Information theory is the mathematical study of the quantification, storage, and communication of information. The field was originally established by the works of Harry Nyquist and Ralph Hartley, in the 1920s, and Claude Shannon in the 1940s. The field is at the intersection of probability theory, statistics, computer science, statistical mechanics, information engineering, and electrical engineering.

In information theory, the entropy of a random variable is the average level of "information", "surprise", or "uncertainty" inherent to the variable's possible outcomes. Given a discrete random variable , which takes values in the alphabet and is distributed according to :

Independence is a fundamental notion in probability theory, as in statistics and the theory of stochastic processes. Two events are independent, statistically independent, or stochastically independent if, informally speaking, the occurrence of one does not affect the probability of occurrence of the other or, equivalently, does not affect the odds. Similarly, two random variables are independent if the realization of one does not affect the probability distribution of the other.
Rate–distortion theory is a major branch of information theory which provides the theoretical foundations for lossy data compression; it addresses the problem of determining the minimal number of bits per symbol, as measured by the rate R, that should be communicated over a channel, so that the source can be approximately reconstructed at the receiver without exceeding an expected distortion D.

In probability theory and information theory, the mutual information (MI) of two random variables is a measure of the mutual dependence between the two variables. More specifically, it quantifies the "amount of information" obtained about one random variable by observing the other random variable. The concept of mutual information is intimately linked to that of entropy of a random variable, a fundamental notion in information theory that quantifies the expected "amount of information" held in a random variable.
In information theory, the conditional entropy quantifies the amount of information needed to describe the outcome of a random variable given that the value of another random variable is known. Here, information is measured in shannons, nats, or hartleys. The entropy of conditioned on is written as .
In information theory, joint entropy is a measure of the uncertainty associated with a set of variables.
The joint quantum entropy generalizes the classical joint entropy to the context of quantum information theory. Intuitively, given two quantum states and , represented as density operators that are subparts of a quantum system, the joint quantum entropy is a measure of the total uncertainty or entropy of the joint system. It is written or , depending on the notation being used for the von Neumann entropy. Like other entropies, the joint quantum entropy is measured in bits, i.e. the logarithm is taken in base 2.
In information theory, redundancy measures the fractional difference between the entropy H(X) of an ensemble X, and its maximum possible value . Informally, it is the amount of wasted "space" used to transmit certain data. Data compression is a way to reduce or eliminate unwanted redundancy, while forward error correction is a way of adding desired redundancy for purposes of error detection and correction when communicating over a noisy channel of limited capacity.
Differential entropy is a concept in information theory that began as an attempt by Claude Shannon to extend the idea of (Shannon) entropy, a measure of average surprisal of a random variable, to continuous probability distributions. Unfortunately, Shannon did not derive this formula, and rather just assumed it was the correct continuous analogue of discrete entropy, but it is not. The actual continuous version of discrete entropy is the limiting density of discrete points (LDDP). Differential entropy is commonly encountered in the literature, but it is a limiting case of the LDDP, and one that loses its fundamental association with discrete entropy.
This article discusses how information theory is related to measure theory.
The mathematical theory of information is based on probability theory and statistics, and measures information with several quantities of information. The choice of logarithmic base in the following formulae determines the unit of information entropy that is used. The most common unit of information is the bit, or more correctly the shannon, based on the binary logarithm. Although "bit" is more frequently used in place of "shannon", its name is not distinguished from the bit as used in data-processing to refer to a binary value or stream regardless of its entropy Other units include the nat, based on the natural logarithm, and the hartley, based on the base 10 or common logarithm.
In probability theory and in particular in information theory, total correlation is one of several generalizations of the mutual information. It is also known as the multivariate constraint or multiinformation. It quantifies the redundancy or dependency among a set of n random variables.
The interaction information is a generalization of the mutual information for more than two variables.
The entropic vector or entropic function is a concept arising in information theory. It represents the possible values of Shannon's information entropy that subsets of one set of random variables may take. Understanding which vectors are entropic is a way to represent all possible inequalities between entropies of various subsets. For example, for any two random variables , their joint entropy is at most the sum of the entropies of and of :
Inequalities are very important in the study of information theory. There are a number of different contexts in which these inequalities appear.
In probability theory, particularly information theory, the conditional mutual information is, in its most basic form, the expected value of the mutual information of two random variables given the value of a third.

In probability theory and information theory, the variation of information or shared information distance is a measure of the distance between two clusterings. It is closely related to mutual information; indeed, it is a simple linear expression involving the mutual information. Unlike the mutual information, however, the variation of information is a true metric, in that it obeys the triangle inequality.
In statistics, the uncertainty coefficient, also called proficiency, entropy coefficient or Theil's U, is a measure of nominal association. It was first introduced by Henri Theil and is based on the concept of information entropy.
Transfer entropy is a non-parametric statistic measuring the amount of directed (time-asymmetric) transfer of information between two random processes. Transfer entropy from a process X to another process Y is the amount of uncertainty reduced in future values of Y by knowing the past values of X given past values of Y. More specifically, if and for denote two random processes and the amount of information is measured using Shannon's entropy, the transfer entropy can be written as:
 Venn diagram showing additive and subtractive relationships among various information measures associated with correlated variables X and Y. The area contained by both circles is the joint entropy . The circle on the left (red and violet) is the individual entropy , with the red being the conditional entropy . The circle on the right (blue and violet) is , with the blue being . The violet is the mutual information .
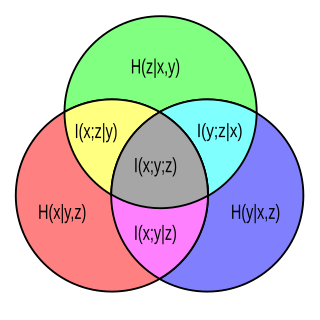
Venn diagram showing additive and subtractive relationships among various information measures associated with correlated variables X and Y. The area contained by both circles is the joint entropy . The circle on the left (red and violet) is the individual entropy , with the red being the conditional entropy . The circle on the right (blue and violet) is , with the blue being . The violet is the mutual information . Venn diagram of information theoretic measures for three variables x, y, and z. Each circle represents an individual entropy: is the lower left circle, the lower right, and is the upper circle. The intersections of any two circles represents the mutual information for the two associated variables (e.g. is yellow and gray). The union of any two circles is the joint entropy for the two associated variables (e.g. is everything but green). The joint entropy of all three variables is the union of all three circles. It is partitioned into 7 pieces, red, blue, and green being the conditional entropies respectively, yellow, magenta and cyan being the conditional mutual informations and respectively, and gray being the interaction information . The interaction information is the only one of all that may be negative.
Venn diagram of information theoretic measures for three variables x, y, and z. Each circle represents an individual entropy: is the lower left circle, the lower right, and is the upper circle. The intersections of any two circles represents the mutual information for the two associated variables (e.g. is yellow and gray). The union of any two circles is the joint entropy for the two associated variables (e.g. is everything but green). The joint entropy of all three variables is the union of all three circles. It is partitioned into 7 pieces, red, blue, and green being the conditional entropies respectively, yellow, magenta and cyan being the conditional mutual informations and respectively, and gray being the interaction information . The interaction information is the only one of all that may be negative.
















