
In computer science, binary search, also known as half-interval search, logarithmic search, or binary chop, is a search algorithm that finds the position of a target value within a sorted array. Binary search compares the target value to the middle element of the array. If they are not equal, the half in which the target cannot lie is eliminated and the search continues on the remaining half, again taking the middle element to compare to the target value, and repeating this until the target value is found. If the search ends with the remaining half being empty, the target is not in the array.

In computer science, a heap is a specialized tree-based data structure which is essentially an almost complete binary tree that satisfies the heap property: in a max heap, for any given node C, if P is a parent node of C, then the key of P is greater than or equal to the key of C. In a min heap, the key of P is less than or equal to the key of C. The node at the "top" of the heap is called the root node.

A binary heap is a heap data structure that takes the form of a binary tree. Binary heaps are a common way of implementing priority queues. The binary heap was introduced by J. W. J. Williams in 1964, as a data structure for heapsort.
In computer science, a selection algorithm is an algorithm for finding the th smallest value in a collection of ordered values, such as numbers. The value that it finds is called the th order statistic. Selection includes as special cases the problems of finding the minimum, median, and maximum element in the collection. Selection algorithms include quickselect, and the median of medians algorithm. When applied to a collection of values, these algorithms take linear time, as expressed using big O notation. For data that is already structured, faster algorithms may be possible; as an extreme case, selection in an already-sorted array takes time .
In computer science, a disjoint-set data structure, also called a union–find data structure or merge–find set, is a data structure that stores a collection of disjoint (non-overlapping) sets. Equivalently, it stores a partition of a set into disjoint subsets. It provides operations for adding new sets, merging sets, and finding a representative member of a set. The last operation makes it possible to find out efficiently if any two elements are in the same or different sets.
A B+ tree is an m-ary tree with a variable but often large number of children per node. A B+ tree consists of a root, internal nodes and leaves. The root may be either a leaf or a node with two or more children.
In computer science, an interval tree is a tree data structure to hold intervals. Specifically, it allows one to efficiently find all intervals that overlap with any given interval or point. It is often used for windowing queries, for instance, to find all roads on a computerized map inside a rectangular viewport, or to find all visible elements inside a three-dimensional scene. A similar data structure is the segment tree.

In computer science, a k-d tree is a space-partitioning data structure for organizing points in a k-dimensional space. k-d trees are a useful data structure for several applications, such as searches involving a multidimensional search key and creating point clouds. k-d trees are a special case of binary space partitioning trees.
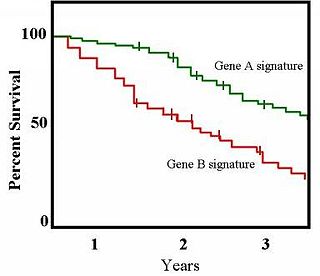
The Kaplan–Meier estimator, also known as the product limit estimator, is a non-parametric statistic used to estimate the survival function from lifetime data. In medical research, it is often used to measure the fraction of patients living for a certain amount of time after treatment. In other fields, Kaplan–Meier estimators may be used to measure the length of time people remain unemployed after a job loss, the time-to-failure of machine parts, or how long fleshy fruits remain on plants before they are removed by frugivores. The estimator is named after Edward L. Kaplan and Paul Meier, who each submitted similar manuscripts to the Journal of the American Statistical Association. The journal editor, John Tukey, convinced them to combine their work into one paper, which has been cited more than 61,800 times since its publication in 1958.
In graph theory and computer science, the lowest common ancestor (LCA) of two nodes v and w in a tree or directed acyclic graph (DAG) T is the lowest node that has both v and w as descendants, where we define each node to be a descendant of itself.
In statistics, the Kendall rank correlation coefficient, commonly referred to as Kendall's τ coefficient, is a statistic used to measure the ordinal association between two measured quantities. A τ test is a non-parametric hypothesis test for statistical dependence based on the τ coefficient. It is a measure of rank correlation: the similarity of the orderings of the data when ranked by each of the quantities. It is named after Maurice Kendall, who developed it in 1938, though Gustav Fechner had proposed a similar measure in the context of time series in 1897.
In computer science, fractional cascading is a technique to speed up a sequence of binary searches for the same value in a sequence of related data structures. The first binary search in the sequence takes a logarithmic amount of time, as is standard for binary searches, but successive searches in the sequence are faster. The original version of fractional cascading, introduced in two papers by Chazelle and Guibas in 1986, combined the idea of cascading, originating in range searching data structures of Lueker (1978) and Willard (1978), with the idea of fractional sampling, which originated in Chazelle (1983). Later authors introduced more complex forms of fractional cascading that allow the data structure to be maintained as the data changes by a sequence of discrete insertion and deletion events.
In computer science, a succinct data structure is a data structure which uses an amount of space that is "close" to the information-theoretic lower bound, but still allows for efficient query operations. The concept was originally introduced by Jacobson to encode bit vectors, (unlabeled) trees, and planar graphs. Unlike general lossless data compression algorithms, succinct data structures retain the ability to use them in-place, without decompressing them first. A related notion is that of a compressed data structure, in which the size of the data structure depends upon the particular data being represented.

A Fenwick tree or binary indexed tree(BIT) is a data structure that can efficiently update elements and calculate prefix sums in a table of numbers.
In machine learning, a Ranking SVM is a variant of the support vector machine algorithm, which is used to solve certain ranking problems. The ranking SVM algorithm was published by Thorsten Joachims in 2002. The original purpose of the algorithm was to improve the performance of an internet search engine. However, it was found that Ranking SVM also can be used to solve other problems such as Rank SIFT.
In computer science, the longest common prefix array is an auxiliary data structure to the suffix array. It stores the lengths of the longest common prefixes (LCPs) between all pairs of consecutive suffixes in a sorted suffix array.
In data structures, the range mode query problem asks to build a data structure on some input data to efficiently answer queries asking for the mode of any consecutive subset of the input.

In computer science, a finger search on a data structure is an extension of any search operation that structure supports, where a reference (finger) to an element in the data structure is given along with the query. While the search time for an element is most frequently expressed as a function of the number of elements in a data structure, finger search times are a function of the distance between the element and the finger.
In computing, a distance oracle (DO) is a data structure for calculating distances between vertices in a graph.
The PH-tree is a tree data structure used for spatial indexing of multi-dimensional data (keys) such as geographical coordinates, points, feature vectors, rectangles or bounding boxes. The PH-tree is space partitioning index with a structure similar to that of a quadtree or octree. However, unlike quadtrees, it uses a splitting policy based on tries and similar to Crit bit trees that is based on the bit-representation of the keys. The bit-based splitting policy, when combined with the use of different internal representations for nodes, provides scalability with high-dimensional data. The bit-representation splitting policy also imposes a maximum depth, thus avoiding degenerated trees and the need for rebalancing.


































































































































