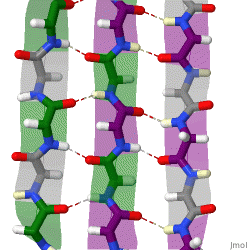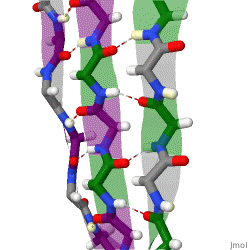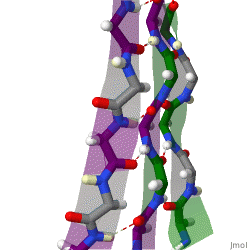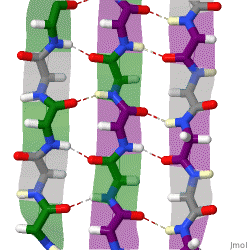
The beta sheet, (β-sheet) is a common motif of the regular protein secondary structure. Beta sheets consist of beta strands (β-strands) connected laterally by at least two or three backbone hydrogen bonds, forming a generally twisted, pleated sheet. A β-strand is a stretch of polypeptide chain typically 3 to 10 amino acids long with backbone in an extended conformation. The supramolecular association of β-sheets has been implicated in the formation of the fibrils and protein aggregates observed in amyloidosis, Alzheimer's disease and other proteinopathies.
In biology, a sequence motif is a nucleotide or amino-acid sequence pattern that is widespread and usually assumed to be related to biological function of the macromolecule. For example, an N-glycosylation site motif can be defined as Asn, followed by anything but Pro, followed by either Ser or Thr, followed by anything but Pro residue.

Histone acetyltransferases (HATs) are enzymes that acetylate conserved lysine amino acids on histone proteins by transferring an acetyl group from acetyl-CoA to form ε-N-acetyllysine. DNA is wrapped around histones, and, by transferring an acetyl group to the histones, genes can be turned on and off. In general, histone acetylation increases gene expression.

The Rossmann fold is a tertiary fold found in proteins that bind nucleotides, such as enzyme cofactors FAD, NAD+, and NADP+. This fold is composed of alternating beta strands and alpha helical segments where the beta strands are hydrogen bonded to each other forming an extended beta sheet and the alpha helices surround both faces of the sheet to produce a three-layered sandwich. The classical Rossmann fold contains six beta strands whereas Rossmann-like folds, sometimes referred to as Rossmannoid folds, contain only five strands. The initial beta-alpha-beta (bab) fold is the most conserved segment of the Rossmann fold. The motif is named after Michael Rossmann who first noticed this structural motif in the enzyme lactate dehydrogenase in 1970 and who later observed that this was a frequently occurring motif in nucleotide binding proteins.

Helix-turn-helix is a DNA-binding protein (DBP). The helix-turn-helix (HTH) is a major structural motif capable of binding DNA. Each monomer incorporates two α helices, joined by a short strand of amino acids, that bind to the major groove of DNA. The HTH motif occurs in many proteins that regulate gene expression. It should not be confused with the helix–loop–helix motif.
In molecular biology, a CCAAT box is a distinct pattern of nucleotides with GGCCAATCT consensus sequence that occur upstream by 60–100 bases to the initial transcription site. The CAAT box signals the binding site for the RNA transcription factor, and is typically accompanied by a conserved consensus sequence. It is an invariant DNA sequence at about minus 70 base pairs from the origin of transcription in many eukaryotic promoters. Genes that have this element seem to require it for the gene to be transcribed in sufficient quantities. It is frequently absent from genes that encode proteins used in virtually all cells. This box along with the GC box is known for binding general transcription factors. Both of these consensus sequences belong to the regulatory promoter. Full gene expression occurs when transcription activator proteins bind to each module within the regulatory promoter. Protein specific binding is required for the CCAAT box activation. These proteins are known as CCAAT box binding proteins/CCAAT box binding factors.
A DNA-binding domain (DBD) is an independently folded protein domain that contains at least one structural motif that recognizes double- or single-stranded DNA. A DBD can recognize a specific DNA sequence or have a general affinity to DNA. Some DNA-binding domains may also include nucleic acids in their folded structure.

In structural biology, a beta-propeller (β-propeller) is a type of all-β protein architecture characterized by 4 to 8 highly symmetrical blade-shaped beta sheets arranged toroidally around a central axis. Together the beta-sheets form a funnel-like active site.

The beta hairpin is a simple protein structural motif involving two beta strands that look like a hairpin. The motif consists of two strands that are adjacent in primary structure, oriented in an antiparallel direction, and linked by a short loop of two to five amino acids. Beta hairpins can occur in isolation or as part of a series of hydrogen bonded strands that collectively comprise a beta sheet.
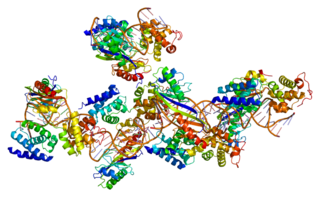
Transcription factor II B (TFIIB) is a general transcription factor that is involved in the formation of the RNA polymerase II preinitiation complex (PIC) and aids in stimulating transcription initiation. TFIIB is localised to the nucleus and provides a platform for PIC formation by binding and stabilising the DNA-TBP complex and by recruiting RNA polymerase II and other transcription factors. It is encoded by the TFIIB gene, and is homologous to archaeal transcription factor B and analogous to bacterial sigma factors.

ADP-ribosylation is the addition of one or more ADP-ribose moieties to a protein. It is a reversible post-translational modification that is involved in many cellular processes, including cell signaling, DNA repair, gene regulation and apoptosis. Improper ADP-ribosylation has been implicated in some forms of cancer. It is also the basis for the toxicity of bacterial compounds such as cholera toxin, diphtheria toxin, and others.

Chorion-specific transcription factor GCMa is a protein that, in humans, is encoded by the GCM1 gene.
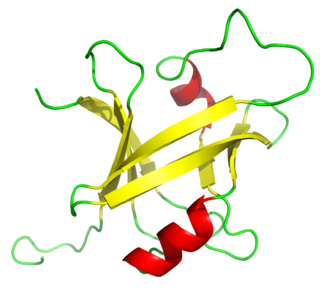
The B3 DNA binding domain (DBD) is a highly conserved domain found exclusively in transcription factors combined with other domains. It consists of 100-120 residues, includes seven beta strands and two alpha helices that form a DNA-binding pseudobarrel protein fold ; it interacts with the major groove of DNA.

In molecular biology, a Tudor domain is a conserved protein structural domain originally identified in the Tudor protein encoded in Drosophila. The Tudor gene was found in a Drosophila screen for maternal factors that regulate embryonic development or fertility. Mutations here are lethal for offspring, inspiring the name Tudor, as a reference to the Tudor King Henry VIII and the several miscarriages experienced by his wives.
The Walker A and Walker B motifs are protein sequence motifs, known to have highly conserved three-dimensional structures. These were first reported in ATP-binding proteins by Walker and co-workers in 1982.
The RNA-binding Proteins Database (RBPDB) is a biological database of RNA-binding protein specificities that includes experimental observations of RNA-binding sites. The experimental results included are both in vitro and in vivo from primary literature. It includes four metazoan species, which are Homo sapiens, Mus musculus, Drosophila melanogaster, and Caenorhabditis elegans. RNA-binding domains included in this database are RNA recognition motif, K homology, CCCH zinc finger, and more domains. As of 2021, the latest RBPDB release includes 1,171 RNA-binding proteins.

The SQUAMOSA promoter binding protein-like family of transcription factors are defined by a plant-specific DNA-binding domain. The founding member of the family was identified based on its specific in vitro binding to the promoter of the snapdragon SQUAMOSA gene. SBP proteins are thought to be transcriptional activators.

The Methyl-CpG-binding domain (MBD) in molecular biology binds to DNA that contains one or more symmetrically methylated CpGs. MBD has negligible non-specific affinity for unmethylated DNA. In vitro foot-printing with the chromosomal protein MeCP2 showed that the MBD could protect a 12 nucleotide region surrounding a methyl CpG pair.
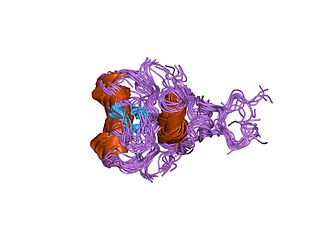
In molecular biology, GATA zinc fingers are zinc-containing domains found in a number of transcription factors. Some members of this class of zinc fingers specifically bind the DNA sequence (A/T)GATA(A/G) in the regulatory regions of genes., giving rise to the name of the domain. In these domains, a single zinc ion is coordinated by 4 cysteine residues. NMR studies have shown the core of the Znf to comprise 2 irregular anti-parallel beta-sheets and an alpha-helix, followed by a long loop to the C-terminal end of the finger. The N-terminal part, which includes the helix, is similar in structure, but not sequence, to the N-terminal zinc module of the glucocorticoid receptor DNA-binding domain. The helix and the loop connecting the 2 beta-sheets interact with the major groove of the DNA, while the C-terminal tail wraps around into the minor groove. Interactions between the Znf and DNA are mainly hydrophobic, explaining the preponderance of thymines in the binding site; a large number of interactions with the phosphate backbone have also been observed. Two GATA zinc fingers are found in GATA-family transcription factors. However, there are several proteins that only contain a single copy of the domain. It is also worth noting that many GATA-type Znfs have not been experimentally demonstrated to be DNA-binding domains. Furthermore, several GATA-type Znfs have been demonstrated to act as protein-recognition domains. For example, the N-terminal Znf of GATA1 binds specifically to a zinc finger from the transcriptional coregulator FOG1 (ZFPM1).

The WRKY domain is found in the WRKY transcription factor family, a class of transcription factors. The WRKY domain is found almost exclusively in plants although WRKY genes appear present in some diplomonads, social amoebae and other amoebozoa, and fungi incertae sedis. They appear absent in other non-plant species. WRKY transcription factors have been a significant area of plant research for the past 20 years. The WRKY DNA-binding domain recognizes the W-box (T)TGAC(C/T) cis-regulatory element.
