
ISO 216 is an international standard for paper sizes, used around the world except in North America and parts of Latin America. The standard defines the "A", "B" and "C" series of paper sizes, which includes the A4, the most commonly available paper size worldwide. Two supplementary standards, ISO 217 and ISO 269, define related paper sizes; the ISO 269 "C" series is commonly listed alongside the A and B sizes.
A discrete cosine transform (DCT) expresses a finite sequence of data points in terms of a sum of cosine functions oscillating at different frequencies. The DCT, first proposed by Nasir Ahmed in 1972, is a widely used transformation technique in signal processing and data compression. It is used in most digital media, including digital images, digital video, digital audio, digital television, digital radio, and speech coding. DCTs are also important to numerous other applications in science and engineering, such as digital signal processing, telecommunication devices, reducing network bandwidth usage, and spectral methods for the numerical solution of partial differential equations.

Multidimensional scaling (MDS) is a means of visualizing the level of similarity of individual cases of a data set. MDS is used to translate distances between each pair of objects in a set into a configuration of points mapped into an abstract Cartesian space.

Collaborative filtering (CF) is, besides content-based filtering, one of two major techniques used by recommender systems. Collaborative filtering has two senses, a narrow one and a more general one.
In linear algebra, a tridiagonal matrix is a band matrix that has nonzero elements only on the main diagonal, the subdiagonal/lower diagonal, and the supradiagonal/upper diagonal. For example, the following matrix is tridiagonal:
A recommender system (RecSys), or a recommendation system (sometimes replacing system with terms such as platform, engine, or algorithm), is a subclass of information filtering system that provides suggestions for items that are most pertinent to a particular user. Recommender systems are particularly useful when an individual needs to choose an item from a potentially overwhelming number of items that a service may offer.
In statistics and related fields, a similarity measure or similarity function or similarity metric is a real-valued function that quantifies the similarity between two objects. Although no single definition of a similarity exists, usually such measures are in some sense the inverse of distance metrics: they take on large values for similar objects and either zero or a negative value for very dissimilar objects. Though, in more broad terms, a similarity function may also satisfy metric axioms.
In applied mathematics, a DFT matrix is an expression of a discrete Fourier transform (DFT) as a transformation matrix, which can be applied to a signal through matrix multiplication.
The raised-cosine filter is a filter frequently used for pulse-shaping in digital modulation due to its ability to minimise intersymbol interference (ISI). Its name stems from the fact that the non-zero portion of the frequency spectrum of its simplest form is a cosine function, 'raised' up to sit above the (horizontal) axis.
Slope One is a family of algorithms used for collaborative filtering, introduced in a 2005 paper by Daniel Lemire and Anna Maclachlan. Arguably, it is the simplest form of non-trivial item-based collaborative filtering based on ratings. Their simplicity makes it especially easy to implement them efficiently while their accuracy is often on par with more complicated and computationally expensive algorithms. They have also been used as building blocks to improve other algorithms. They are part of major open-source libraries such as Apache Mahout and Easyrec.
Product finders are information systems that help consumers to identify products within a large palette of similar alternative products. Product finders differ in complexity, the more complex among them being a special case of decision support systems. Conventional decision support systems, however, aim at specialized user groups, e.g. marketing managers, whereas product finders focus on consumers.
In data analysis, cosine similarity is a measure of similarity between two non-zero vectors defined in an inner product space. Cosine similarity is the cosine of the angle between the vectors; that is, it is the dot product of the vectors divided by the product of their lengths. It follows that the cosine similarity does not depend on the magnitudes of the vectors, but only on their angle. The cosine similarity always belongs to the interval For example, two proportional vectors have a cosine similarity of 1, two orthogonal vectors have a similarity of 0, and two opposite vectors have a similarity of -1. In some contexts, the component values of the vectors cannot be negative, in which case the cosine similarity is bounded in .
Cold start is a potential problem in computer-based information systems which involves a degree of automated data modelling. Specifically, it concerns the issue that the system cannot draw any inferences for users or items about which it has not yet gathered sufficient information.
SimRank is a general similarity measure, based on a simple and intuitive graph-theoretic model. SimRank is applicable in any domain with object-to-object relationships, that measures similarity of the structural context in which objects occur, based on their relationships with other objects. Effectively, SimRank is a measure that says "two objects are considered to be similar if they are referenced by similar objects." Although SimRank is widely adopted, it may output unreasonable similarity scores which are influenced by different factors, and can be solved in several ways, such as introducing an evidence weight factor, inserting additional terms that are neglected by SimRank or using PageRank-based alternatives.
Vector space model or term vector model is an algebraic model for representing text documents as vectors such that the distance between vectors represents the relevance between the documents. It is used in information filtering, information retrieval, indexing and relevancy rankings. Its first use was in the SMART Information Retrieval System.
Fuzzy retrieval techniques are based on the Extended Boolean model and the Fuzzy set theory. There are two classical fuzzy retrieval models: Mixed Min and Max (MMM) and the Paice model. Both models do not provide a way of evaluating query weights, however this is considered by the P-norms algorithm.
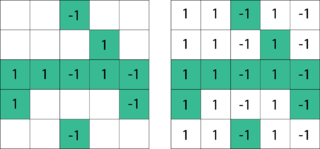
Matrix completion is the task of filling in the missing entries of a partially observed matrix, which is equivalent to performing data imputation in statistics. A wide range of datasets are naturally organized in matrix form. One example is the movie-ratings matrix, as appears in the Netflix problem: Given a ratings matrix in which each entry represents the rating of movie by customer , if customer has watched movie and is otherwise missing, we would like to predict the remaining entries in order to make good recommendations to customers on what to watch next. Another example is the document-term matrix: The frequencies of words used in a collection of documents can be represented as a matrix, where each entry corresponds to the number of times the associated term appears in the indicated document.
Robust collaborative filtering, or attack-resistant collaborative filtering, refers to algorithms or techniques that aim to make collaborative filtering more robust against efforts of manipulation, while hopefully maintaining recommendation quality. In general, these efforts of manipulation usually refer to shilling attacks, also called profile injection attacks. Collaborative filtering predicts a user's rating to items by finding similar users and looking at their ratings, and because it is possible to create nearly indefinite copies of user profiles in an online system, collaborative filtering becomes vulnerable when multiple copies of fake profiles are introduced to the system. There are several different approaches suggested to improve robustness of both model-based and memory-based collaborative filtering. However, robust collaborative filtering techniques are still an active research field, and major applications of them are yet to come.
Location-based recommendation is a recommender system that incorporates location information, such as that from a mobile device, into algorithms to attempt to provide more-relevant recommendations to users. This could include recommendations for restaurants, museums, or other points of interest or events near the user's location.
Matrix factorization is a class of collaborative filtering algorithms used in recommender systems. Matrix factorization algorithms work by decomposing the user-item interaction matrix into the product of two lower dimensionality rectangular matrices. This family of methods became widely known during the Netflix prize challenge due to its effectiveness as reported by Simon Funk in his 2006 blog post, where he shared his findings with the research community. The prediction results can be improved by assigning different regularization weights to the latent factors based on items' popularity and users' activeness.












