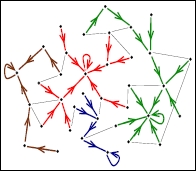
In network science, a gradient network is a directed subnetwork of an undirected "substrate" network where each node has an associated scalar potential and one out-link that points to the node with the smallest (or largest) potential in its neighborhood, defined as the union of itself and its neighbors on the substrate network.[2]
Transport takes place on a fixed network called the substrate graph. It has N nodes, and the set of edges . Given a node i, we can define its set of neighbors in G by Si(1) = {j ∈ V | (i,j)∈ E}.
Let us also consider a scalar field, h = {h0, .., hN−1} defined on the set of nodes V, so that every node i has a scalar value hi associated to it.
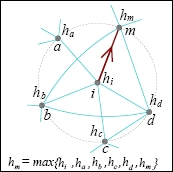
Gradient ∇hi on a network: ∇hi(i, μ(i)) i.e. the directed edge from i to μ(i), where μ(i) ∈ Si(1) ∪ {i}, and hμ has the maximum value in .
Gradient network: ∇ ∇ where F is the set of gradient edges on G.
In general, the scalar field depends on time, due to the flow, external sources and sinks on the network. Therefore, the gradient network ∇ will be dynamic.[3]
Motivation and history
The concept of a gradient network was first introduced by Toroczkai and Bassler (2004).[4][5]
Generally, real-world networks (such as citation graphs, the Internet, cellular metabolic networks, the worldwide airport network), which often evolve to transport entities such as information, cars, power, water, forces, and so on, are not globally designed; instead, they evolve and grow through local changes. For example, if a router on the Internet is frequently congested and packets are lost or delayed due to that, it will be replaced by several interconnected new routers.[1]
Moreover, this flow is often generated or influenced by local gradients of a scalar. For example: electric current is driven by a gradient of electric potential. In information networks, properties of nodes will generate a bias in the way of information is transmitted from a node to its neighbors. This idea motivated the approach to study the flow efficiency of a network by using gradient networks, when the flow is driven by gradients of a scalar field distributed on the network.[1][3]
The gradient at node i is a directed edge pointing towards the largest increase of the scalar potential in the node's neighborhood.
In-degree distribution of gradient networks
In a gradient network, the in-degree of a node i, ki(in) is the number of gradient edges pointing into i, and the in-degree distribution is .
The degree distributions of the gradient network and the substrate(BA Model).
When the substrate G is a random graph and each pair of nodes is connected with probability P (i.e. an Erdős–Rényi random graph), the scalars hi are i.i.d. (independent identically distributed) the exact expression for R(l) is given by
In the limit and , the degree distribution becomes the power law
This shows in this limit, the gradient network of random network is scale-free.[3]
Furthermore, if the substrate network G is scale-free, like in the Barabási–Albert model, then the gradient network also follow the power-law with the same exponent as those of G.[1]
The congestion on networks
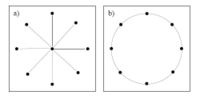
The fact that the topology of the substrate network influence the level of network congestion can be illustrated by a simple example: if the network has a star-like structure, then at the central node, the flow would become congested because the central node should handle all the flow from other nodes. However, if the network has a ring-like structure, since every node takes the same role, there is no flow congestion.
Illustrating the influence of structure on flows.
Under assumption that the flow is generated by gradients in the network, flow efficiency on networks can be characterized through the jamming factor (or congestion factor), defined as follows:
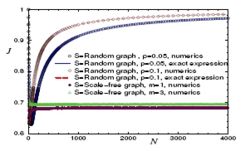
where Nreceive is the number of nodes that receive gradient flow and Nsend is the number of nodes that send gradient flow. The value of J is between 0 and 1; means no congestion, and corresponds to maximal congestion. In the limit , for an Erdős–Rényi random graph, the congestion factor becomes
This result shows that random networks are maximally congested in that limit. On the contrary, for a scale-free network, J is a constant for any N, which means that scale-free networks are not prone to maximal jamming.[6]
Fig.7. The congestion coefficient for random graphs and scale-free networks.
Approaches to control congestion
One problem in communication networks is understanding how to control congestion and maintain normal and efficient network function.[7]
Zonghua Liu et al. (2006) showed that congestion is more likely to occur at the nodes with high degrees in networks, and an efficient approach of selectively enhancing the message-process capability of a small fraction (e.g. 3%) of nodes is shown to perform just as well as enhancing the capability of all nodes.[7]
Ana L Pastore y Piontti et al. (2008) showed that relaxational dynamics[clarification needed] can reduce network congestion.[8]
Pan et al. (2011) studied jamming properties in a scheme where edges are given weights of a power of the scalar difference between node potentials.[9][clarification needed]
Niu and Pan (2016) showed that congestion can be reduced by introducing a correlation between the gradient field and the local network topology.[10][clarification needed]
<n(k)> is the average packet number as a function of degree, packet-processing capabilities: 0 (circles), 0.05 (squares), 0.1 (stars).The comparison between the efficient approach (circles) with the capability of top 3% degree nodes enhanced and the normal approach (stars) with the capability of all nodes enhanced. (a) packet-processing capability equals to 0.05, (b) packet-processing capability equals to 0.1. <n(k)> is the average packet number as a function of degree.
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.