
In computer science, binary search, also known as half-interval search, logarithmic search, or binary chop, is a search algorithm that finds the position of a target value within a sorted array. Binary search compares the target value to the middle element of the array. If they are not equal, the half in which the target cannot lie is eliminated and the search continues on the remaining half, again taking the middle element to compare to the target value, and repeating this until the target value is found. If the search ends with the remaining half being empty, the target is not in the array.
In computer science, a red–black tree is a kind of self-balancing binary search tree. Each node stores an extra bit representing "color", used to ensure that the tree remains balanced during insertions and deletions.
The point location problem is a fundamental topic of computational geometry. It finds applications in areas that deal with processing geometrical data: computer graphics, geographic information systems (GIS), motion planning, and computer aided design (CAD).

A quadtree is a tree data structure in which each internal node has exactly four children. Quadtrees are the two-dimensional analog of octrees and are most often used to partition a two-dimensional space by recursively subdividing it into four quadrants or regions. The data associated with a leaf cell varies by application, but the leaf cell represents a "unit of interesting spatial information".
In computer science, tree traversal is a form of graph traversal and refers to the process of visiting each node in a tree data structure, exactly once. Such traversals are classified by the order in which the nodes are visited. The following algorithms are described for a binary tree, but they may be generalized to other trees as well.
In computing, a persistent data structure or not ephemeral data structure is a data structure that always preserves the previous version of itself when it is modified. Such data structures are effectively immutable, as their operations do not (visibly) update the structure in-place, but instead always yield a new updated structure. The term was introduced in Driscoll, Sarnak, Sleator, and Tarjans' 1986 article.
In computer science, a disjoint-set data structure, also called a union–find data structure or merge–find set, is a data structure that stores a collection of disjoint (non-overlapping) sets. Equivalently, it stores a partition of a set into disjoint subsets. It provides operations for adding new sets, merging sets, and finding a representative member of a set. The last operation allows to find out efficiently if any two elements are in the same or different sets.
In computer science, an interval tree is a tree data structure to hold intervals. Specifically, it allows one to efficiently find all intervals that overlap with any given interval or point. It is often used for windowing queries, for instance, to find all roads on a computerized map inside a rectangular viewport, or to find all visible elements inside a three-dimensional scene. A similar data structure is the segment tree.

In graph theory, an m-ary tree is a rooted tree in which each node has no more than m children. A binary tree is the special case where m = 2, and a ternary tree is another case with m = 3 that limits its children to three.
In graph theory and computer science, the lowest common ancestor (LCA) of two nodes v and w in a tree or directed acyclic graph (DAG) T is the lowest node that has both v and w as descendants, where we define each node to be a descendant of itself.
A link/cut tree is a data structure for representing a forest, a set of rooted trees, and offers the following operations:

In computer science, a Cartesian tree is a binary tree derived from a sequence of numbers; it can be uniquely defined from the properties that it is heap-ordered and that a symmetric (in-order) traversal of the tree returns the original sequence. Introduced by Vuillemin (1980) in the context of geometric range searching data structures, Cartesian trees have also been used in the definition of the treap and randomized binary search tree data structures for binary search problems. The Cartesian tree for a sequence may be constructed in linear time using a stack-based algorithm for finding all nearest smaller values in a sequence.
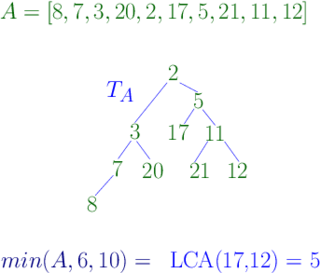
In computer science, a range minimum query (RMQ) solves the problem of finding the minimal value in a sub-array of an array of comparable objects. Range minimum queries have several use cases in computer science, such as the lowest common ancestor problem and the longest common prefix problem (LCP).

The Euler tour technique (ETT), named after Leonhard Euler, is a method in graph theory for representing trees. The tree is viewed as a directed graph that contains two directed edges for each edge in the tree. The tree can then be represented as a Eulerian circuit of the directed graph, known as the Euler tour representation (ETR) of the tree. The ETT allows for efficient, parallel computation of solutions to common problems in algorithmic graph theory. It was introduced by Tarjan and Vishkin in 1984.
In computer science, an x-fast trie is a data structure for storing integers from a bounded domain. It supports exact and predecessor or successor queries in time O(log log M), using O(n log M) space, where n is the number of stored values and M is the maximum value in the domain. The structure was proposed by Dan Willard in 1982, along with the more complicated y-fast trie, as a way to improve the space usage of van Emde Boas trees, while retaining the O(log log M) query time.
In data structures, a range query consists of preprocessing some input data into a data structure to efficiently answer any number of queries on any subset of the input. Particularly, there is a group of problems that have been extensively studied where the input is an array of unsorted numbers and a query consists of computing some function, such as the minimum, on a specific range of the array.
In computer science, the longest common prefix array is an auxiliary data structure to the suffix array. It stores the lengths of the longest common prefixes (LCPs) between all pairs of consecutive suffixes in a sorted suffix array.
Pointer jumping or path doubling is a design technique for parallel algorithms that operate on pointer structures, such as linked lists and directed graphs. Pointer jumping allows an algorithm to follow paths with a time complexity that is logarithmic with respect to the length of the longest path. It does this by "jumping" to the end of the path computed by neighbors.
In computer science, k-way merge algorithms or multiway merges are a specific type of sequence merge algorithms that specialize in taking in k sorted lists and merging them into a single sorted list. These merge algorithms generally refer to merge algorithms that take in a number of sorted lists greater than two. Two-way merges are also referred to as binary merges.
In computer science, a weak heap is a data structure for priority queues, combining features of the binary heap and binomial heap. It can be stored in an array as an implicit binary tree like a binary heap, and has the efficiency guarantees of binomial heaps.


