In physics, the cross section is a measure of the probability that a specific process will take place when some kind of radiant excitation intersects a localized phenomenon. For example, the Rutherford cross-section is a measure of probability that an alpha particle will be deflected by a given angle during an interaction with an atomic nucleus. Cross section is typically denoted σ (sigma) and is expressed in units of area, more specifically in barns. In a way, it can be thought of as the size of the object that the excitation must hit in order for the process to occur, but more exactly, it is a parameter of a stochastic process.

An electric field is the physical field that surrounds electrically charged particles and exerts force on all other charged particles in the field, either attracting or repelling them. It also refers to the physical field for a system of charged particles. Electric fields originate from electric charges and time-varying electric currents. Electric fields and magnetic fields are both manifestations of the electromagnetic field, one of the four fundamental interactions of nature.
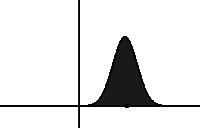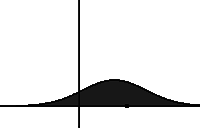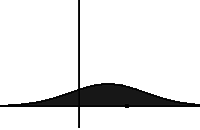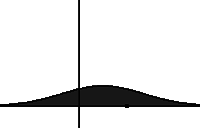
In statistical mechanics and information theory, the Fokker–Planck equation is a partial differential equation that describes the time evolution of the probability density function of the velocity of a particle under the influence of drag forces and random forces, as in Brownian motion. The equation can be generalized to other observables as well. The Fokker-Planck equation has multiple applications in information theory, graph theory, data science, finance, economics etc.

In mathematics, the unitary group of degree n, denoted U(n), is the group of n × n unitary matrices, with the group operation of matrix multiplication. The unitary group is a subgroup of the general linear group GL(n, C). Hyperorthogonal group is an archaic name for the unitary group, especially over finite fields. For the group of unitary matrices with determinant 1, see Special unitary group.
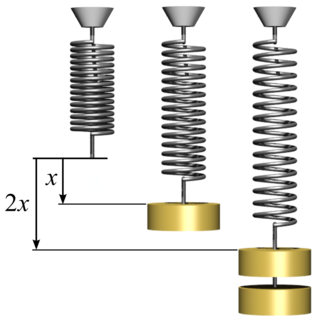
In physics, Hooke's law is an empirical law which states that the force needed to extend or compress a spring by some distance scales linearly with respect to that distance—that is, Fs = kx, where k is a constant factor characteristic of the spring, and x is small compared to the total possible deformation of the spring. The law is named after 17th-century British physicist Robert Hooke. He first stated the law in 1676 as a Latin anagram. He published the solution of his anagram in 1678 as: ut tensio, sic vis. Hooke states in the 1678 work that he was aware of the law since 1660.
In mathematics, the idea of a free object is one of the basic concepts of abstract algebra. Informally, a free object over a set A can be thought of as being a "generic" algebraic structure over A: the only equations that hold between elements of the free object are those that follow from the defining axioms of the algebraic structure. Examples include free groups, tensor algebras, or free lattices.

Thomson scattering is the elastic scattering of electromagnetic radiation by a free charged particle, as described by classical electromagnetism. It is the low-energy limit of Compton scattering: the particle's kinetic energy and photon frequency do not change as a result of the scattering. This limit is valid as long as the photon energy is much smaller than the mass energy of the particle: , or equivalently, if the wavelength of the light is much greater than the Compton wavelength of the particle.

In electromagnetism, charge density is the amount of electric charge per unit length, surface area, or volume. Volume charge density is the quantity of charge per unit volume, measured in the SI system in coulombs per cubic meter (C⋅m−3), at any point in a volume. Surface charge density (σ) is the quantity of charge per unit area, measured in coulombs per square meter (C⋅m−2), at any point on a surface charge distribution on a two dimensional surface. Linear charge density (λ) is the quantity of charge per unit length, measured in coulombs per meter (C⋅m−1), at any point on a line charge distribution. Charge density can be either positive or negative, since electric charge can be either positive or negative.
The J-integral represents a way to calculate the strain energy release rate, or work (energy) per unit fracture surface area, in a material. The theoretical concept of J-integral was developed in 1967 by G. P. Cherepanov and independently in 1968 by James R. Rice, who showed that an energetic contour path integral was independent of the path around a crack.
The Newman–Penrose (NP) formalism is a set of notation developed by Ezra T. Newman and Roger Penrose for general relativity (GR). Their notation is an effort to treat general relativity in terms of spinor notation, which introduces complex forms of the usual variables used in GR. The NP formalism is itself a special case of the tetrad formalism, where the tensors of the theory are projected onto a complete vector basis at each point in spacetime. Usually this vector basis is chosen to reflect some symmetry of the spacetime, leading to simplified expressions for physical observables. In the case of the NP formalism, the vector basis chosen is a null tetrad: a set of four null vectors—two real, and a complex-conjugate pair. The two real members often asymptotically point radially inward and radially outward, and the formalism is well adapted to treatment of the propagation of radiation in curved spacetime. The Weyl scalars, derived from the Weyl tensor, are often used. In particular, it can be shown that one of these scalars— in the appropriate frame—encodes the outgoing gravitational radiation of an asymptotically flat system.
In computer science, a trace is a set of strings, wherein certain letters in the string are allowed to commute, but others are not. It generalizes the concept of a string, by not forcing the letters to always be in a fixed order, but allowing certain reshufflings to take place. Traces were introduced by Pierre Cartier and Dominique Foata in 1969 to give a combinatorial proof of MacMahon's master theorem. Traces are used in theories of concurrent computation, where commuting letters stand for portions of a job that can execute independently of one another, while non-commuting letters stand for locks, synchronization points or thread joins.
In mathematics and theoretical computer science, a semiautomaton is a deterministic finite automaton having inputs but no output. It consists of a set Q of states, a set Σ called the input alphabet, and a function T: Q × Σ → Q called the transition function.
In computer science, in the area of formal language theory, frequent use is made of a variety of string functions; however, the notation used is different from that used for computer programming, and some commonly used functions in the theoretical realm are rarely used when programming. This article defines some of these basic terms.
In mathematics, the multiple zeta functions are generalizations of the Riemann zeta function, defined by
When an electromagnetic wave travels through a medium in which it gets attenuated, it undergoes exponential decay as described by the Beer–Lambert law. However, there are many possible ways to characterize the wave and how quickly it is attenuated. This article describes the mathematical relationships among:
In the mathematical theory of artificial neural networks, universal approximation theorems are results that establish the density of an algorithmically generated class of functions within a given function space of interest. Typically, these results concern the approximation capabilities of the feedforward architecture on the space of continuous functions between two Euclidean spaces, and the approximation is with respect to the compact convergence topology.
Uniform convergence in probability is a form of convergence in probability in statistical asymptotic theory and probability theory. It means that, under certain conditions, the empirical frequencies of all events in a certain event-family converge to their theoretical probabilities. Uniform convergence in probability has applications to statistics as well as machine learning as part of statistical learning theory.
Stochastic portfolio theory (SPT) is a mathematical theory for analyzing stock market structure and portfolio behavior introduced by E. Robert Fernholz in 2002. It is descriptive as opposed to normative, and is consistent with the observed behavior of actual markets. Normative assumptions, which serve as a basis for earlier theories like modern portfolio theory (MPT) and the capital asset pricing model (CAPM), are absent from SPT.
In mathematics, the injective tensor product of two topological vector spaces (TVSs) was introduced by Alexander Grothendieck and was used by him to define nuclear spaces. An injective tensor product is in general not necessarily complete, so its completion is called the completed injective tensor products. Injective tensor products have applications outside of nuclear spaces. In particular, as described below, up to TVS-isomorphism, many TVSs that are defined for real or complex valued functions, for instance, the Schwartz space or the space of continuously differentiable functions, can be immediately extended to functions valued in a Hausdorff locally convex TVS without any need to extend definitions from real/complex-valued functions to -valued functions.
In statistics, expected mean squares (EMS) are the expected values of certain statistics arising in partitions of sums of squares in the analysis of variance (ANOVA). They can be used for ascertaining which statistic should appear in the denominator in an F-test for testing a null hypothesis that a particular effect is absent.
















































