In computing, a compiler is a computer program that translates computer code written in one programming language into another language. The name "compiler" is primarily used for programs that translate source code from a high-level programming language to a low-level programming language to create an executable program.

Lisp is a family of programming languages with a long history and a distinctive, fully parenthesized prefix notation. Originally specified in the late 1950s, it is the second-oldest high-level programming language still in common use, after Fortran. Lisp has changed since its early days, and many dialects have existed over its history. Today, the best-known general-purpose Lisp dialects are Common Lisp, Scheme, Racket, and Clojure.

In computer programming, a macro is a rule or pattern that specifies how a certain input should be mapped to a replacement output. Applying a macro to an input is known as macro expansion. The input and output may be a sequence of lexical tokens or characters, or a syntax tree. Character macros are supported in software applications to make it easy to invoke common command sequences. Token and tree macros are supported in some programming languages to enable code reuse or to extend the language, sometimes for domain-specific languages.
In a computer language, a reserved word is a word that cannot be used as an identifier, such as the name of a variable, function, or label – it is "reserved from use". This is a syntactic definition, and a reserved word may have no user-defined meaning.

In computer science, an interpreter is a computer program that directly executes instructions written in a programming or scripting language, without requiring them previously to have been compiled into a machine language program. An interpreter generally uses one of the following strategies for program execution:
- Parse the source code and perform its behavior directly;
- Translate source code into some efficient intermediate representation or object code and immediately execute that;
- Explicitly execute stored precompiled bytecode made by a compiler and matched with the interpreter's virtual machine.
In computer science, a compiler-compiler or compiler generator is a programming tool that creates a parser, interpreter, or compiler from some form of formal description of a programming language and machine.
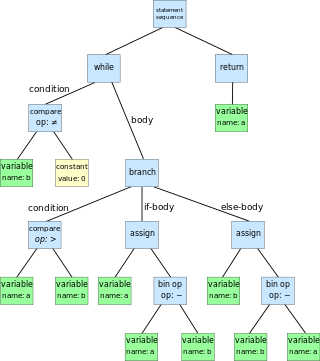
An abstract syntax tree (AST) is a data structure used in computer science to represent the structure of a program or code snippet. It is a tree representation of the abstract syntactic structure of text written in a formal language. Each node of the tree denotes a construct occurring in the text. It is sometimes called just a syntax tree.
The C preprocessor is the macro preprocessor for several computer programming languages, such as C, Objective-C, C++, and a variety of Fortran languages. The preprocessor provides inclusion of header files, macro expansions, conditional compilation, and line control.
A list comprehension is a syntactic construct available in some programming languages for creating a list based on existing lists. It follows the form of the mathematical set-builder notation as distinct from the use of map and filter functions.
In computer science, hygienic macros are macros whose expansion is guaranteed not to cause the accidental capture of identifiers. They are a feature of programming languages such as Scheme, Dylan, Rust, Nim, and Julia. The general problem of accidental capture was well known in the Lisp community before the introduction of hygienic macros. Macro writers would use language features that would generate unique identifiers or use obfuscated identifiers to avoid the problem. Hygienic macros are a programmatic solution to the capture problem that is integrated into the macro expander. The term "hygiene" was coined in Kohlbecker et al.'s 1986 paper that introduced hygienic macro expansion, inspired by terminology used in mathematics.
Metaprogramming is a computer programming technique in which computer programs have the ability to treat other programs as their data. It means that a program can be designed to read, generate, analyse, or transform other programs, and even modify itself, while running. In some cases, this allows programmers to minimize the number of lines of code to express a solution, in turn reducing development time. It also allows programs more flexibility to efficiently handle new situations with no recompiling.
A domain-specific language (DSL) is a computer language specialized to a particular application domain. This is in contrast to a general-purpose language (GPL), which is broadly applicable across domains. There are a wide variety of DSLs, ranging from widely used languages for common domains, such as HTML for web pages, down to languages used by only one or a few pieces of software, such as MUSH soft code. DSLs can be further subdivided by the kind of language, and include domain-specific markup languages, domain-specific modeling languages, and domain-specific programming languages. Special-purpose computer languages have always existed in the computer age, but the term "domain-specific language" has become more popular due to the rise of domain-specific modeling. Simpler DSLs, particularly ones used by a single application, are sometimes informally called mini-languages.
In computer programming, a directive or pragma is a language construct that specifies how a compiler should process its input. Depending on the programming language, directives may or may not be part of the grammar of the language and may vary from compiler to compiler. They can be processed by a preprocessor to specify compiler behavior, or function as a form of in-band parameterization.
Extensible programming is a term used in computer science to describe a style of computer programming that focuses on mechanisms to extend the programming language, compiler, and runtime system (environment). Extensible programming languages, supporting this style of programming, were an active area of work in the 1960s, but the movement was marginalized in the 1970s. Extensible programming has become a topic of renewed interest in the 21st century.

In computer science, the syntax of a computer language is the rules that define the combinations of symbols that are considered to be correctly structured statements or expressions in that language. This applies both to programming languages, where the document represents source code, and to markup languages, where the document represents data.
In computer programming, boilerplate code, or simply boilerplate, are sections of code that are repeated in multiple places with little to no variation. When using languages that are considered verbose, the programmer must write a lot of boilerplate code to accomplish only minor functionality.
This comparison of programming languages compares the features of language syntax (format) for over 50 computer programming languages.
In computer programming, a constant is a value that is not altered by the program during normal execution. When associated with an identifier, a constant is said to be "named," although the terms "constant" and "named constant" are often used interchangeably. This is contrasted with a variable, which is an identifier with a value that can be changed during normal execution. To simplify, constants' values remains, while the values of variables varies, hence both their names.
In C and C++ programming language terminology, a translation unit is the ultimate input to a C or C++ compiler from which an object file is generated. A translation unit roughly consists of a source file after it has been processed by the C preprocessor, meaning that header files listed in #include directives are literally included, sections of code within #ifndef may be included, and macros have been expanded.