Family with sequence similarity 98, member A, or FAM98A, is a gene that in the human genome encodes the FAM98A protein. FAM98A has two paralogs in humans, FAM98B and FAM98C. All three are characterized by DUF2465, a conserved domain shown to bind to RNA.[5] FAM98A is also characterized by a glycine-rich C-terminal domain.[6] FAM98A also has homologs in vertebrates and invertebrates and has distant homologs in choanoflagellates and green algae.
The FAM98A gene is located on 2p22.3 in humans on the "-" (minus) strand. Including the 5' and 3' UTR, the gene spans 15,634 bases and contains 8 exons.[7]
mRNA
The mRNA is 2745bp, comprising the 8 exons. The coding sequence starts at base 75 and continues until base 1631. The polyA tail signal sequence is a six-nucleotide sequence 20 bases from the 3' end of the transcript at base 2725-2730, and the polyA site is at base 2745.[8]
Protein
Primary Sequence
FAM98A is 518 amino acids in length with a molecular weight of 55.3 kDa, without modifications. Residues 10-329 comprise the DUF2465, and the remainder of the protein is a diglycine-rich C terminus. Glycine makes up approximately 20% of the protein, with the majority of these in the last 200 residues.[9]
Post-Translational Modifications
FAM98A has six strongly predicted phosphorylation sites in DUF2465. These sites are predicted to phosphorylate S169, T178, S236, T243, S276, and S285 by protein kinase C.[10] GPS also predicts phosphorylation by protein kinase C at S285 and T178.[11] FAM98A is likely sumoylated at K183 and K195.[12] Sumoylation may allow the cell to re-localize FAM98A between the nucleus and the cytoplasm.[13] The glycine-rich C terminus has repeat GRG sequences, which has been shown to be susceptible to methylation of the arginine, either symmetrically or asymmetrically.[14] Another paper explains the effects of arginine methylation on biochemical functions such as transcription activation and repression, mRNA splicing, nuclear-cytosolic shuttling, and DNA repair.[15]
Secondary Structure
The N terminus is predicted to have multiple alpha helices, though the C terminus likely is only coiled.[16] The alpha helices do not form any channel, and FAM98A is not a transmembrane protein.
Tertiary and Quaternary Structure
The structure of FAM98A was predicted with the program Phyre2. The N-terminal region contains several alpha helices, and a C-terminal coiled region corresponding to the glycine-rich C terminus. These two regions of the protein are connected by an alpha helix approximately 50 residues long from the residues 200-256. Phyre2 found the most similar protein to be the human protein NDC80 kinetochore complex component, a nuclear protein that binds to microtubules.[17]
Domains and Motifs
FAM98A has a domain of unknown function 2465 (DUF2465) from the amino acids 10-329. Within the DUF2465, there is a heptide (VPDRGGR) near the C-terminal end that is conserved in all species tested. The C-terminal end is a glycine-rich domain (glycine makes up about 40% of the C terminus) with GGRGGR repeats.[9] At residues 149-155, there is a predicted nuclear export signal, with the sequence ICIALGM (generally [LIVFM]-X-[LIVFM]-X-[LIVFM]-X-[LIVFM]).[18] Residues 173-176 are predicted to be a nuclear localization signal KKLK (K-[K/R]-X-[K/R]).[19]
Homology
Paralogs
FAM98A has two paralogs: FAM98B and FAM98C. FAM98A is longest of the three paralogous protein products with 518 amino acids. It is more similar to FAM98B, whose glycine-rich C terminus is much shorter than FAM98A. FAM98C less similar than FAM98B to FAM98A, all but lacking in a C terminus after DUF2465, as well as containing more differences in the amino acid sequence within the DUF2465. All three protein products have been shown experimentally to associate non-specifically with RNA: FAM98A binds to mRNA and FAM98B is incorporated into a tRNA-splicing complex.[5]
Orthologs
Orthologs for FAM98A have been found in vertebrates. In insects and molluscs, there are predicted proteins for a FAM98A gene. Because there are three paralogs of FAM98 in humans, there is a common ancestor of these genes. A strict ortholog, a gene that is orthologous to FAM98A and not the entire FAM98 family, is less clear. FAM98A has not yet been thoroughly studied, compounded with the fact that many genomes are yet to be recorded, makes it more difficult to determine if the predicted FAM98A gene in mosquitoes is a strict ortholog (the split of FAM98 into FAM98A,B,C occurred before the species diverged) or if it is a homolog ("FAM98A" in mosquitoes is the ancestral FAM98 gene).
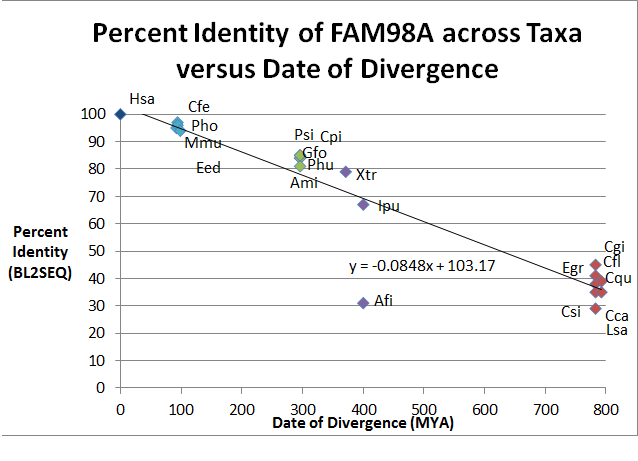
A graph of the data at the left relating the percent identity of the protein sequence between animals and humans.
Genes homologous to FAM98A are predicted to occur in many taxa within Animalia, but there are other taxa outside of Animalia that may have homologous FAM98 genes in their genomes. Eukaryotes such as the opisthokonts Monosiga brevicollis (XP_00174505.1) and Capraspora owczarzaki (XP_004346371.1), and even the protist Chlorella variabilis (XP_005845167.1), a green alga, may contain FAM98 in their genomes.[20]
Homologous Domains
The homologous domain in FAM98A is the DUF2465 (Domain of Unknown Function 2465) domain. The function of this domain, like the gene itself, is largely unknown, though it has been reported that it preferentially binds to RNA, targeting mRNA in FAM98A and tRNA in FAM98B.[5]
Expression
Promoter
The promoter (GXP_90934) assigned to the human FAM98A transcript (GXT_24436545)[21] is 915 bp long, and it overlaps with the transcript to include 243 bp of mRNA transcript. Nuclear respiratory factor 1 (NRF1) is a transcription factor that had seven sites predicted to bind on the promoter, four of which had a Matrix similarity - optimum score of greater than or equal to 0.085 and the two highest scoring transcription factors predicted were NRF1 with scores of 0.204 and 0.199.[22]
Expression
In a GEO large-scale human transcriptome, FAM98A was ubiquitously expressed, though not uniformly expressed. Cell types that were most highly expressed were many parts of the brain (cortex, amygdala, thalamus, corpus callosum, and pituitary gland), the testis, uterus, and smooth muscle.[23] According to Aceview, FAM98A is expressed at 3.9 times the expression of the average gene. Eleven transcripts have been identified by AceView, five of which were "good", complete (both N and C termini fully translated) proteins. From the transcripts, there are apparently two main parts of FAM98A: the first four exons and the second four exons, and these parts correspond roughly to the tertiary structure of the protein - the N-terminal alpha-helices to exons 1-4, and the long alpha-helical arm and C terminus coils to exons 5-8.[24]
Function and Biochemistry
The function of FAM98A has not been experimentally determined, though it has been shown to bind its DUF2465 with mRNA.[5] Kiraga et al. have noted that basic proteins bind with nucleic acids.[25] In fact, FAM98A (and it orthologs) have an unmodified isoelectric point of approximately 9.[26]
Known Interactions
FAM98A has been experimentally shown to interact with UBC, DDX1, C14orf166, and SUMO3, and it is coexpressed with DDX1, C14orf166, and RBM25.[27] These latter three proteins interact with mRNA, as FAM98A is also predicted to do. DDX1 is a putative ATP-dependent RNA helicase in a spliceosome, likely releasing the RNA from the splicing complex.[28] C14orf166 is a polymerase II binding factor,[29] and RBM25 regulates alternative splicing.[30] All of these interactions suggest that FAM98A is a nuclear protein. FAM98A also interacts with SUMO3, which sumoylates lysines in the protein to facilitate transport across the nuclear membrane between the nucleus and cytosol.[13] FAM98A also binds nonspecific mRNA indicating a potential mRNA shuttle out of the nucleus to the ribosomes.[5]
Clinical Significance
In a study that looked at differences in expression levels of certain genes (including FAM98A) in both young and old men with high or low protein diets, the expression levels were measured as a ratio of low/high protein diets in each group of men (young and old). FAM98A had increased expression in low protein diets in both young and old men, 1.01 and 1.20, respectively. Only one other gene in the study had the same trend of increased expression in lower protein diets in both groups: THOC4.[31] THOC4, THO Complex 4 or Aly/REF export factor, dimerizes to form a larger complex and chaperones spliced mRNA, assisting with processing and export of the mRNA.[32] The paper mentions that up-regulation of mRNA in older individuals is associated with RNA binding/splicing, signaling proteins, and protein degradation; in fact, the older group has the higher expression of FAM98A in low protein diets than the younger men.[31]
Disease Association
Research on a population in Taiwan has found an association between young onset hypertension and two SNPs upstream of four genes at the locus 2p22.3. One of these four genes was FAM98A, though more research must be done to verify that it was FAM98A that was the gene responsible for the hypertension.[33] Indeed, FAM98A is expressed moderately high (roughly the 75th percentile) in smooth muscle and cardiac myocytes.[23]
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.