
In probability theory and statistics, the multivariate normal distribution, multivariate Gaussian distribution, or joint normal distribution is a generalization of the one-dimensional (univariate) normal distribution to higher dimensions. One definition is that a random vector is said to be k-variate normally distributed if every linear combination of its k components has a univariate normal distribution. Its importance derives mainly from the multivariate central limit theorem. The multivariate normal distribution is often used to describe, at least approximately, any set of (possibly) correlated real-valued random variables each of which clusters around a mean value.

In probability theory and statistics, the Gumbel distribution is used to model the distribution of the maximum of a number of samples of various distributions.
In Riemannian geometry, the sectional curvature is one of the ways to describe the curvature of Riemannian manifolds with dimension greater than 1. The sectional curvature K(σp) depends on a two-dimensional linear subspace σp of the tangent space at a point p of the manifold. It can be defined geometrically as the Gaussian curvature of the surface which has the plane σp as a tangent plane at p, obtained from geodesics which start at p in the directions of σp. The sectional curvature is a real-valued function on the 2-Grassmannian bundle over the manifold.
In probability theory and statistics, the cumulantsκn of a probability distribution are a set of quantities that provide an alternative to the moments of the distribution. Any two probability distributions whose moments are identical will have identical cumulants as well, and vice versa.

In mathematics, theta functions are special functions of several complex variables. They are important in many areas, including the theories of Abelian varieties and moduli spaces, and of quadratic forms. They have also been applied to soliton theory. When generalized to a Grassmann algebra, they also appear in quantum field theory.
The Gram–Charlier A series, and the Edgeworth series are series that approximate a probability distribution in terms of its cumulants. The series are the same; but, the arrangement of terms differ. The key idea of these expansions is to write the characteristic function of the distribution whose probability density function f is to be approximated in terms of the characteristic function of a distribution with known and suitable properties, and to recover f through the inverse Fourier transform.
A continuous-time Markov chain (CTMC) is a continuous stochastic process in which, for each state, the process will change state according to an exponential random variable and then move to a different state as specified by the probabilities of a stochastic matrix. An equivalent formulation describes the process as changing state according to the least value of a set of exponential random variables, one for each possible state it can move to, with the parameters determined by the current state.
Variational Bayesian methods are a family of techniques for approximating intractable integrals arising in Bayesian inference and machine learning. They are typically used in complex statistical models consisting of observed variables as well as unknown parameters and latent variables, with various sorts of relationships among the three types of random variables, as might be described by a graphical model. As typical in Bayesian inference, the parameters and latent variables are grouped together as "unobserved variables". Variational Bayesian methods are primarily used for two purposes:
- To provide an analytical approximation to the posterior probability of the unobserved variables, in order to do statistical inference over these variables.
- To derive a lower bound for the marginal likelihood of the observed data. This is typically used for performing model selection, the general idea being that a higher marginal likelihood for a given model indicates a better fit of the data by that model and hence a greater probability that the model in question was the one that generated the data.
Directional statistics is the subdiscipline of statistics that deals with directions, axes or rotations in Rn. More generally, directional statistics deals with observations on compact Riemannian manifolds including the Stiefel manifold.
In probability and statistics, a circular distribution or polar distribution is a probability distribution of a random variable whose values are angles, usually taken to be in the range [0, 2π). A circular distribution is often a continuous probability distribution, and hence has a probability density, but such distributions can also be discrete, in which case they are called circular lattice distributions. Circular distributions can be used even when the variables concerned are not explicitly angles: the main consideration is that there is not usually any real distinction between events occurring at the lower or upper end of the range, and the division of the range could notionally be made at any point.
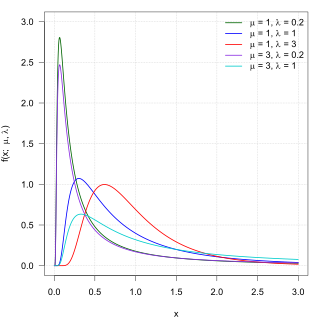
In probability theory, the inverse Gaussian distribution is a two-parameter family of continuous probability distributions with support on (0,∞).
A number of different Markov models of DNA sequence evolution have been proposed. These substitution models differ in terms of the parameters used to describe the rates at which one nucleotide replaces another during evolution. These models are frequently used in molecular phylogenetic analyses. In particular, they are used during the calculation of likelihood of a tree and they are used to estimate the evolutionary distance between sequences from the observed differences between the sequences.
In probability and statistics, a natural exponential family (NEF) is a class of probability distributions that is a special case of an exponential family (EF).
In probability and statistics, the Tweedie distributions are a family of probability distributions which include the purely continuous normal, gamma and inverse Gaussian distributions, the purely discrete scaled Poisson distribution, and the class of compound Poisson–gamma distributions which have positive mass at zero, but are otherwise continuous. Tweedie distributions are a special case of exponential dispersion models and are often used as distributions for generalized linear models.

In probability theory and statistics, the Conway–Maxwell–Poisson distribution is a discrete probability distribution named after Richard W. Conway, William L. Maxwell, and Siméon Denis Poisson that generalizes the Poisson distribution by adding a parameter to model overdispersion and underdispersion. It is a member of the exponential family, has the Poisson distribution and geometric distribution as special cases and the Bernoulli distribution as a limiting case.
In mathematics, a Lamé function, or ellipsoidal harmonic function, is a solution of Lamé's equation, a second-order ordinary differential equation. It was introduced in the paper. Lamé's equation appears in the method of separation of variables applied to the Laplace equation in elliptic coordinates. In some special cases solutions can be expressed in terms of polynomials called Lamé polynomials.
In probability theory, a Markov kernel is a map that in the general theory of Markov processes plays the role that the transition matrix does in the theory of Markov processes with a finite state space.
In probability theory, Isserlis' theorem or Wick's probability theorem is a formula that allows one to compute higher-order moments of the multivariate normal distribution in terms of its covariance matrix. It is named after Leon Isserlis.
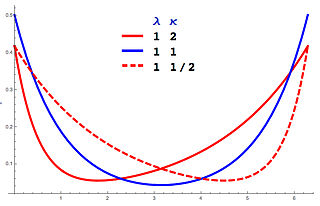
In probability theory and directional statistics, a wrapped asymmetric Laplace distribution is a wrapped probability distribution that results from the "wrapping" of the asymmetric Laplace distribution around the unit circle. For the symmetric case, the distribution becomes a wrapped Laplace distribution. The distribution of the ratio of two circular variates (Z) from two different wrapped exponential distributions will have a wrapped asymmetric Laplace distribution. These distributions find application in stochastic modelling of financial data.
In statistics, the complex Wishart distribution is a complex version of the Wishart distribution. It is the distribution of times the sample Hermitian covariance matrix of zero-mean independent Gaussian random variables. It has support for Hermitian positive definite matrices.









