence.

Martine-Michèle Sebag is a French computer scientist, primarily focused on machine learning. She has over 6,000 citations.
Michael Genesereth is an American logician and computer scientist, who is most known for his work on computational logic and applications of that work in enterprise management, computational law, and general game playing. Genesereth is professor in the Computer Science Department at Stanford University and a professor by courtesy in the Stanford Law School. His 1987 textbook on Logical Foundations of Artificial Intelligence remains one of the key references on symbolic artificial intelligence. He is the author of the influential Game Description Language (GDL) and Knowledge Interchange Format (KIF), the latter of which led to the ISO Common Logic standard.

Bruce Martin McLaren is an American researcher, scientist and author. He is a professor at Carnegie Mellon University in the Human-Computer Interaction Institute, head of the McLearn Lab, and a former President of the International Artificial Intelligence in Education Society (2017-2019).
In machine learning and data mining, quantification is the task of using supervised learning in order to train models (quantifiers) that estimate the relative frequencies of the classes of interest in a sample of unlabelled data items. For instance, in a sample of 100,000 unlabelled tweets known to express opinions about a certain political candidate, a quantifier may be used to estimate the percentage of these 100,000 tweets which belong to class `Positive', and to do the same for classes `Neutral' and `Negative'.

Nitesh V. Chawla is a computer scientist and data scientist currently serving as the Frank M. Freimann Professor of Computer Science and Engineering at the University of Notre Dame. He is the Founding Director of the Lucy Family Institute for Data & Society. Chawla's research expertise lies in machine learning, data science, and network science. He is also the co-founder of Aunalytics, a data science software and cloud computing company. Chawla is a Fellow of the: American Association for the Advancement of Sciences (AAAS), Association for Computing Machinery (ACM), Association for the Advancement of Artificial Intelligence, Asia Pacific Artificial Intelligence Association, and Institute of Electrical and Electronics Engineers (IEEE). He has received multiple awards, including the 1st Source Bank Commercialization Award in 2017, Outstanding Teaching Award (twice), IEEE CIS Early Career Award, National Academy of Engineering New Faculty Award, and the IBM Big Data Award in 2013. One of Chawla's most recognized publications, with a citation count of over 30,000, is the research paper titled "SMOTE: Synthetic Minority Over-sampling Technique." Chawla's research has garnered a citation count of over 65,000 and an H-index of 81.
| International | |
|---|---|
| National | |