
A nucleosome is the basic structural unit of DNA packaging in eukaryotes. The structure of a nucleosome consists of a segment of DNA wound around eight histone proteins and resembles thread wrapped around a spool. The nucleosome is the fundamental subunit of chromatin. Each nucleosome is composed of a little less than two turns of DNA wrapped around a set of eight proteins called histones, which are known as a histone octamer. Each histone octamer is composed of two copies each of the histone proteins H2A, H2B, H3, and H4.

Helix-turn-helix is a DNA-binding protein (DBP). The helix-turn-helix (HTH) is a major structural motif capable of binding DNA. Each monomer incorporates two α helices, joined by a short strand of amino acids, that bind to the major groove of DNA. The HTH motif occurs in many proteins that regulate gene expression. It should not be confused with the helix–loop–helix motif.
A supersecondary structure is a compact three-dimensional protein structure of several adjacent elements of a secondary structure that is smaller than a protein domain or a subunit. Supersecondary structures can act as nucleations in the process of protein folding.

A leucine zipper is a common three-dimensional structural motif in proteins. They were first described by Landschulz and collaborators in 1988 when they found that an enhancer binding protein had a very characteristic 30-amino acid segment and the display of these amino acid sequences on an idealized alpha helix revealed a periodic repetition of leucine residues at every seventh position over a distance covering eight helical turns. The polypeptide segments containing these periodic arrays of leucine residues were proposed to exist in an alpha-helical conformation and the leucine side chains from one alpha helix interdigitate with those from the alpha helix of a second polypeptide, facilitating dimerization.
A DNA-binding domain (DBD) is an independently folded protein domain that contains at least one structural motif that recognizes double- or single-stranded DNA. A DBD can recognize a specific DNA sequence or have a general affinity to DNA. Some DNA-binding domains may also include nucleic acids in their folded structure.
RSC is a member of the ATP-dependent chromatin remodeler family. The activity of the RSC complex allows for chromatin to be remodeled by altering the structure of the nucleosome.

In molecular biology, SWI/SNF, is a subfamily of ATP-dependent chromatin remodeling complexes, which is found in eukaryotes. In other words, it is a group of proteins that associate to remodel the way DNA is packaged. This complex is composed of several proteins – products of the SWI and SNF genes, as well as other polypeptides. It possesses a DNA-stimulated ATPase activity that can destabilize histone-DNA interactions in reconstituted nucleosomes in an ATP-dependent manner, though the exact nature of this structural change is unknown. The SWI/SNF subfamily provides crucial nucleosome rearrangement, which is seen as ejection and/or sliding. The movement of nucleosomes provides easier access to the chromatin, allowing genes to be activated or repressed.

Histone H2A is one of the five main histone proteins involved in the structure of chromatin in eukaryotic cells.
Chromatin remodeling is the dynamic modification of chromatin architecture to allow access of condensed genomic DNA to the regulatory transcription machinery proteins, and thereby control gene expression. Such remodeling is principally carried out by 1) covalent histone modifications by specific enzymes, e.g., histone acetyltransferases (HATs), deacetylases, methyltransferases, and kinases, and 2) ATP-dependent chromatin remodeling complexes which either move, eject or restructure nucleosomes. Besides actively regulating gene expression, dynamic remodeling of chromatin imparts an epigenetic regulatory role in several key biological processes, egg cells DNA replication and repair; apoptosis; chromosome segregation as well as development and pluripotency. Aberrations in chromatin remodeling proteins are found to be associated with human diseases, including cancer. Targeting chromatin remodeling pathways is currently evolving as a major therapeutic strategy in the treatment of several cancers.
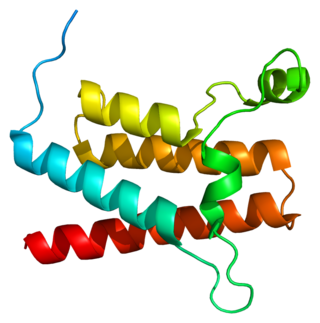
Transcription activator BRG1 also known as ATP-dependent chromatin remodeler SMARCA4 is a protein that in humans is encoded by the SMARCA4 gene.

Probable global transcription activator SNF2L2 is a protein that in humans is encoded by the SMARCA2 gene.
SWI/SNF-related matrix-associated actin-dependent regulator of chromatin subfamily A member 5 is a protein that in humans is encoded by the SMARCA5 gene.

AT-rich interactive domain-containing protein 1A is a protein that in humans is encoded by the ARID1A gene.

SWI/SNF-related matrix-associated actin-dependent regulator of chromatin subfamily E member 1 is a protein that in humans is encoded by the SMARCE1 gene.

The Chromodomain-Helicase DNA-binding 1 is a protein that, in humans, is encoded by the CHD1 gene. CHD1 is a chromatin remodeling protein that is widely conserved across many eukaryotic organisms, from yeast to humans. CHD1 is named for three of its protein domains: two tandem chromodomains, its ATPase catalytic domain, and its DNA-binding domain.
ISWI is one of the five major DNA chromatin remodeling complex types, or subfamilies, found in most eukaryotic organisms. ISWI remodeling complexes place nucleosomes along segments of DNA at regular intervals. The placement of nucleosomes by ISWI protein complexes typically results in the silencing of the DNA because the nucleosome placement prevents transcription of the DNA. ISWI, like the closely related SWI/SNF subfamily, is an ATP-dependent chromatin remodeler. However, the chromatin remodeling activities of ISWI and SWI/SNF are distinct and mediate the binding of non-overlapping sets of DNA transcription factors.
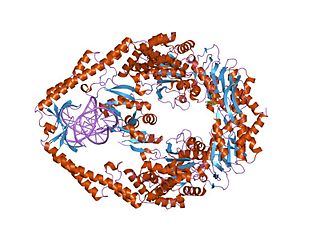
MutS is a mismatch DNA repair protein, originally described in Escherichia coli.

In molecular biology, the ARID domain ) is a protein domain that binds to DNA. ARID domain-containing proteins are found in fungi, plants and invertebrate and vertebrate metazoans. ARID-encoding genes are involved in a variety of biological processes including embryonic development, cell lineage gene regulation and cell cycle control. Although the specific roles of this domain and of ARID-containing proteins in transcriptional regulation are yet to be elucidated, they include both positive and negative transcriptional regulation and a likely involvement in the modification of chromatin structure. The basic structure of the ARID domain appears to be a series of six alpha-helices separated by beta-strands, loops, or turns, but the structured region may extend to an additional helix at either or both ends of the basic six. Based on primary sequence homology, they can be partitioned into three structural classes: Minimal ARID proteins that consist of a core domain formed by six alpha helices; ARID proteins that supplement the core domain with an N-terminal alpha-helix; and Extended-ARID proteins, which contain the core domain and additional alpha-helices at their N- and C-termini.
Nucleosome Remodeling Factor (NURF) is an ATP-dependent chromatin remodeling complex first discovered in Drosophila melanogaster that catalyzes nucleosome sliding in order to regulate gene transcription. It contains an ISWI ATPase, making it part of the ISWI family of chromatin remodeling complexes. NURF is highly conserved among eukaryotes and is involved in transcriptional regulation of developmental genes.
Robert E. Kingston is an American biochemist who studies the functional and regulatory role nucleosomes play in gene expression, specifically during early development. After receiving his PhD (1981) and completing post-doctoral research, Kingston became an assistant professor at Massachusetts General Hospital (1985), where he started a research laboratory focused on understanding chromatin's structure with regards to transcriptional regulation. As a Harvard graduate himself, Kingston has served his alma mater through his leadership.
